关键词抽取算法的研究
关键词抽取的一般步骤为:
分词–> 过滤停止词, 得到候选关键词–> 从候选关键词中选出文章的关键词
从候选关键词中选出文章的关键词需要通过关键词抽取算法实现,而关键词抽取算法可以根据是否需要人工标注的语料进行训练而分为有监督的提取和无监督的提取。 有监督的提取需要人工标注的语料进行训练,人工预处理的代价较高。而无监督的抽取算法直接利用需要提取关键词的文本即可进行关键词的提取,因此适用性较强。
关键词抽取中无监督的抽取算法可分为三大类: 1)基于统计特征的,如 TF - IDF 2)基于词图模型的,如 TextRank 3)基于主题模型的,如 LDA
本文主要讲述 TF - IDF 算法、TextRank 算法、以及通过组合两者得到的三种新方法,然后通过 Java 实现这几种方法并比较这几种方法在特定语料库上进行关键词抽取的效果。
TF - IDF 算法
TF - IDF(Term Frequency-Inverse Document Frequency)算法是一种基于统计特征的非常经典的算法,通过计算一个词的 TF 值和 IDF 值的乘积作为该值的得分,然后根据得分从大到小对词语排序,选择分数高的词语作为关键词。
TF 值指词语在文本中出现的频率,如某篇文章分词并过滤停止词后的词语的数量为 n,而其中的某个词语 w 出现的个数为 m, 则词 w 的 TF 值为
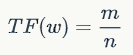
IDF 值则指词语在整个语料库中的出现的频率大小。这里首先要指出的是 TF - IDF 算法是针对一个语料库(也就是多篇文档进行)进行关键词提取的算法。假如语料库中共有 N 篇文档,而出现了词语 w 的文档数为 M。则词 w 的 IDF 值为
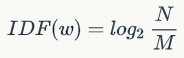
\(TF(w)*IDF(w)\) 则为词 w 的 TF - IDF 值,根据这个值对候选词从大到小排序,选择前 n 个作为候选关键词即可。
通过 Java 的实现并不难,主要是利用 Java 的集合框架 Map、List 等存储词语的中间得分、以及候选关键词等。
实现的完整代码见: https://github.com/WuLC/KeywordExtraction/blob/master/src/com/lc/nlp/keyword/algorithm/TFIDF.java
TextRank 算法
TextRank 算法是借鉴 PageRank 算法在语言处理中的一个算法,关于 PageRank 算法可参考这篇文章。无论是 PageRank 还是 TextRank,其关键思想都是重要性传递。
以 PageRank 为例,假如一个大型网站有一个超链接指向了某个小网站,那么小网站的重要性会上升,而上升的量则依据指向它的大网站的重要性。下图所示的就是一个例子:

假设网页 A,B 原来的重要性为 100 和 9,那么根据他们指向的网页,传递给 C、D 的重要性分别为 53 和 50。
在 TextRank 中将上图的网页替换成词语,将网页间的超链接换成词语间的语义关系;假如两个词的距离小于预设的距离,那么就认为这两个词间存在语义关系,否则不存在。这个预设的距离在 TextRank 算法中被称为同现窗口(co-occurance window)。这样便可构建出一个词的图模型。
但是在实际中应用时我们是无法预先知道网页 A、B 的重要性的,又或者说假如我们已经知道了网页的重要性,那么也不需要通过算法计算出网页的重要性了。这就成了一个先有鸡还是先有蛋的问题。
PageRank 的原始论文提出了解决这个问题的方法,这篇文章中通过具体的例子提到了相关的理论依据,就是幂法求特征向量与初始值无关。具体做法就是,先给每个网页随机附一个初值,然后通过迭代计算直至收敛,理论证明了收敛的值与初始值无关。
同样的,TextRank 也采取了相同的方法,就是先随机赋初值,然后通过迭代计算得到每个 词的重要性的得分。词语 \(V_i\) 的得分计算公式如下所示:
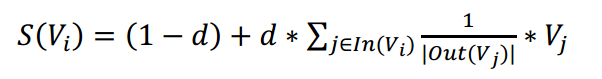
上式中各符号表示如下
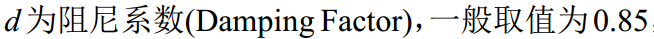
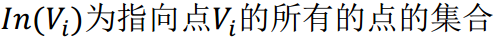
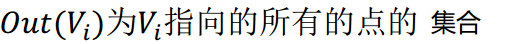
实现的一个关键点在于构建词的图模型,在 Java 中通过队列实现,队列大小即为同现窗口的大小,移动队列的过程中将队列内部的词语互相连接。连接的形式通过 java 的Map<String,Set<String>>类型实现,表示指向词语(第一个 String)的所有其他词语(Set<String>)的实现的关键代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28Map<String, Set<String>> words = new HashMap<String, Set<String>>();
Queue<String> que = new LinkedList<String>();
for (String w : wordList) //wordList为候选关键词
{
if (!words.containsKey(w))
{
words.put(w, new HashSet<String>());
}
que.offer(w); // 入队
if (que.size() > coOccuranceWindow)
{
que.poll(); // 出队
}
for (String w1 : que)
{
for (String w2 : que)
{
if (w1.equals(w2))
{
continue;
}
words.get(w1).add(w2);
words.get(w2).add(w1);
}
}
}
另外一个实现关键点就是判断算法是否收敛,可以认为前后两次计算出来的值小于指定的阈值(一般取值较小,如 0.000001)时算法收敛,或者超过设定的最大迭代次数时停止。实现的关键代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26min_diff = 0.000001
Map<String, Float> score = new HashMap<String, Float>();
for (int i = 0; i < max_iter; ++i)
{
Map<String, Float> m = new HashMap<String, Float>();
float max_diff = 0;
for (Map.Entry<String, Set<String>> entry : words.entrySet())
{
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String other : value)
{
int size = words.get(other).size();
if (key.equals(other) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(other) == null ? 0 : score.get(other)));
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 1 : score.get(key))));
}
score = m;
//exit once recurse
if (max_diff <= min_diff)
break;
}
完整的实现代码见: https://github.com/WuLC/KeywordExtraction/blob/master/src/com/lc/nlp/keyword/algorithm/TextRank.java
综合 TextRank 多同现窗口
由于 TextRank 的同现窗口的大小会影响提取的效果,如下图是同现窗口为 2~10 的时候评估值为 F1 值的变化情况。(测试语料)
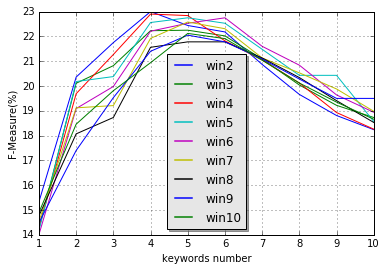
而原始的 TextRank 算法仅仅是建议该值设为 2~10,无法知道对于一篇文章的最优同现窗口,因此本方法会综合 TextRank 多同现窗口的结果,将一个词语在不同大小的窗口下的得分相加,作为该词的总得分,然后根据总得分对词语排序,选择得分较高的前 n 个词作为候选关键词 。
该算法的效果与原始的 TextRank 算法的效果对比如下(测试语料)
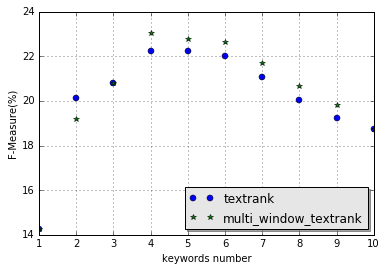
图中的textrank表示原始的 TextRank 算法的效果,而multi_window_textrank表示综合了大小为 2~10 的同现窗口的结果的效果。从图中可知,在提取关键词个数大于 4 个的时候,该方法的效果要优于原始的 TextRank 算法,但是 F1 值的提升幅度不大,并且实际运行的时候,综合多同现窗口的方法花费的时间是原始 TextRank 算法的 14 倍左右。
代码的具体实现见: https://github.com/WuLC/KeywordExtraction/blob/master/src/com/lc/nlp/keyword/algorithm/TextRankWithMultiWin.java
TextRank 与 TF - IDF 综合
考虑词语的 IDF 值
由于 TextRank 算法仅考虑文档内部的结构信息,导致一些在各个文档的出现频率均较高且不属于停止词的词语最总的得分较高。原因是没有考虑词语在整个语料库中的权重。因此在 TextRank 算法得到的每个词的得分基础上,乘上这个词在整个语料库的 IDF 值,IDF 值是 TF - IDF 算法中的一个概念,该值越大,表示这个词在语料库中出现的次数越少,越能代表该文档。
将词语的 TextRank 得分乘上这个词的 IDF 值后作为该词的新得分,然后根据得分从大到小排序,选择得分高的前 n 个词作为关键词即可。
下面是考虑了词语的 IDF 值的方法与原始的 TextRank 算法的效果对比图(测试语料)
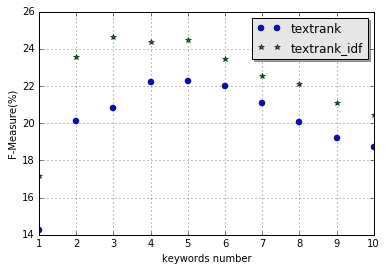
从图中可知,考虑了词语的 IDF 值后的方法的效果要优于原始的 TextRank 算法,运行时间约为 TextRank 算法的两倍。
完整的代码实现见: https://github.com/WuLC/KeywordExtraction/blob/master/src/com/lc/nlp/keyword/algorithm/TextRankWithTFIDF.java
TextRank 与 TF - IDF 投票
这种方法也是针对 TextRank 算法仅考虑文档内部的信息而忽略了文档外部的信息,综合 TextRank 算法和 TF - IDF 算法提取出来的结果。
具体的流程为:确定要抽取的关键词个数 n, 通过 TextRank 算法和 TF - IDF 算法对语料库分别提取 2n 个关键词, 选择同时在两个算法得到的结果中出现的词语作为关键词,假如同时出现的词语不足 n 个,那么剩下的词语从 TextRank 的结果或 TF - IDF 的结果中补。
下面是 TextRank 和 TF - IDF 投票方法的结果与原始的 TextRank 算法的结果的对比图(测试语料)

从结果可知,两个算法综合投票的方法的效果要优于原始的 TextRank 算法。运行的时间约为原始的 TextRank 的两倍。
完整的代码实现见: https://github.com/WuLC/KeywordExtraction/blob/master/src/com/lc/nlp/keyword/algorithm/TextRankWithTFIDF.java
总结
本文主要讲述了 TextRank 算法以及对其进行简单改进的三种方法:综合多同现窗口的结果、考虑词语的 IDF 值、TF - IDF 与 TextRank 共同投票。通过 Java 实现并比较其效果(评判指标为 F1 值)。下图是这几个算法的总效果对比图。(测试语料)
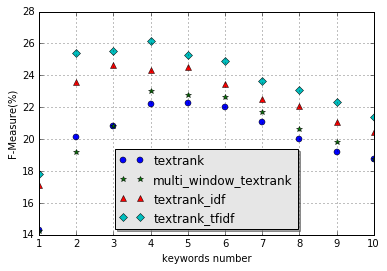

综合多同现窗口的改进方案后的效果虽然要略优于原始的 TextRank 算法,但是消耗的时间是原始 TextRank 算法的 14 倍左右;综合 TextRank 算法和 TF - IDF 算法后的结果是改进算法后最优的,其次是考虑 TextRank 提取出的关键词的 IDF 值的改进方案,两者的效果均要优于原始的 TextRank 算法, 消耗的时间也比原始的 TextRank 算法要多。
因此,若需要对单篇文档提取的关键词时,可采用原始的 TextRank 算法或综合多同现窗口的方法, 假如对提取效果的要求较高且对时间要求不高时,可以采用综合多同现窗口的方法, 反之直接采用原始的 TextRank 算法。如果需要对多文档进行关键词抽取时,四种方法都可以采用,但是考虑提取的效果以及消耗的时间, 建议使用 TextRank 算法和 TF - IDF 算法综合投票的方法或 TextRank 结合 IDF 值的方法,并且根据着重点是时间还是提取的精度,选择 TF - IDF 算法综合投票的方法或 TextRank 结合 IDF 值的方法。
上文提到的所有代码的地址为:https://github.com/WuLC/KeywordExtraction 除了算法的实现,还包括了语料库的导入、F1 值的计算方法的实现等。