python 中的可迭代对象 (iterable)、迭代器 (iterator) 与生成器 (generator)
本文主要讲述 python 中的几个概念:可迭代对象 (iterable)、迭代器 (iterator) 与生成器 (generator)。
可迭代对象 (iterable) 与 迭代器 (iterator)
对于 string、list、dict、tuple 等这类容器对象,可以使用 for 循环对其进行遍历。像这种可以被遍历的对象被称为可迭代对象。
通过 for 语句对遍历可迭代对象时,实际上是调用可迭代对象内部的 __iter__() 方法(因此一个可迭代对象必须要实现 __iter__() 方法),调用了这个方法会返回一个迭代器 (iterator),通过迭代器便可遍历可迭代对象。见下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13x = [1, 2, 3]
y = iter(x)
z = iter(x)
next(y)
1
y.next()
2
next(z)
1
type(x)
<class 'list'>
type(y)
<class 'list_iterator'>
这里 x 是一个列表,是一个可迭代对象。y 和 z 是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。
迭代器也分具体的迭代器类型,比如 list_iterator,set_iterator。iter(x)语句实际上是调用了 x 内部的 __iter__ 方法的, 调用 __iter__ 方法后会返回一个迭代器,由于迭代器内部实现了 next 方法 (python2 中是 next 方法,python3 是 __next__ 方法,一个迭代器必须实现此方法),因此可通过 next() 方法来遍历可迭代对象。
因此,执行下面语句:
1
2
3 x = [1, 2, 3]
for elem in x:
...
相当于以下流程
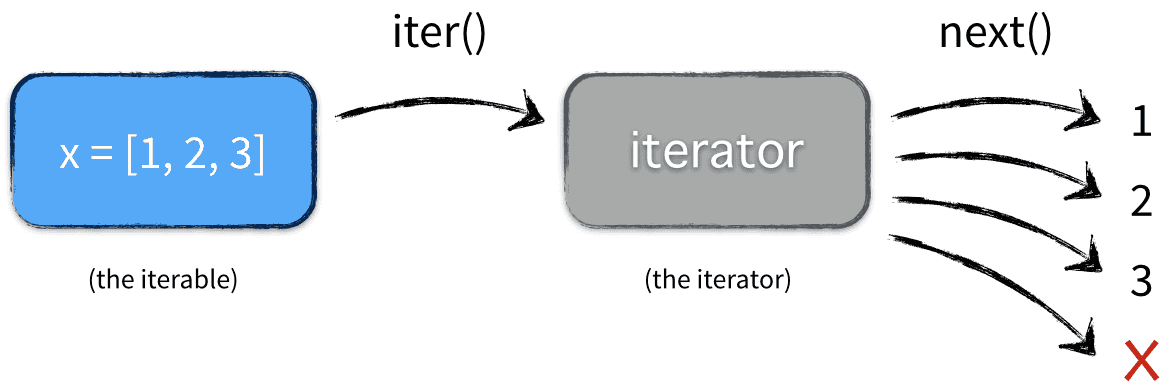
上图中调用 next() 方法直到没有后续元素时,next() 会抛出一个 StopIteration 异常,通知 for 语句循环结束。如1
2
3
4
5
6
7
8
9
10a = [1,3]
b = iter(a)
b.next()
1
next(b)
3
next(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
上面说的都是 python 自带的容器对象,它们都实现了相应的迭代器方法,那如果是自定义类需要遍历怎么办?
方法很简单,假如我们需要自定义一个有遍历功能的类 IterClass,那么只需要在这个类的内部实现一个 __iter__(self) 方法,使其返回一个带有 __next__(self) 方法的对象就可以了。如果你在 IterClass 刚好也定义了 __next__(self) 方法(一般使用迭代器都会定义),那在 __iter__() 里只要返回 self 就可以。下面是具体的实例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class IterClass:
def __init__(self, max):
self.max = max
def __iter__(self):
self.a = 0
self.b = 1
return self
def next(self):
fib = self.a
if fib > self.max:
raise StopIteration
self.a, self.b = self.b, self.a + self.b
return fib
if __name__ == '__main__':
fib = IterClass(10)
for i in fib:
print i
上面输出的结果为:1
2
3
4
5
6
70
1
1
2
3
5
8
上面的代码定义了一个 IterClass 类,用于生成 fibonacci 序列。用 for 遍历时会逐个打印生成的 fibonacci 数,max 是生成的 fibonacci 序列中数字大小的上限。
在类的实现中,定义了一个 __iter__(self) 方法,这个方法是在遍历时被 iter() 调用,返回一个迭代器。因为在遍历的时候,是直接调用 python 的内置函数 iter(),由 iter() 通过调用 __iter__(self) 获得对象的迭代器。
有了迭代器,就可以逐个遍历元素了。而逐个遍历的时候,也是使用 python 的内置 的 next() 函数,next() 函数通过调用对象的 next(self) 方法(python 3 为 __next__(self) 方法)对迭代器对象进行遍历。因为同时实现 __iter__(self) 和 next(self) , 所以 IterClass 既是可迭代对象,也是迭代器,在实现 __iter__(self) 的时候,直接返回 self 就可以。
为了更好地理解,对上面的内容的小结如下:在循环遍历自定义容器对象时, 会使用 python 内置函数 iter() 调用遍历对象的 __iter__(self) 获得一个迭代器, 之后再循环对这个迭代器使用 next() 调用迭代器对象的 next(self) 或 __next__(self)。__iter__ 只会被调用一次, 而 __next__ 会被调用 n 次。
生成器 (generator)
生成器其实是一种特殊的迭代器,不过这种迭代器更加简洁和高效, 它自动创建了 __iter__() 和 next() 方法(因此生成器其实既是一个可迭代对象,也是一个迭代器), 除了创建和保存程序状态的自动方法, 当发生器终结时, 还会自动抛出 StopIteration 异常。它不需要再像上面的类一样写 __iter__() 和 next () 方法了,只需要一个 yiled 关键字。生成器一定是迭代器(反之不成立)。
一个带有关键词 yield 的函数就是一个生成器, 它和普通函数不同, 生成一个 generator 看起来像函数调用, 但不会执行任何函数代码, 直到对其显式或隐式地调用 next() (在 for 循环中会隐式自动调用 next()) 才开始执行。虽然执行流程仍按函数的流程执行, 但每执行到一个 yield 语句就会中断, 并返回一个迭代值, 下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次, 每次中断都会通过 yield 返回当前的迭代值(yield 暂停一个函数,next () 从其暂停处恢复其运行)。见下面的例子:1
2
3
4
5
6
7
8
9
10
11
12def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
for char in reverse('hello'):
print(char)
o
l
l
e
h
用生成器来实现上面的斐波那契数列的例子是:1
2
3
4
5
6
7
8
9def fib():
prev, curr = 0, 1
while True:
yield curr
prev, curr = curr, curr + prev
f = fib()
list(itertools.islice(f, 0, 10))
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
生成器在 Python 中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,此外,相比其它容器对象它更能节省内存和 CPU,它也可以用更少的代码来实现相似的功能。如果构造一个列表的目的仅仅是传递给别的函数, 那么就可以用生成器来代替。但凡看到类似:1
2
3
4
5def something():
result = []
for ... in ...:
result.append(x)
return result1
2
3def iter_something():
for ... in ...:
yield x
另外对于生成器,python 还提供了一个生成器表达式 (generator expression):类似与一个 yield 值的匿名函数。表达式本身看起来像列表推导式, 但不是用方括号而是用圆括号包围起来, 它返回的是一个生成器对象而不是列表对象。见下面的例子:1
2
3
4
5
6
7
8
9
10
11a = (i*i for i in xrange(5))
for num in a:
print num
...
0
1
4
9
16
a
<generator object <genexpr> at 0x02B707D8>
参考: https://segmentfault.com/a/1190000002900850 http://foofish.net/blog/109/iterators-vs-generators