并行算法的设计
本文主要讲述并行算法设计的一些注意事项。
设计并行算法首先需要要确认问题是否可以被并行化,最典型的情况是在处理一个任务队列时,队列中的前后任务是独立的,这时候就可以通过并行化让多个进程或线程同时处理其中的多个任务。关键点在于大任务可以被分解为若干个互相独立的小任务。
设计并行算法可以从以下四方面着手 1)分治 (divide and conquer) 2)数据分解 (data decomposition) 3)管道分解任务 (decomposing tasks with pipeline) 4)任务分配 (processing and mapping)
分治 (divide and conquer)
分治法是一个非常常用的思想,通过将一个问题分解成规模更小的子问题,然后并行解决子问题,再合并子问题的结果即可。如快速排序、归并排序都是分治法的经典例子。下图是归并排序的一个例子

数据分解 (data decomposition)
数据分解指当要处理的数据的最小单元间相互独立时,可通过并行化来实现。如将一个 2X2 的矩阵中的每个元素都乘上 4 时,如果采取串行化需要按顺序将每个元素逐一乘上 4,但是采取并行化时可以同时将每个元素乘上 4。如下所示,图中的 worker 指进程或线程。
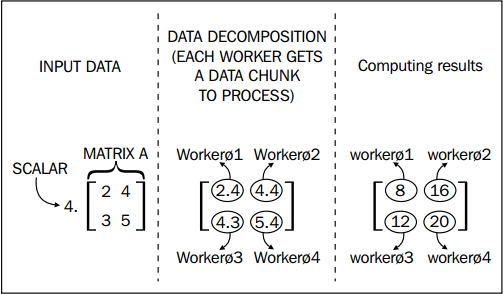
上面的例子比较简单,仅仅是为了说明数据分解的概念,在实际应用中,往往还需要考虑数据量与 worker 数量的不对称性问题,并且在将各自的结果合并时中需要考虑不同 worker 间的通信问题。
管道分解任务 (decomposing tasks with pipeline)
管道(pipeline),也可以称为流水线技术,是类似于工厂生产的流水线的一种设计方式。如下图所示就是流水线的一个例子:
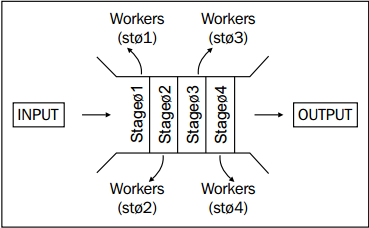
上图首先将一个大任务分成了四个小任务,然后每个 worker 分别处理其中的一个任务,每个任务的输出是下一个任务的输入。
假设每个小任务消耗的时间是 t,那么当完成 1 个大任务的时候串行和并行方式消耗的时间均是 4t。但是当完成 k 个大任务时,串行化消耗的时间是 4t*k, 但是并行化需要的时间是 4t+(k-1)*t, 当 k 很大时,并行化节省的时间就相当可观了。
任务分配 (processing and mapping)
上面提到的三种方法均是将大任务分解,然后通过并行完成小任务来实现并行化。但是在将任务分解后,需要注意的是如何分配任务给各个 worker,使得每个 worker 的负载均衡,从而达到最优的效果。
在这个问题主要是要区分独立的任务和需要交换数据(通信)的任务。独立的任务可以分配给不同的 worker 去完成,因为这些任务不需要通信的成本;而将需要经常进行通信的任务让单独一个 worker 完成,考虑到网络通信的开销,这样能够提高性能。
总结
上面主要提到了并行化算法的几个关键点,包括将大任务进行分解的几种方法(分治、数据分解、管道)以及将分解后的任务分配给 worker 时的注意事项。要注意的是这几种方法在实际中常常会混用,举一个实际一点的例子,如果要对一个很大的数组排序,单台机器的内存都放不下这个数组了,那该怎么办?
首先将数组分成 k 份,然后分配给 k 台机器分别进行排序,排序完毕后我们有了 k 个 sorted list,然后将 k 个 sorted list 两两合并,当合并后的数据越来越大时,单台机器内存不足时,可以采取外排序,将两个 sorted list 存储在硬盘中,每次取出前 n 个进行合并。
也许在实际中有更好的方法,但是上面的例子中实现的并行化就是利用到了分治法和数据分解法,实际中还可以根据机器的配置情况分配不同的任务负载。