stacking 的基本思想及代码实现
本文主要介绍机器学习中的一种集成学习的方法 stacking,本文首先介绍 stacking 这种方法的思想,然后提供一种实现 stacking 的思路,能够简单地拓展 stacking 中的基本模型。
stacking 的基本思想
stacking 就是将一系列模型(也称基模型)的输出结果作为新特征输入到其他模型,这种方法由于实现了模型的层叠,即第一层的模型输出作为第二层模型的输入,第二层模型的输出作为第三层模型的输入,依次类推,最后一层模型输出的结果作为最终结果。本文会以两层的 stacking 为例进行说明。
stacking 的思想也很好理解,这里以论文审稿为例,首先是三个审稿人分别对论文进行审稿,然后分别返回审稿意见给总编辑,总编辑会结合审稿人的意见给出最终的判断,即是否录用。对应于 stacking,这里的三个审稿人就是第一层的模型,其输出(审稿人意见)会作为第二层模型(总编辑)的输入,然后第二层模型会给出最终的结果。
stacking 的思想很好理解,但是在实现时需要注意不能有泄漏(leak)的情况,也就是说对于训练样本中的每一条数据,基模型输出其结果时并不能用这条数据来训练。否则就是用这条数据来训练,同时用这条数据来测试,这样会造成最终预测时的过拟合现象,即经过 stacking 后在训练集上进行验证时效果很好,但是在测试集上效果很差。
为了解决这个泄漏的问题,需要通过 K-Fold 方法分别输出各部分样本的结果,这里以 5-Fold 为例,具体步骤如下
- 将数据划分为 5 部分,每次用其中 1 部分做验证集,其余 4 部分做训练集,则共可训练出 5 个模型
- 对于训练集,每次训练出一个模型时,通过该模型对没有用来训练的验证集进行预测,将预测结果作为验证集对应的样本的第二层输入,则依次遍历 5 次后,每个训练样本都可得到其输出结果作为第二层模型的输入
- 对于测试集,每次训练出一个模型时,都用这个模型对其进行预测,则最终测试集的每个样本都会有 5 个输出结果,对这些结果取平均作为该样本的第二层输入
上述过程图示如下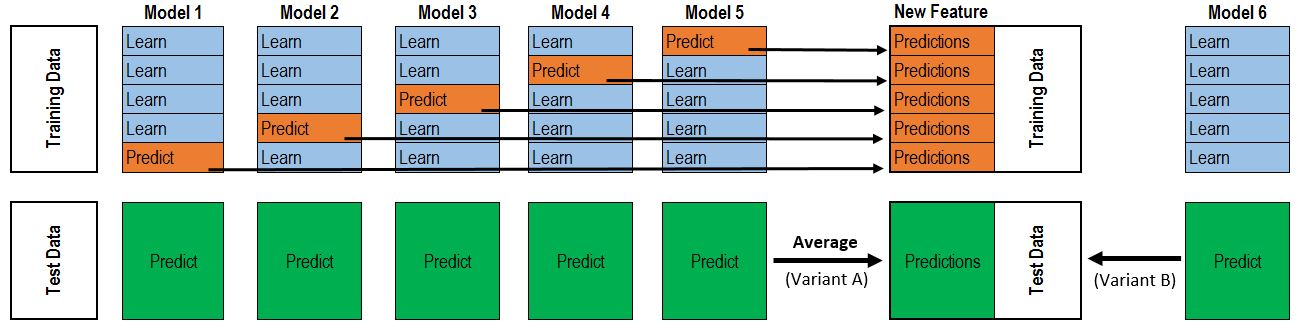
除此之外,用 stacking 或者说 ensemble 这一类方法时还需要注意以下两点:
- Base Model 之间的相关性要尽可能的小,从而能够互补模型间的优势
- Base Model 之间的性能表现不能差距太大,太差的模型会拖后腿
代码实现
由于需要 stacking 中每个基模型都需要对数据集进行划分后进行交叉训练,如果为每个模型都写这部分的代码会显得非常冗余,因此这里提供一种简便实现 stacking 的思路。
具体做法就是先实现一个父类,父类中实现了交叉训练的方法,因为这个方法对所有模型都是一致的,然后声明两个方法:train 和 predict,由于采用的基模型不同,这两个方法的具体实现也不同,因此需要在子类中实现。下面以 python 为例进行讲解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import numpy as np
from sklearn.model_selection import KFold
class BasicModel(object):
"""Parent class of basic models"""
def train(self, x_train, y_train, x_val, y_val):
"""return a trained model and eval metric of validation data"""
pass
def predict(self, model, x_test):
"""return the predicted result of test data"""
pass
def get_oof(self, x_train, y_train, x_test, n_folds = 5):
"""K-fold stacking"""
num_train, num_test = x_train.shape[0], x_test.shape[0]
oof_train = np.zeros((num_train,))
oof_test = np.zeros((num_test,))
oof_test_all_fold = np.zeros((num_test, n_folds))
aucs = []
KF = KFold(n_splits = n_folds, random_state=2017)
for i, (train_index, val_index) in enumerate(KF.split(x_train)):
print('{0} fold, train {1}, val {2}'.format(i,
len(train_index),
len(val_index)))
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_val, y_val = x_train[val_index], y_train[val_index]
model, auc = self.train(x_tra, y_tra, x_val, y_val)
aucs.append(auc)
oof_train[val_index] = self.predict(model, x_val)
oof_test_all_fold[:, i] = self.predict(model, x_test)
oof_test = np.mean(oof_test_all_fold, axis=1)
print('all aucs {0}, average {1}'.format(aucs, np.mean(aucs)))
return oof_train, oof_test
上面最重要的就是进行 K-fold 训练的 get_oof 方法,该方法最终返回训练集和测试集在基模型上的预测结果,也就是两个一维向量,长度分别是训练集和测试集的样本数。
下面以两个基模型为例进行 stacking,分别是 xgboost 和 lightgbm,这两个模型都只需要实现 BasicModel 中的 train 和 predict 方法
第一个基模型1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import xgboost as xgb
class XGBClassifier(BasicModel):
def __init__(self):
"""set parameters"""
self.num_rounds=1000
self.early_stopping_rounds = 15
self.params = {
'objective': 'binary:logistic',
'eta': 0.1,
'max_depth': 8,
'eval_metric': 'auc',
'seed': 0,
'silent' : 0
}
def train(self, x_train, y_train, x_val, y_val):
print('train with xgb model')
xgbtrain = xgb.DMatrix(x_train, y_train)
xgbval = xgb.DMatrix(x_val, y_val)
watchlist = [(xgbtrain,'train'), (xgbval, 'val')]
model = xgb.train(self.params,
xgbtrain,
self.num_rounds)
watchlist,
early_stopping_rounds = self.early_stopping_rounds)
return model, float(model.eval(xgbval).split()[1].split(':')[1])
def predict(self, model, x_test):
print('test with xgb model')
xgbtest = xgb.DMatrix(x_test)
return model.predict(xgbtest)
第二个基模型1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import lightgbm as lgb
class LGBClassifier(BasicModel):
def __init__(self):
self.num_boost_round = 2000
self.early_stopping_rounds = 15
self.params = {
'task': 'train',
'boosting_type': 'dart',
'objective': 'binary',
'metric': {'auc', 'binary_logloss'},
'num_leaves': 80,
'learning_rate': 0.05,
# 'scale_pos_weight': 1.5,
'feature_fraction': 0.5,
'bagging_fraction': 1,
'bagging_freq': 5,
'max_bin': 300,
'is_unbalance': True,
'lambda_l2': 5.0,
'verbose' : -1
}
def train(self, x_train, y_train, x_val, y_val):
print('train with lgb model')
lgbtrain = lgb.Dataset(x_train, y_train)
lgbval = lgb.Dataset(x_val, y_val)
model = lgb.train(self.params,
lgbtrain,
valid_sets = lgbval,
verbose_eval = self.num_boost_round,
num_boost_round = self.num_boost_round)
early_stopping_rounds = self.early_stopping_rounds)
return model, model.best_score['valid_0']['auc']
def predict(self, model, x_test):
print('test with lgb model')
return model.predict(x_test, num_iteration=model.best_iteration)
下一个步骤就是将这两个基模型的输出作为第二层模型的输入,这里选用的第二层模型是 LogisticsRegression,
首先需要将各个基模型的输出 reshape 和 concatenate 成合适的大小1
2
3
4
5
6
7
8
9
10
11lgb_classifier = LGBClassifier()
lgb_oof_train, lgb_oof_test = lgb_classifier.get_oof(x_train, y_train, x_test)
xgb_classifier = XGBClassifier()
xgb_oof_train, xgb_oof_test = xgb_classifier.get_oof(x_train, y_train, x_test)
input_train = [xgb_oof_train, lgb_oof_train]
input_test = [xgb_oof_test, lgb_oof_test]
stacked_train = np.concatenate([f.reshape(-1, 1) for f in input_train], axis=1)
stacked_test = np.concatenate([f.reshape(-1, 1) for f in input_test], axis=1)
然后用第二层模型进行训练和预测1
2
3
4
5from sklearn.linear_model import LinearRegression
final_model = LinearRegression()
final_model.fit(stacked_train, y_train)
test_prediction = final_model.predict(stacked_test)
上述实现的完整代码见下面的链接
https://github.com/WuLC/MachineLearningAlgorithm/blob/master/python/Stacking.py
如有错漏,欢迎交流指正
参考
Introduction to Ensembling/Stacking in Python 如何在 Kaggle 首战中进入前 10%