如何用数据武装运营工作
这篇文章的内容主要来源于 该知乎live,主要介绍了利用数据获取了用户后如何运营,从而能够尽可能长时间地留存用户,介绍了这方面的三个具体方法:建立用户转化漏斗、通过多维报表找到问题和建立实验框架。
本文主要关注下图左半部分,利用了别人的数据和流量获取了用户后该怎么运营以留存用户。
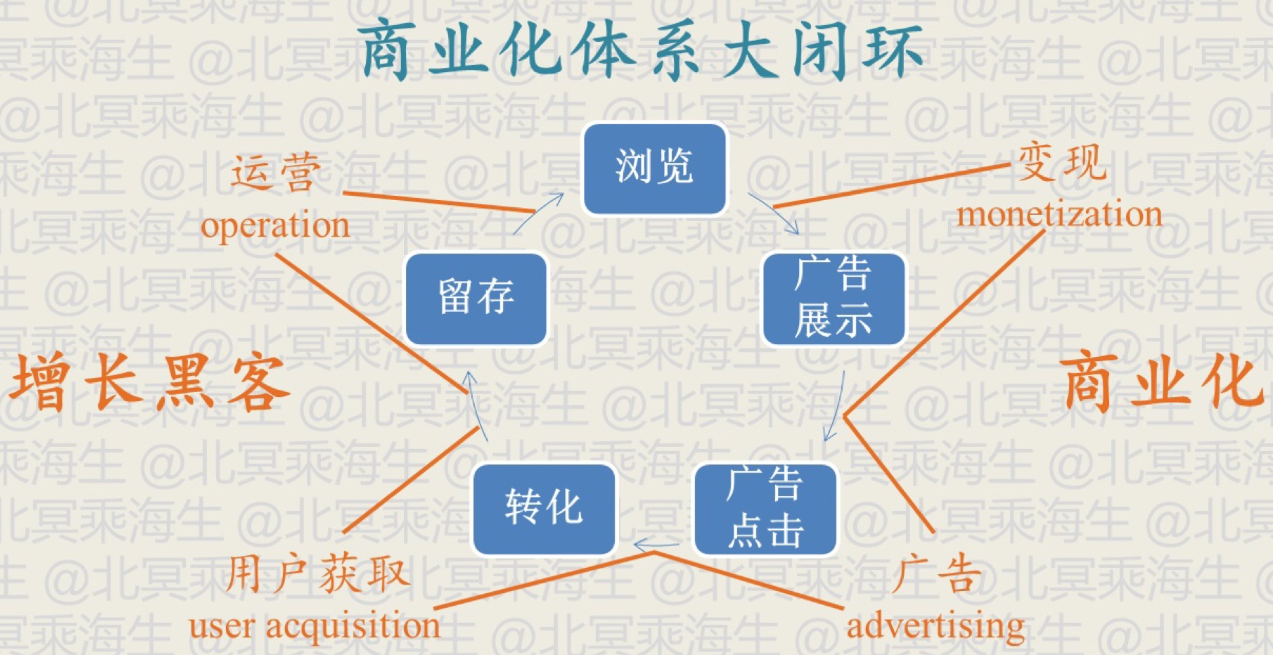
为了达到这个目标,有三个重要的方法
- 建立用户转化漏斗:总体的数据发生变化时,到底是哪个环节起了作用。
- 通过多维报表找到问题:经过上一步确定某个环节出现问题后,对这一个环节需要更细致的分解,这是需要从各个维度去分析这个环节中出现问题的原因。
- 建立灵活的实验框架:上面两步是被动地发现问题,实际中更要主动的探索新方案,新的实验框架有利于测试的快速迭代
建立用户转化漏斗
把商业目标转化为用户转化的一系列步骤,下面是两个具体例子

每一步都有一定的损失,且需要关注的点是前后两步的用户的比率,因为通过比率更容易看到具体的变化
漏斗设计的原则与作用:整个漏斗过程用于优化一个唯一的目标,并将该目标分解为若干比率的乘积,便于发现问题并优化,下面是一个优化总用户时长的例子
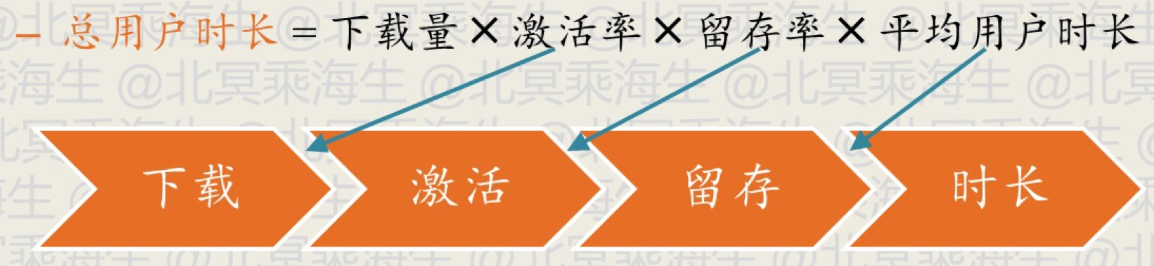
设计用户漏斗需要涉及到具体的度量指标,下面是移动应用中一些常见的度量指标
转化率/激活率:激活数和点击数的比 留存率:某日激活的用户中,经过一段时间还活跃的用户所长比例;根据设定的时间不同可分为次日留存、七日留存、月留存等 活跃用户:活跃的独立用户数,根据时间的不同可分为日活跃用户(DAU)、月活跃用户(MAU) 用户时长:每个活跃用户平均消耗的时间
对于网站分析,其优化目标本质上跟移动的应用一样,就是尽可能吸引并留存更多的用户,但是由于两者具体提供服务的不同,两者的度量指标也有不同的叫法,下面是网站分析中常见的度量
UV (User View):独立访客数 PV (Page View):所有浏览量 页面停留时长:页面浏览时间 跳出率 (Bounce Rate):指单页会话(用户打开了网站上的一个网页,然后就退出了网站)次数在所有会话次数中所占的比例,也就是用户在您网站上仅查看一个网页的会话次数所占的百分比 网站热力图:热力图是指以特殊高亮的形式显示访客热衷的页面区域和访客所在的地理区域的图示,简单来说就是分析出一个页面内各个部位的点击情况,如下是一个热力点击图
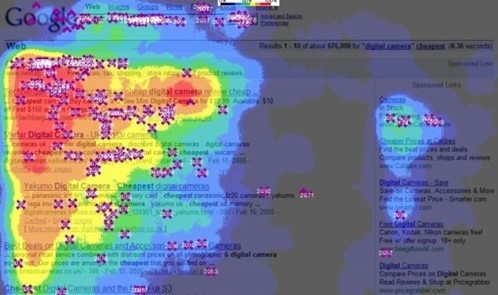
关于跳出率,高跳出率有时是网站本身的属性决定的,这时候就没必要做更多的优化, Google Analytics 描述如下:
高跳出率不是件好事?
这需要视情况而定。
如果您网站的成功取决于用户是否查看多个网页,那么高跳出率就不是一件好事。例如,如果您的首页是通往您网站的其他部分(例如新闻报道、产品页、结帐流程)的入口,而大部分用户仅查看您的首页,那么您一定不希望跳出率处于较高的水平。
另一方面,如果您拥有类似博客那样的单页网站,或提供预计会产生单页会话的其他类型的内容,则高跳出率完全属于正常现象。
分析工具
网站分析工具:Google Analytics、百度统计、CNZZ 应用分析工具:TalkingData、友盟+、Flurry、Google Analytics 应用归因工具:Appsflyer、Tune、Adjust、TalkingData
分析工具是用于分析已有用户的行为,而归因工具是用于分析用户的来源。
因此,总结上面的过程为:建立漏斗并利用分析工具将漏斗的每一步的数据找出来
下面是一个通过漏斗分析的页游的例子


通过这样的步骤可以有目的地去排查具体的问题,如上面的例子中可能是程序在 chrome 浏览器上的不兼容导致了注册率的较低。
通过多维报表找到问题
上面的例子中统计各个浏览器的注册率时已经涉及到了多维报表查询的问题,因为除了从浏览器,还可能从地域、时间段、时间段和浏览器组合等其他维度去统计,这时候就需要一个灵活的查询统计工具来提供这样的多维度报表,这个工具就是数据仓库(Data Warehouse)
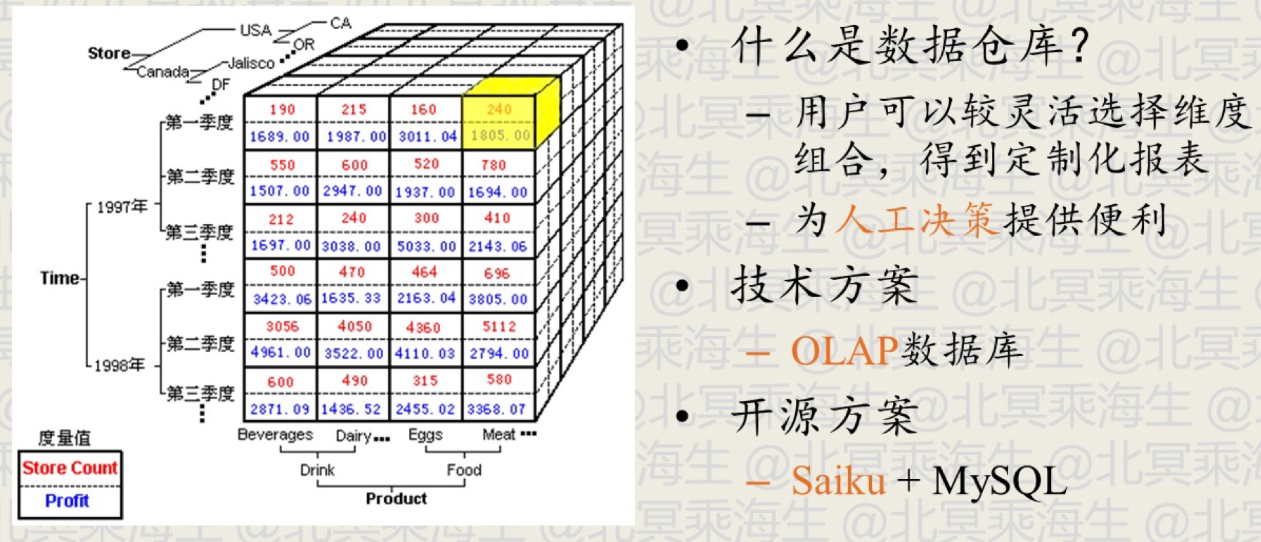
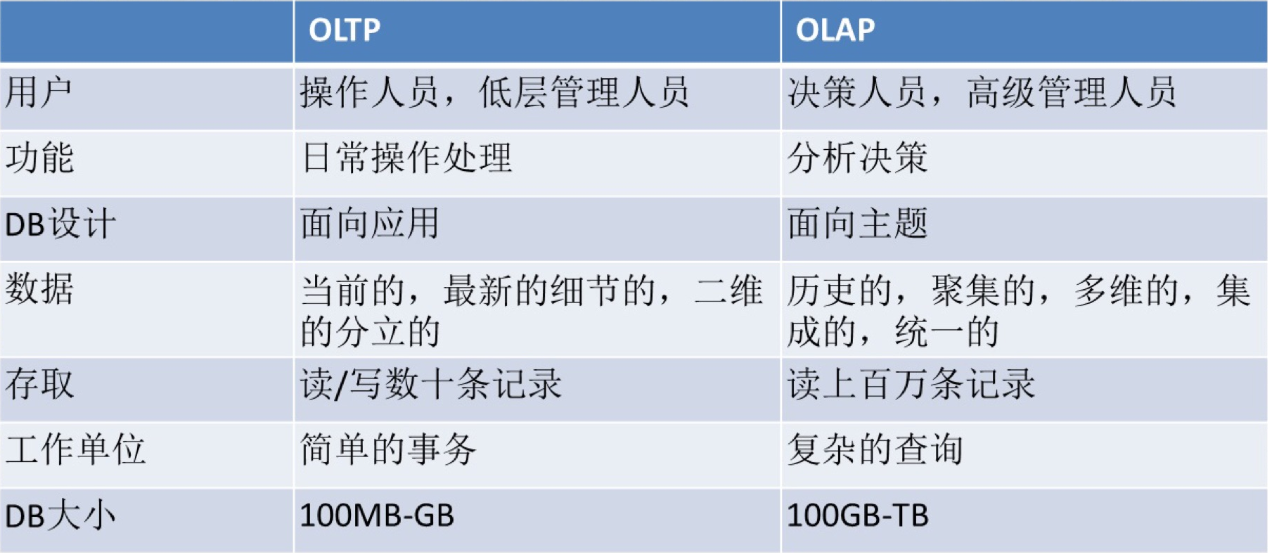
OLAP (Online Analytical Processing) 和 OLTP(Online Transaction Processing)
软件:Saiku、Tableau
上面的流程:
一个商业目标 -> 建立一个转化漏斗 -> 用分析工具在应用或网站埋点 -> 分析工具得到的数据建立数据仓库 -> 用数据仓库做精细查询
建立灵活的实验框架
实验框架其实就是常听说的 A/B 测试,就是把用户分成两部分(两部分的量不一定相等),然后对这两部分的用户分别采用不同的方案,比较哪种的效果好,从而采取效果好的那个方案。这里的不同方案的不同点就是我们需要验证的产品的特性,且往往是单变量的,也就是验证某个新的特性与旧特性哪个好时需要保持其他环境一样,而仅仅改变这个特性。在这个过程中需要注意划分的用户要有代表性,也就是两部分用户的分布情况应该一致(如年龄等)
A/B 测试中的一个重要方法是分层实验框架,其目的是为了能够在同样的流量情况下容纳更多的 A/B 测试,下面以一个简单的例子讲解
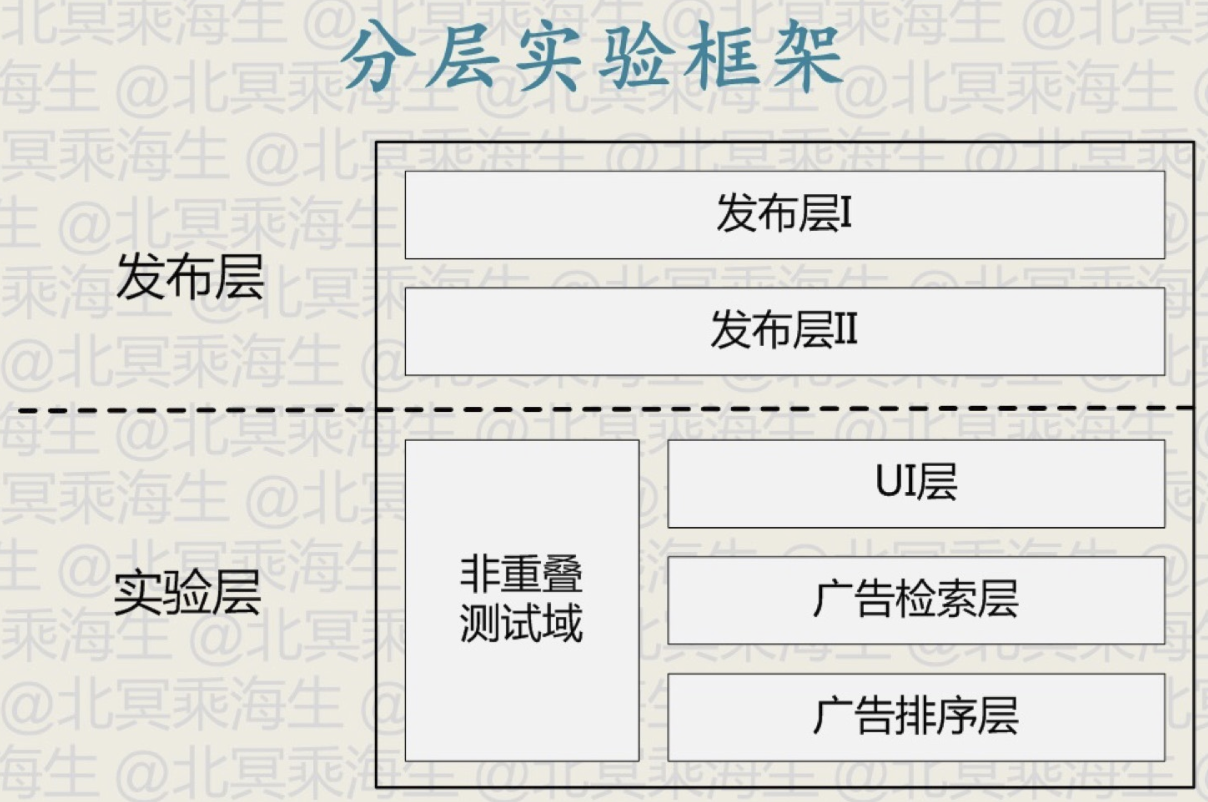
上图所示的实验层中,在UI层,广告检索层和广告排序层均有 A/B 测试的需求,假如要测试UI层的一个新特征,同时也要测试广告检索层的一个新特征,当需要同时进行这两个测试时,必须要确保UI层的流量划分不会影响到广告检索层的测试,也就是说在广告检索层中划分的两部分流量中,只存在着广告检索层的特征的差异。因此如果同时在两个层进行AB测试,需要将流量划分为四份,分别是 UI层原特征+广告检索层原特征、UI层原特征+广告检索层新特征、UI层新特征+广告检索层原特征、UI层新特征+广告检索层新特征。即需要测试的特征数为 \(n\) 时,需要划分的流量数为 \(2^n\), 显然这样的增长级数带来了流量分割的困难。分层实验框架就是解决这个问题的。
具体的做法就是采用正交的哈希函数来为每一层进行流量划分,正交的哈希函数避免了不同层间的干扰问题。如对于上面的问题,采用两个相互正交的哈希函数,分别在UI层和广告检索层将流量划分为两部分,因为两个哈希函数是正交的,因此在UI层所划分的两部分流量U1和U2中,U1所包含的广告检索层的原特征流量和U2所包含的广告检索层的原特征流量比例相等,同时新特征的比例也相等,这样就避免了上面的指数级增长的划分方式。更详细的信息可参考这篇文章 Overlapping experiment infrastructure: more, better, faster experimentation
上图中的非重叠测试域指的是测试的特性贯穿了三个层,就是同时测试三个层的特性组合带来的效果,这时候就用不上分层实验框架了。
上面这种采用正交的哈希函数来为每一层进行流量划分思路同样可用在灰度发布中,进行分层的灰度发布测试。
通过 A/B 测试能够将目前的产品的特性调到最优,但是需要注意的是 A/B 测试并不是万能的,因为过度依赖于数据会丧失对关键创新的把握,这里有一句很形象的话:汽车无法从跑得更快的马进化而来,也就是无论我们利用 A/B 测试把马(现有的产品)训练成跑得更快,依然是没法比得过汽车(更有创意的产品)。