机器学习基石 -- 学习的可行性
本文是《机器学习基石》第四讲 Feasibility of Learning 的课程笔记。通过 Hoeffding 不等式,引出了机器学习中学习的可行性。
刚刚接触机器学习的时候,往往会被各种机器学习算法搞得昏头涨脑,却往往忽略了一个问题:那就是机器学习中的 “学习” 二字到底指的是什么,或者说机器为什么能够学习,到底学到了什么东西?
要回答这个问题,首先要确认一个大前提:数据集(包括训练集和测试集)是从相同分布中产生的,也就是说产生数据的环境应该是一致的,否则假如训练集与数据集的产生方式不一样,那么从训练集中是不可能学习到训练集中相关的知识的
有了上面这个大前提,从概率论的角度来讲,机器学习学的就是这个概率分布,;或者说是模式识别中的模式(pattern);然后用学习到的概率分布去预测未见过但是也是在这个概率分布下产生的样本,这样一来,便称机器能够 “学习” 了。
下面的内容便是将这一过程通过数学来严谨化
Hoeffding 不等式
为了引入 Hoeffding 不等式,首先来看一下概率论中一个简单的例子:假如一个罐子中有绿色和橙色两种弹珠,现在想知道罐子中橙色弹珠的比例,该怎么做?
最直观的方法就是将罐子中所有的弹珠分类并计数,然后计算橙色弹珠的比例。但是当罐子中的弹珠数目变得很大的时候,在实际中显然是无法将所有弹珠都数一遍。
这时便需要进行抽样并从抽出的样本(sample)中估计橙色弹珠的比例,但是抽样一定会带来一定的误差的,而且直观上来看,抽样的样本数目越多,误差越小。而 Hoeffding 不等式就是描述这个误差跟抽样数目的关系,假如橙色弹珠的真实比例为 \(\mu\) , 而从样本中估计出的比例为 \(\nu\), 样本大小为 \(N\), 则对应的 Hoeffding 不等式如下
\[\begin{align} p(|\nu - \mu| \gt \epsilon) \le 2\exp(-2\epsilon^2N) \end{align}\]
上式中的 \(\epsilon\) 表示允许的误差范围
从 Hoeffding 不等式到机器学习
假如将上面的罐子中的一个弹珠抽象为机器学习中的一个样本,考虑一个二分类问题,绿色弹珠表示样本标签与我们的模型 \(h\) 预测出的标签一致,而橙色弹珠则表示样本标签与预测标签不一致。则橙色弹珠的比例就是模型 \(h\) 的错误率。同时将模型 \(h\) 在全部弹珠中的错误率记为 \(E_{out}(h)\), 而在样本中的错误率记为 \(E_{in}(h)\),则根据 Hoeffding 不等式有
\[\begin{align} p(|E_{in}(h) - E_{out}(h)| \gt \epsilon) \le 2\exp(-2\epsilon^2N) \end{align}\]
也就是说,训练样本的数目越大,\(E_{in}(h)\) 和 \(E_{out}(h)\), 也就是训练误差和泛化误差越接近。
这一等式实际上代表了 PAC (probaly approximately correct) 学习理论中的 probably 部分,PAC 理论简单描述如下 (摘自 Wikipedia)
In this framework, the learner receives samples and must select a generalization function (called the hypothesis) from a certain class of possible functions. The goal is that, with high probability (the "probably" part), the selected function will have low generalization error (the "approximately correct" part).
上面的 Hoeffding 不等式只是说明了训练误差和泛化误差可以很接近,但是这一接近必须要在训练误差也就是 \(E_{in}(h)\) 很小的情况下才有意义,否则大的训练误差就有大的范化误差,而大的范化误差的模型实际上是没有意义的。而小的训练误差对应到 PAC 中的 AC (approximately correct) 部分。
从一个 hyposthesis 到多个 hypothesis
上面的 Hoeffding 不等式描述的是一个 hypothesis 也就是一个 \(h\) 的情况,但是实际中往往有多个 hypothesis 可选,这个时候的 Hoeffding 不等式又会变成怎样?
首先回顾一下单个 \(h\) 的 Hoeffding 不等式,它告诉我们下面这个事情发生的概率很大:\(h\) 在抽取的样本上得到的样本误差(也就是训练误差)跟 \(h\) 的总体误差(也就是泛化误差)很接近。
从另一个角度来讲,也就是说还是有很小的概率抽出一些样本,使得 \(h\) 在样本上得到的误差与其在总体上得到的误差相差很大(实际上就是抽出的样本不能很好反映总体),讲义中将这部分的 sample 称为 bad data,就是使得 \(h\) 的 \(E_{in}(h)\) 很小,\(E_{out}(h)\) 很大的样本。如下图所示,如果进行多次抽样,那么肯定有一些样本会导致 \(E_{in}(h)\) 和 \(E_{out}(h)\) 的差距较大。
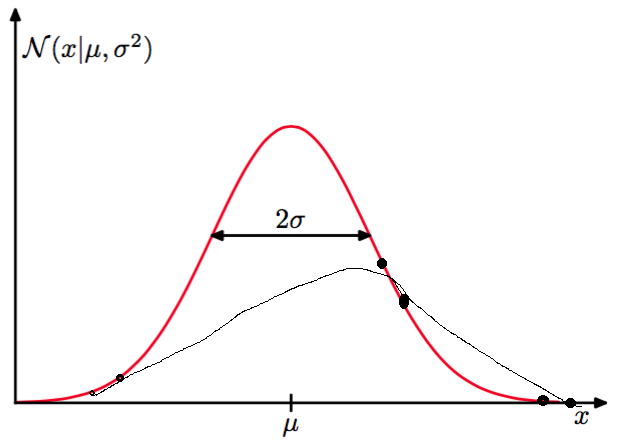
注:这里 \(E_{in}(h)\) 很小,\(E_{out}(h)\) 很大其实已经是我们常听到的过拟合现象,影响过拟合的因素有很多,而抽样的数据的分布是否能够代表整体数据的分布则是其中一个因素。下面是一个简单的例子:对于一个高斯分布产生的数据,如果抽样数据是图中的黑色点,那么拟合出来的曲线可能是图中的黑线,也就是说假如抽样数据的分布如果跟原始数据分布不一致,我们的模型拟合了抽样的数据,对于原始数据而言,自然没有预测能力,也就是 \(E_{in}(h)\) 很小,\(E_{out}(h)\) 很大,可以说是过拟合了抽样的数据。
回到讨论的话题,如果对于 \(M\) 个 hypothesis 呢?上图可以改为如下形式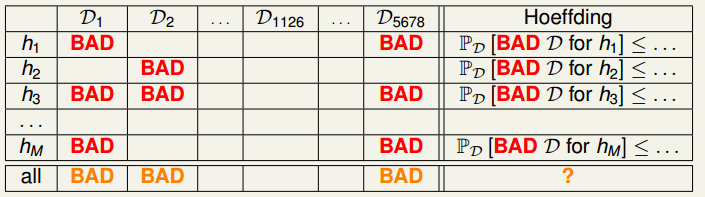
在上图中,由于每个 hypothesis 都不同,因此对各个 hypothesis 而言其 bad data 也不同,只有当样本对各个 hypothesis 而言都不是 bad 的时候,才不会泛化误差和训练误差差距很大的情况。在有 \(M\) 个 hypothesis 的时候,用 Hoeffding 不等式表示选择了 bad data 的概率为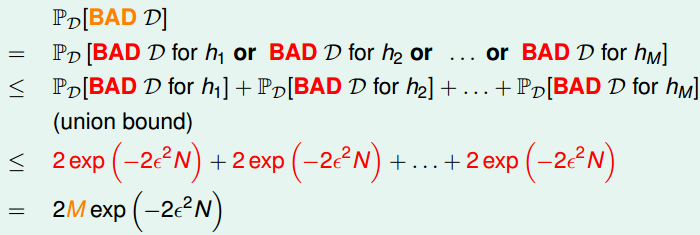
上面的不等式表明,对于有限多个 hypothesis 而言,\(E_{in}(h) \approx E_{out}(h)\) 还是 PAC 的,只是两者误差的 upper bound 变大了,但是数据量 \(N\) 的增大能够抵消这一影响。
在上面的前提下,在有多个 hypothesis 的情况下,只需要选择 \(E_{in}(h)\) 小的,就能拿保证 \(E_{out}(h)\) 也是小的,也就是学习是可行的。
小结
本文主要是通过 Hoeffding 不等式证明了当模型的所有 hypothesis 的个数 \(M\) 为有限个时,样本数目 \(N\) 足够大时,就能够保证泛化误差 \(E_{out}(h)\) 和训练误差 \(E_{in}(h)\) 很接近。
这时候只要找到一个 hypothesis 使得 \(E_{in}(h)\) 很小,那么 \(E_{out}(h)\) 也会很小,从而达到学习的目的。
当然有一个大前提就是训练样本和测试样本必须要在同一分布下产生,否则学习无从谈起。
上面的内容可通过下图进行描述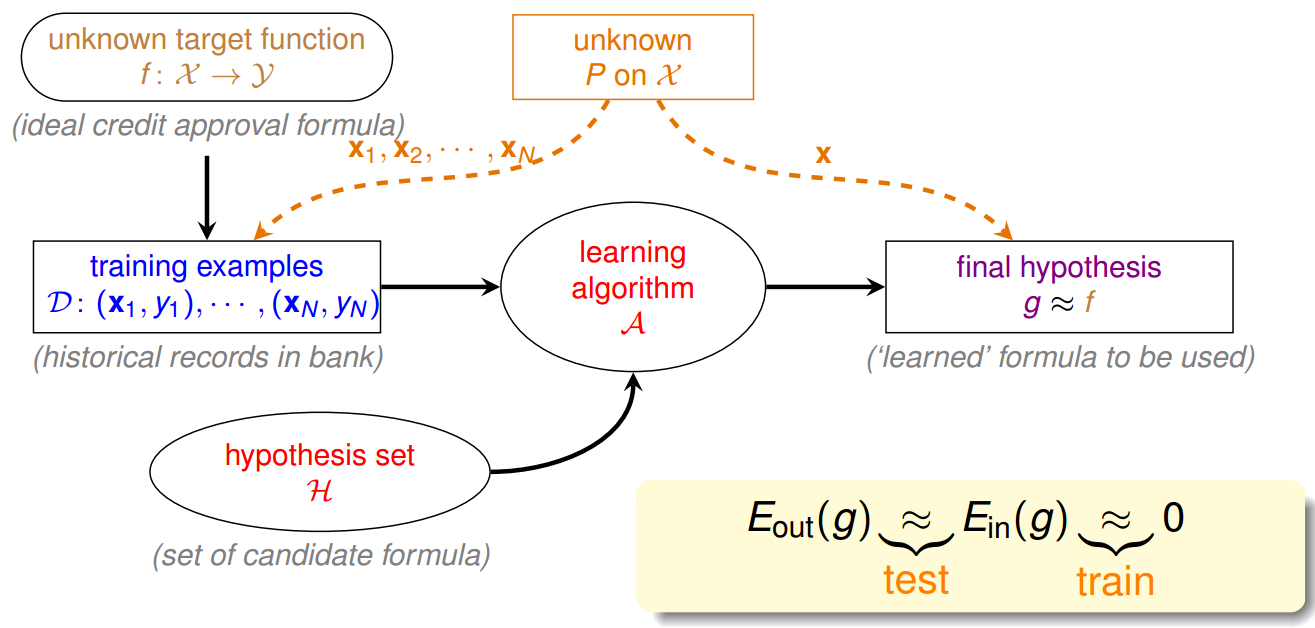
但是还有一个问题,就是实际中某个模型空间里的 hypothesis 往往是无限多个的,这种情况下又该如何通过数学描述?这部分内容将在后面讲述。