python 中的多线程
本文主要讲述了 python 中多线程的使用、线程锁以及多线程在 python 中是否能够提高效率。
多线程的概念
进程的相信大家都听说过,而线程可以理解为比进程更小一级的概念,一个进程内至少有一个线程, 如果有多个线程,那么他们就共享进程的资源,共同完成进程的任务。
使用多线程一般有两个不同的目的:
一是把程序细分成几个功能相对独立的模块,防止其中一个功能模块阻塞导致整个程序假死(GUI 程序是典型)
另一个就是提高运行效率,比如多个核同时跑,或者单核里面,某个线程进行 IO 操作时,另一个线程可以同时执行。具体可以参考这篇文章
相比进程,线程有以下优点
- 创建和销毁的代价比进程要小得多,尤其是在 windows 下,可以参考这个回答。而且线程间彼此切换所需的时间也远远小于进程间切换所需要的时间
- 线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行。而由于同一进程下的线程之间共享数据空间,降低了通信的开销。
除了优点, 线程间方便的通信机制源于线程间数据的共享,同时也带来了其他问题,如需要保护变量不能同时被两个线程所修改,这也需要一定的开销,而且需要开发者处理好这个调度。
python 中的多线程
python 中提供了两个模块实现多线程,分别是thread和threading,thread是比较低级的模块, 而threading在其基础上封装了其他许多高级特性,故本文主要讲述threading模块的使用,若要了解thread模块的使用,请参考官方文档。
创建进程有两种方式,分别是继承 threading.Thread 类创建自己的线程子类和将需要线程执行的函数传入线程构造函数中。下面分别讲述
继承 threading.Thread 类
继承 threading.Thread 类只能重写(override)__init__函数和run()函数,__init__函数就是构造函数,run()函数就是创建线程后线程需要执行的任务。下面是一个简单的 demo1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# encoding:utf-8
import threading
import time
import random
class sleepThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
print self.name+ ' is created!'
def run(self):
randomTime = random.randint(1,9) # 生成 1~9的随机整数
time.sleep(randomTime)
print self.name+ ' slept for '+str(randomTime)+' seconds'
if __name__ == '__main__':
threads = []
for i in range(5): # 创建5个进程
th = sleepThread()
threads.append(th)
th.start()
for t in threads:
t.join()
print 'all threads finished'
在上面的例子中,我们编写了自己的线程类sleepThread,然后创建了 5 个线程,用start()启动了各个线程,start()实际上是执行了线程类的run()函数。这时输出如下所示:
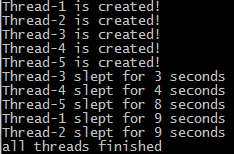
其中,默认线程的名称是Thread-i,i 就是创建的第 i 个线程。join()函数的作用是等待线程执行完成再执行下面任务, 实际的应用场景比如说进程要合并多个线程的处理结果,那么这时候join()函数就必不可少了。假如没有join()函数,即主函数改成下面的样子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125if __name__ == '__main__':
for i in range(5): # 创建5个进程
th = sleepThread()
th.start()
print 'all threads finished'
```
那么输出就像下面所示:
![][5]
那为什么不在`thread.start()`后执行join()呢?即主函数改成以下样子。
```py
if __name__ == '__main__':
for i in range(5): # 创建5个进程
th = sleepThread()
th.start()
th.join()
print 'all threads finished'
```
这样输出的结果就像下面一样:
![][6]
原因是线程join()后会阻塞后面线程的创建,导致线程无法并行,这样多线程就没有意义了。
### 将需要线程执行的函数传入线程构造函数中
上面是线程的一种创建方式,实现上面相同功能的另外一种创建方式如下:
```py
def sleepThread(threadName):
randomTime = random.randint(1,9) # 生成 1~9的随机整数
time.sleep(randomTime)
print threadName+ ' slept for '+str(randomTime)+' seconds'
if __name__ == '__main__':
threads = []
for i in range(5):
th = threading.Thread(target=sleepThread,args=('Thread-'+str(i),))
threads.append(th)
th.start()
for t in threads:
t.join()
print 'all threads finished'
```
利用了`threading.Thread`自身的构造函数,传入的target参数作为线程的`run`函数,args参数则为传入的run函数的参数。
输出结果如下所示:
![][7]
线程还有比较常用的方法比如说setdaemon(True),字面上的意思是设为守护线程,但是这个守护线程跟守护进程有很大的区别,**实际上setdaemon(True)的作用是保证主线程(就是任何进程最开始的那个线程)退出时,派生出来的线程也必须退出。**详细例子见http://stackoverflow.com/questions/5127401/setdaemon-function-in-thread
## 线程锁
因为多线程共享一个进程内的资源,所以**多个线程同时修改同一个变量时会发生冲突。这时候就需要线程锁**了。比如说下面这段代码;
```py
count = 10
def modifyThread(num):
global count
for i in range(1000):
count -= num
count += num
if __name__ == '__main__':
threads = []
print 'before modifying, count=%s '%count
for i in range(5):
th = threading.Thread(target=modifyThread,args=(i,))
threads.append(th)
th.start()
for t in threads:
t.join()
print 'after modifying, count=%s '%count
```
执行的的时候每次输出结果都不一样,例如下图:
![][8]
这是因为count是被多个线程同时修改了,解决方法就是利用线程锁`threading.Lock()`,每次需要修改count时先获取线程锁,修改完再释放。实例代码如下所示:
```py
count = 10
def modifyThread(num):
global count
threadLock.acquire()
try:
for i in range(1000):
count -= num
count += num
finally:
threadLock.release()
if __name__ == '__main__':
threads = []
threadLock = threading.Lock()
print 'before modifying, count=%s '%count
for i in range(5):
th = threading.Thread(target=modifyThread,args=(i,))
threads.append(th)
th.start()
for t in threads:
t.join()
print 'after modifying, count=%s '%count
```
当多个线程同时执行threadLock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
在其中一个线程获取了线程锁(threadLock.acquire())后,其他线程便无法修改count,但是修改完后一定要记得释放线程锁(threadLock.release()),否则其他线程会一直处于blocked的状态,上面采用了`try-finally `保证锁一定被释放。除了`try-finally `,还可通过 `with` 语句实现锁的自动获取和释放, 也就是说上面的 `modifyThread` 函数可以写成下面的形式
```py
def modifyThread(num):
global count
with threadLock:
for i in range(1000):
count -= num
count += num
通过加锁的方法修改 count, 最终得到的 count 的值不变。
线程锁 (Lock) 是线程同步的一种方式,除此之外,还有 RLocks, Semaphores, Condition, Events 和 Queues,具体可参考官方文档和 Python threads synchronization: Locks, RLocks, Semaphores, Conditions, Events and Queues
多线程是否提高了效率
常常会听到有人说,因为 python 多线程只能使用一个核,所以多线程实际上并没有提高效率。这句话可以说一半正确,一半不正确。原因如下:
python 多线程只能使用一个核这句话针对部分 python 解析器如 CPython 等是正确的,而且是相对与 Java、C++ 那些一个线程就可以占一个核的程序而言。python 的官方文档描述如下:
>In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe
原因是 python 的解析器(如 CPython)因为内存管理问题设计了一个 GIL(全局解析锁),GIL 保证了任何时候都只能有一个线程执行其字节码。这就限制了同一进程内同一时间只能有一个线程在执行其字节码,也就是说无论一个进程无论创建多少线程都只能使用一个核。
而且,这个 GIL 也只在 CPython 等解释器有,其他的如 Jython 或 IronPython 中没有 GIL,多线程可以利用多个核。另外,即使是 CPython 解释器,也可通过多进程来达到利用多个核的目的。
那第二句话多线程实际上并没有提高效率是否正确?可以说也是部分正确,实际上针对 CPU 密集型的 python 进程,多线程没有提高效率,而针对 IO 密集型的 python 进程会提高效率。
从上面的解释我们知道,GIL 是限制了多线程并发执行的一个关键因素,而 GIL 仅仅是限制了同一时间同一进程只能有一个线程执行字节码,执行字节码是在 CPU 中的,对于 CPU 密集型的多线程,会一直占据着 CPU 导致其效果跟单线程一样。
而对于 IO 密集型的多线程,线程的执行时间会较多地消耗在 IO 上,因而 CPU 可供多线程轮流使用。比如说我曾用 python 爬取几个输入法的词库的,多线程比单线程要快了好几倍,原因就是爬虫属于 IO 密集型的任务,线程执行字节码所需的时间很短,而把大部分时间放在了下载和存储在本地上,线程执行完字节码后会释放 GIL,从而其他线程也能够执行其字节码。从而在总体上提高了下载效率。
文章为博主个人理解总结,如有错误,欢迎指出交流。
参考:
threading — Higher-level threading interface
GlobalInterpreterLock
多线程