《Real-time Personalization using Embeddings for Search Ranking at Airbnb》 阅读笔记
Real-time Personalization using Embeddings for Search Ranking at Airbnb 是 KDD 2018 的 best paper, 整篇文章读下来,初看好像只是套了 word2vec 来生成 user embedding 和 item embedding;但是细读下来,会发现其中有不少细节值得考究,这种风格跟 youtube 在 2016 年发表的那篇 Deep Neural Networks for YouTube Recommendations 很像,两篇都是实践性很强的 paper,非常值得看。而且两篇文章分别代表着 deep learning 中生成 embedding 的两大流派:无监督和有监督。本文主要讲的是 Airbnb 的这篇 paper 的基本做法和一些细节。
Airbnb 的这项工作的业务背景是:用户在其租房 app 上搜索时,需要返回一个 list 的推荐结果,在 paper 中提到了 Airbnb 用的是业界比较主流的 Learning To Rank 技术,关于 LTR 的技术细节可参考微软的 From RankNet to LambdaRank to LambdaMART: An Overview,Airbnb 用的也是 pairwise 模式下的 LambdaRank,而这篇 paper 主要描述的是如何通过 word2vec 的方式生成 user embedding 和 item embedding 作为 feature 供排序模型使用(文章中也将 item 称为 listing,所以后文中这两个词的含义是一样的)。
这篇文章的主要亮点如下
1. 将正反馈(用户最终下单,作为 global context)和负反馈(商家拒接接单,作为额外的一个 data set)的信号加入到 skip-gram 中进行训练
2. 做 negative sampling 时,考虑到具体业务不仅仅在全集上做负采样
3. 同一个 uid 的样本较为稀疏,因此 user embedding 从 uid 粒度变为 user type 粒度,避免样本过于稀疏 embedding 学习不充分
这 3 点其实都是作者在考虑到具体业务场景下,所做出的改进,也是笔者认为这篇 paper 最值得学习的地方:不要盲目地套算法,而是要充分考虑到当前具体业务然后做出相应的适配和改进
离线训练
paper 中的离线训练可分为两大部分:short-term interest 和 long-term interest
对于短期 (short-term) 兴趣,利用了 800 billion 个 click session 来训练了 listing embedding
对于长期 (long-term) 兴趣,利用了 50 million 个用户的 booked listings 来训练 user type embedding 和 listing type embedding
具体的训练方法基本就是 word2vec 中的 skip-gram,下面会分别描述这两部分的具体训练细节
listing embedding
在 short-term insterest 中只生成 item embedding,训练的样本就是 click session(类比 nlp 中的一个 sentence),在 paper 中共的定义就是用户一系列的点击事件;在构建这个训练数据集时,核心就是如何定义 session 的长度,在 paper 中定义当用户的两次点击超过 30 分钟时,那这两次点击应该属于两个 session。
假设总体训练集为 \(S\), 每个 session 为 \(s=(l_1,l_2...l_M) \in S\), 则通过 word2vec 中的 skip-gram 可写出 loss 如下
\[\begin{align} L=\sum_{s \in S}\sum_{l_i \in s}(\sum_{-m \le j \le m,j \ne 0}^M \log p(l_{i+j}|l_i))\tag{1} \end{align}\]
上面的 m 是个超参,表示 skip-gram 训练时窗口的大小,且上式的概率可通过 embedding 向量和 softmax 表示成如下形式
\[\begin{align} p(l_{i+j}|l_i) = \frac{\exp(v_{l_j}^T v_{l_{i+j}}^{'})}{\sum_{l=1}^{|V|}\exp(v_{l_i}^Tv_{l}^{'})}\tag{2} \end{align}\]
上式中的 \(|V|\) 是所有 item 的集合, \(v\) 和 \(v'\) 分表表示 input vector 和 output vetor,其实就是同一个 item 在 skip gram 模型中两个参数矩阵的表示,即如下图所示的参数矩阵
W 和 W';具体可参考讲义 CS224n: Natural Language Processing with Deep Learning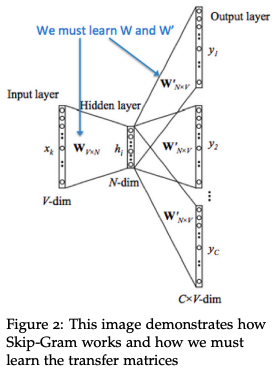
类似 word2vec 由于这个集合一般很大,算一次公式(2)的概率时分母的累加的耗时会非常长,为了加速训练,word2vec 中提出了 negative sampling 的策略,简单来说,就是对于每个 session 内的每个 clicked item,从其窗口 m 内选择一些 positive pairs \((l, c)\) 作为 positive set(记为 \(D_p\)), 同时从整个 item 集合 \(|V|\) 中随机选一些 negative pairs \((l, c)\) 取一些 item 作为 negative set (记为 \(D_n\)), 不用 softmax 而是用 sigmoid 的方式将要求解的参数写成如下形式
\[\begin{align} \arg\max_{\theta} \sum_{(l,c) \in D_p} \log\frac{1}{1+e^{-v_{c}^{'}v_l}} + \sum_{(l,c) \in D_n} \log\frac{1}{1+e^{v_{c}^{'}v_l}} \tag{3} \end{align}\]
上式中要求解的参数 \(\theta\) 就是 每个 item 的 embedding \(v_l\),基本就是原始 word2vec 中的 skip-gram 算法了,下面文章中的几个点可以认为是作者根据业务对 word2vec 的一些改动,也是非常值得借鉴的
(1) 利用监督信号作为 global context
在 airbnb 的业务中,上面的 session 实际上可分为两大类,分别是最终有下单的 session 和没有下单的 session,paper 中分别称其为 booked session 和 exploratory sessions,这两个实际上都是监督信号,而在 paper 中只使用了第一个监督信号,则公式 (3)可写成如下形式
\[\begin{align} \arg\max_{\theta} \sum_{(l,c) \in D_p} \log\frac{1}{1+e^{-v_{c}^{'}v_l}} + \sum_{(l,c) \in D_n} \log\frac{1}{1+e^{v_{c}^{'}v_l}} + \\\ \log \frac{1}{1+e^{-v_{l_b}v_l}}\tag{4}\end{align}\]
公式(4)中的 \(v_{l_b}\) 表示的是被下单的 item \(l_b\) 的 embedding,下图则是更直观地显示了这个监督信号是如何起作用的, 可以看到,每个 centeral listing/item 更新时都会与 booked listing/item 一起算一次概率,因此称这个 listing 为 global context,其效果相当于加强用户在购买前点击的所有 item 和最终下单的 item 的联系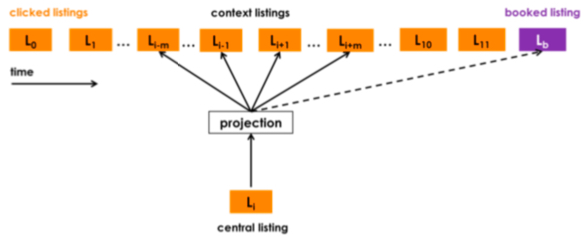
(2) 控制 negative sampling 的采样空间
上面提到 negative sampling 会随机从全集中抽取 n 个 item 作为负例,但是在 airbnb 的业务中,一个用户往往只会在一个 market (也就是旅游地点) 中下单,而上面做 negative sampling 得到的结果往往是, \(D_p\) 里的候选都是同一个 market 的,\(D_n\) 里的候选往往都不是同一个 market 的,paper 称这样的 imbalanced 并不是最优的,笔者猜测原始是在做预估时候候选的 item 基本都是同一个 market 的,而这样 \(D_n\) 的随机性使得同一个 market 内的正负 item 区分度并不高,因此,在原始的 nagative sampling 基础上增加了一项在同一 market 下随机选取负样本的 \(D_{m_n}\), 因此,最终的 loss 形式如下
\[\begin{align} \arg\max_{\theta} \sum_{(l,c) \in D_p} \log\frac{1}{1+e^{-v_{c}^{'}v_l}} + \sum_{(l,c) \in D_p} \log\frac{1}{1+e^{v_{c}^{'}v_l}} + \\\ \log \frac{1}{1+e^{-v_{l_b}v_l}}+\sum_{(l,m_n) \in D_{m_n}} \log\frac{1}{1+e^{v_{m_n}^{'}v_l}}\tag{5} \end{align}\]
(3) 冷启动的 item embedding
在推荐系统中,每天都会有很多新的 item 加入,还有一些 item 压根没有 click session,无法通过上面的 word2vec 训练出对应的 embedding;对于这些处于冷启动的 item,paper 中用了一种比较常见且有效的手段来处理:根据冷启动的 item 的属性选取 k 个与其最相似且有 embedding 的 item 然后做 mean pooling,选取的方法则是根据 item 的一些 meta-data,如 price,listing type 等
user_type/listing_type embeddings
上面的训练方法中只用了 click session,且只生成了 listing embedding,paper 中认为这个是 short-term interest,其实这从上面对 session 的划分规则就体现了这一点,即两次点击间隔超过 30 min 就认为是两个不同的 session,在这种划分规则下,捕获的就是用户的短期兴趣,且一个 session 内所有的 item 基本上都是同一个 market 的了
为了(1)捕获用户更长周期的兴趣(2)捕获 cross-market 的 listing embedding 的关联,paper 中通过 skip-gram 训练出 user embedding + listing embedding, 且相对于前面只训练出 listing embedding 的 short-term interest,paper 称这个为 long-term interest。
前面的训练数据是 800 billion 个 click session,而这里捕获 long-term interest 的训练则 利用了 50 million 个用户的 booked listings
假设总体训练集为 \(S_b\), 每个 booked listing 为 \(s_b=(l_{b1},l_{b2}...l_{bM}) \in S\), 表示某个用户的历史下单的所有 lisitng(按时间排序)
比起上面较为丰富的 click session,这个问题更为严峻,主要体现在下面几个方面
- 数据更为稀疏,前面的是点击事件,这里则是转化事件
- 某些用户的 booked listing 的长度可能只有 1,这样没法直接用 skip-gram 来训练
- 对于每个 entity, 如果需要较充分地学习出其 embedding,每个 entity 至少要出现 5-10 次,而实际上不少 listing 被下单的次数是没有 5 次的
其中,问题 2 和 3 实际上都是问题 1 的具体表现,因此,paper 中解决上面的三个问题方法就是将 id 转为 type,本质上就是将 id 特征转为一个更泛化的特征,基本的装换方法就是根据 user/listing 的一些 meta 信息映射成一个 type,然后用这个 type 来代替 user/listing 的 id,映射表如下图所示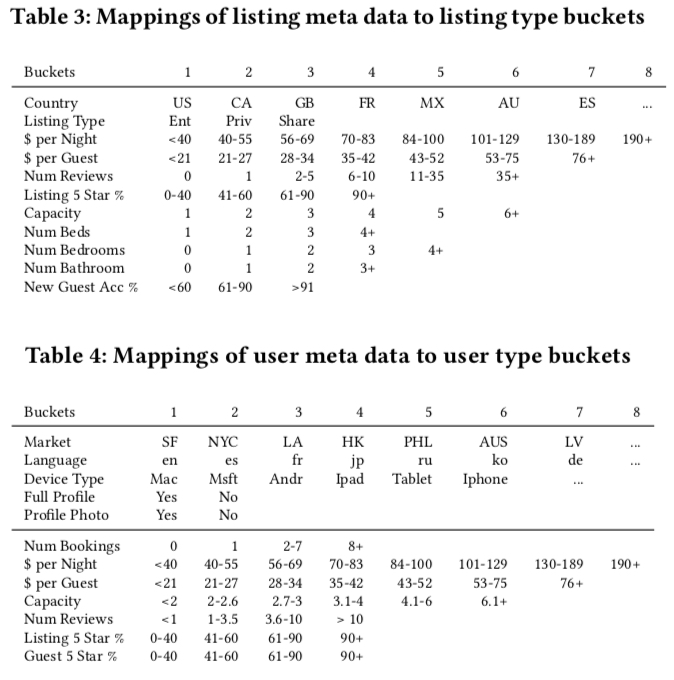
解决上面的数据稀疏问题后,还剩下的一个问题是如何通过 word2vec 训练出处于同一向量空间的 user_type embedding 和 listing_type embedding?因为最原始的 word2vec 中的 sequence 往往都是同一属性的 item 的
paper 中解决这个问题的方法也和直接,就是将前面提到的每个 user 的 booked listing \(s_b=(l_{b1},l_{b2}...l_{bM}) \in S\) 变为 \(s_b=(u_{type1},l_{type1}...u_{typeM}, l_{typeM}) \in S\), 值得注意的是,虽然每个 session 的 sequence 表示的是同一个 user_id,但是其 user_type 是会随时间变化而变化的,但是 paper 中并没有提到改变 user_type 的时间窗口,猜测是一旦发生变化就改变,然后插入到上面的 booked listing 对应的时间位置上,(这里有个问题,这样做似乎是没法解决那些 booked listing 长度为 1 的数据)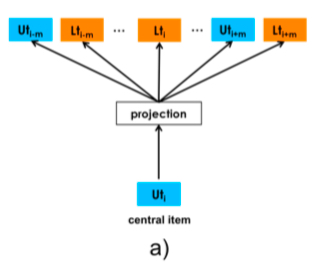
做了 negative sampling 后,loss 跟公式 3 是一样的,如下是 central item 是 user type 的情况(listing type 同理)
\[\begin{align} \arg\max_{\theta} \sum_{(u_t,c) \in D_{book}} \log\frac{1}{1+e^{-v_{c}^{'}v_{u_t}}} + \sum_{(u_t,c) \in D_{neg}} \log\frac{1}{1+e^{v_{c}^{'}v_{u_t}}} \tag{6} \end{align}\]
相比于前面在训练 listing embedding 在做 negative sampling 对同一个 market 中的 item 做额外的负采样,但是这里并没有做,原因是这里的 booked session 中对应的 item 已经是包含了不同 market 的,因此没必要做额外的处理
此外,airbnb 的这个业务背景中也有商家的反馈数据,即可能会存在某些用户下单但是商家不接单的情况(可能的原因是用户信息不完整、评分低等),这些负反馈信息对于 user_type embedding 的学习是有好处的,对于这些负反馈信号,airbnb 是按照如下方法加入到模型中的
对于每个 central item,训练的数据除了上面的做 negative sampling 得到的 \(D_{book}\) 和 \(D_{neg}\),还定义了一个 \(D_{rej}\), 其中包含了 user 历史上被拒绝的 pair \((u_t, l_t)\),
则当前的 central item 是 user(listing 同理) 时, loss 可写成如下形式,
\[\begin{align} \arg\max_{\theta} \sum_{(u_t,c) \in D_{book}} \log\frac{1}{1+e^{-v_{c}^{'}v_{u_t}}} + \sum_{(u_t,c) \in D_{neg}} \log\frac{1}{1+e^{v_{c}^{'}v_{u_t}}} + \\\ \sum_{(u_t,l_t) \in D_{neg}} \log\frac{1}{1+e^{v_{l_t}v_{u_t}}} \tag{7}\end{align}\]
则加入了这个监督信号后的 skip gram 则如下图所示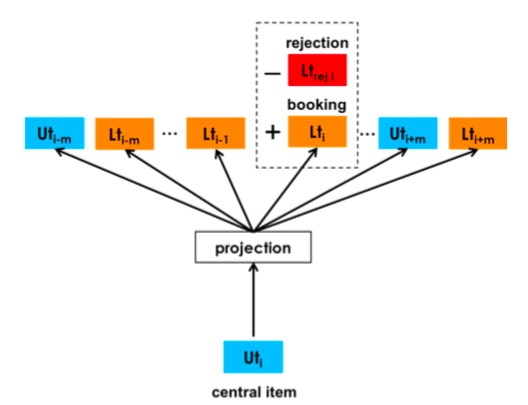
训练细节
上面讲的只是大致的训练过程,但是其中的一些训练细节也是非常重要的,尤其是这种有具体业务背景的工作, paper 中只讲了训练 listing embedding 的一些细节
训练数据细节
- 如前文所说,用了 800 million 的 click session,划分的标准就是同一个用户的连续两次点击如果超过 30min 就划分为两个 session,
- 去掉了一些无效点击(定义为点击后在页面停留时长小于 30s 的)
- 对于 booked session 做了 5 倍的 upsampling
训练细节
- 天级更新,按照时间滑动窗口从当前时间往前取几个月的训练数据
- 每天都重新训练 listing embedding(随机初始化),而不是在之前训练好的基础上做 finetune,paper 称这样的效果比做 finetune 的要好
- embedding 的维度是 32(做了效果和资源的 trade-off),skipgram 的时间窗口是 5,训练 10 个 iteration 的效果是最好的
值得注意的是,上面之所以每天能重新训练 listing embedding, 是因为 Airbnb 没有直接把 embedding 作为一个 feature 输入到模型中,而是将 embedding 计算出来的 similarity 作为 feature 输入模型;而如果需要把 user/listing embedding 作为 feature 落入样本中,重新训练 listing embedding 应该是不行的, 原因分析如下
因为通过 embedding 计算出来的 user/item similarity 是由 user/item 在训练数据集中的相对位置决定了,这个信息在每天的训练数据中的变动其实是比较小的;但是每次重新训练 embedding 的时候是随机初始化的,这很容易导致同一个训练集两次训练出来的 embedding 所处的向量空间是不一样的,而如果将 embedding 直接作为 feature 输入一个 nn 模型,容易导致同一个 user/item 在昨天和今天的向量差别很大,对于一个 feature 来说这样来讲显然是不合理的
embedding 有效性校验
embedding 训练出来后,怎么判断其有效性是个值得探讨的问题,尤其是在深度学习缺乏可解释性的情况下,paper 中用到了以下几种方法,都比较值得借鉴
- 可视化
- 计算 listing embedding 之间的 cosine similarity
- 根据 embedding similarity 对历史日志中的 item 重新排序,看 booked item 的位置(越小越好)
方法(1)是可视化,也是评估 embedding 有效性常用的方法;通常做法是聚类然后看每个类里面的 item 的相关性,对于上面训练的 listing embedding,通过 k-means 聚成 100 个类,且由于 airbnb 中每个 item 可以对应于地图上的某个点,因此 paper 中做了两种可视化,第一种是将不同类的点用不同的颜色在地图上进行可视化,如下图所示,paper 称这样聚类的结果对于重新为每个 travel market 定义其范围也是有好处的,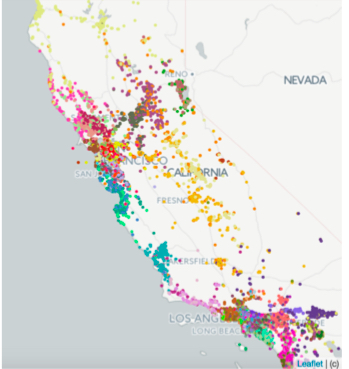
第二种可视化则是对于特定的 listing embedding,选取 k-nearest listing embedding,直观地看这些 listing 对应的房屋的相似性,如下图所示, 可以看到房屋的相似性还是比较高的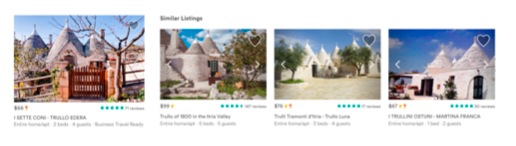
方法(2)是计算 embedding 的 cosine 相似性,如下面两个表中,根据 item 的一些 meta 信息来划分 listing embedding,然后计算这些划分好的各个类中的 item embedding 与其他各个 item embedding 的 cos 相似性的均值,从结果可知,价格、房屋类型越相似的 item,其对应的 listing embedding 的 cos 相似性越高 , 因此这些信息是可以被学习到 listing embedding 中的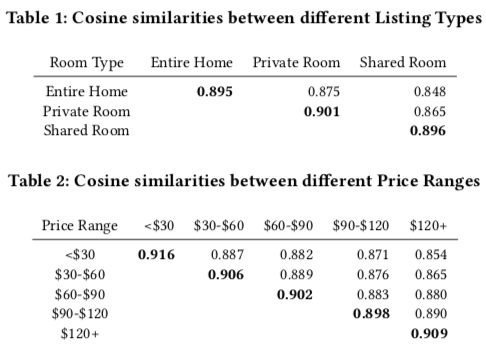
方法(3)是 paper 根据业务去设计的一种评估 embedding 优劣的方法,其 motivation 是:利用 embedding 信息来对历史的 search session 重新排序,并与 search rank model 的历史排序效果做比较。
基本的做法就是:选取用户某个 booked item 所出现过的所有历史 serach session, 每个 search session 会包含其他的 candidate items;根据用户历史的 clicked items 对应的 embedding,计算每个 candidate item 的 embedding 与这些 clicked items 的 embedding 的 similarity,并根据 similarity 重新排序,观察 booked item 的排序(越小越靠前)
因为是历史的 session,所以对于 candidate items 已经被 Airbnb 的 search rank 排过序了,因此可作为 baseline,paper 中选取了每个 user 最近 17 次的点击来计算相似性,效果如图所示,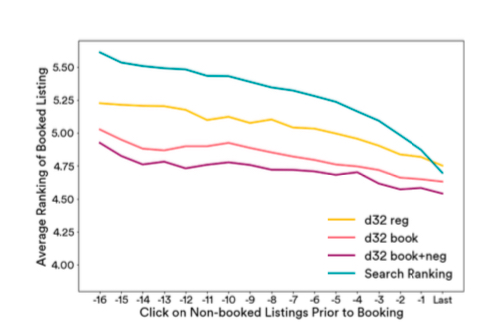
上图中各项含义如下
- search ranking:排序的后验,即历史 search session 的真正排序
- d32: 公式 (3) 训练出来的 embedding, 即原始的 word2vec 方法
- d32 book: 公式 (4) 训练出来的 embedding,即加上 booked item 作为 global context 训练出来的 embedding
- d32 book+neg: 公式 (5) 训练出来的 embedding,即做 nagative sampling 的时候专门考虑与 item 处于同一个 market 的 nagative samples
从上图可知,d32 book+neg 的效果是最好的
在线 serving
上面训练好的 embedding,在 serving 的时候怎么用?paper 中主要用到了两个地方
- Search Ranking: 用户搜索的排序模型
- Similar Listing Recommemdation:物品页面中相似物品动态的推荐
Search Ranking
对于 NN 模型,可以直接把 embedding 当做一个 feature 输进去,但是 airbnb 的 ranking model 并不是 NN 模型,而是基于树模型的 LambdaRank,这个模型的细节就不在这里展开了,感兴趣的同学可参考 paper 中的 4.4 节。
使用树模型意味着 embedding 不能直接输入模型,需要构造一些连续值特征。下面主要讲的是这些特征是如何构建以及线上效果
paper 中主要基于 embedding 间计算出来的相似性作为连续值特征,构造的特征列表如下图所示
上图中的一些符号含义如下
- \(H_c\): 用户过去两周点击过的 listing ids
- \(H_{lc}\): 用户点击过且停留时长超过 60s 的 listing ids
- \(H_s\): 用户点击的某个 listing 时跳过的其他的 listing ids(如点击了排序第 4 的,就跳过了前 3 个 listing)
- \(H_w\): 用户过去两周添加到心愿单的 listing ids
- \(H_i\): 用户过去两周联系过但是没有下单的 listing ids
- \(H_b\): 用户过去两周下单过的 listing ids
因此,上面的列表中的前 6 个 Feature 表示的都是当前 candidate 与用户在历史发生过交互的 lisitng 的一些相似性。除此之外,paper 还对 feature 做了 market 的划分,比如对于 \(H_c\), 将其划分为 \(H_c(market1)\), \(H_c(market2)\)..., 然后对同一个 market 内的所有 listing id 的 embedding 做一个 mean-pooling, 称为 market-level embedding,然后计算 candidate listing 跟各个 market-level embedding 的 similarity 并取最大那个,即对于 candidate \(l_c\), 上面第一个 feature 的计算如下
\[\begin{align} EmbClickSim(l_c, H_c) = \max_{m \in M} cos(v_{l_i}, \sum_{l_h \in m, l_h \in H_c}v_{l_h}) \end{align}\]
笔者这里有个疑惑,为什么要取 max 操作而不是把所有的特征都加进去?因为上面的做法相当于将 market 和 simlarity 这两个 feature 做了交叉,如果把所有 feature 输进去也能扩大原始的 feature 的数量。paper 中并没有针对这一点作出解释,可能是都交叉的时候很多交叉特征的值都为空?
上面 table 后的这两个 feature 计算方法类似,只是没有再分 market 计算,因为这里的并不像前面提到的 listing 有明确的 market 概念, EmbLastLongClickSim 这个 feature 是为了捕获用户最近的兴趣了,而 UserTypeListingTypeSim 这个 feature 则是为了捕获用户长期更泛化的一些兴趣
上面的特征都攒了 30 天,下面是特征的覆盖度和重要性(通过树模型训练结果获取),airbnb 中的模型有 104 个特征,从图中可知,有 5 个 feature 进入了 top20 的重要 feature;其中有几个点值得关注
- EmbClickSum 的重要性是这些 embedding 构造出来的 feature 中最重要的,反映了用户短期内的兴趣
- 描述下单的特征中,用户的长期兴趣比用户的短期兴趣更好(UserTypeListingTypeSim 重要性高于 EmbBookSim),笔者猜测另一个原因可能是计算 EmbBookSim 数据会更为稀疏,因为一般对于一个用户来说两周内下单一次的频率是很低的
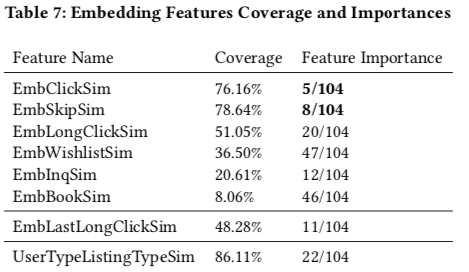
此外,标题中的 Real-time 体现在哪里,其实就是 Table 6 中的几个 feature 会随着用户的行为的实时变化而变化。
Similar Listing Recommemdation
Similar Listing Recommemdation 做的事情就是在每个 listing 详情页里推荐相似物品,这里主要利用的就是 listing embeddings 的 cos similarity 来选出 top-k 个最相似的物品, paper 将当前 airbnb 的相似物品推荐策略与这个基于 embedding 的方法作比较,线上的 AB 实验显示这个方法相比与当前的方法 ctr 提升了约 21%,cvr 提升了约 4.9%
小结
笔者认为这篇 paper 介绍了三个方面的内容
- 如何训练生成 embedding
- 怎么评估训练出来的 embedding 的有效性
- 线上怎么使用这些 embedding
训练方法是用了 word2vec 中的 skip-gram 方法,训练数据用了用户历史的 click session 和 book session,且根据具体业务在 skip-gram 做了一些改动,如做 market-level 的 negative sampling、将用户预定的 listing 作为 global context、将被商家拒绝的订单作为负例等;同时在转化数据系数情况下,将 id embedding 转为 type embedding,缓解了数据系数情况下 embedding 无法学得很好的问题。除此之外,一些训练细节也值得参考
评估生成的 embedding 的有效性时,除了最常用的可视化方法,paper 还用了另外两种值得参考方法,第一种是确定某些维度后,比较这些不同维度上的 listing embedding 的相似性,第二种则是根据 listing embedding 相似性对历史排序结果重新排序,同时看最终被下单的 listing 在重新排序后的结果
线上使用 embedding 时,由于 Airbnb 使用的是树模型,不能直接将 embedding 作为 feature 输入模型,paper 中是通过计算出 embedding 间的相似性作为连续值特征输入模型的
最后,知乎上如何评价 Airbnb 的 Real-time Personalization 获得 2018 kdd 最佳论文?也有很多值对这篇 paper 的解读,都值得一看,推荐看下这个回答