怎样用数据洞察你的用户
本文内容主要来源于该知乎 live,主要介绍了受众定向(用户画像)的分类和方法、具体介绍标签体系建立以及如何进行行为定向。
受众定向与用户画像
原始行为数据无序杂乱,不能直接应用于业务,因此要将用户的原始行为转化为对用户的描述,也就是受众定向(用户画像),但是这里需要注意的是不能想当然地描述用户,而是要根据需求方(如广告主)的需求来为用户打上相应标签
受众定向与常听到的用户画像的差别不大,均是研究如何描述用户,为用户打上标签,两者只是在着重点上有细微区别
受众定向重点是可优化,也就是跟侧重于效果,而用户画像则更侧重于可解释性,然而在实际中对用户的描述往往是两者混合的,如对广告主需要可解释性强的标签,而对于模型则更侧重那些有效的标签(可解释性不一定好)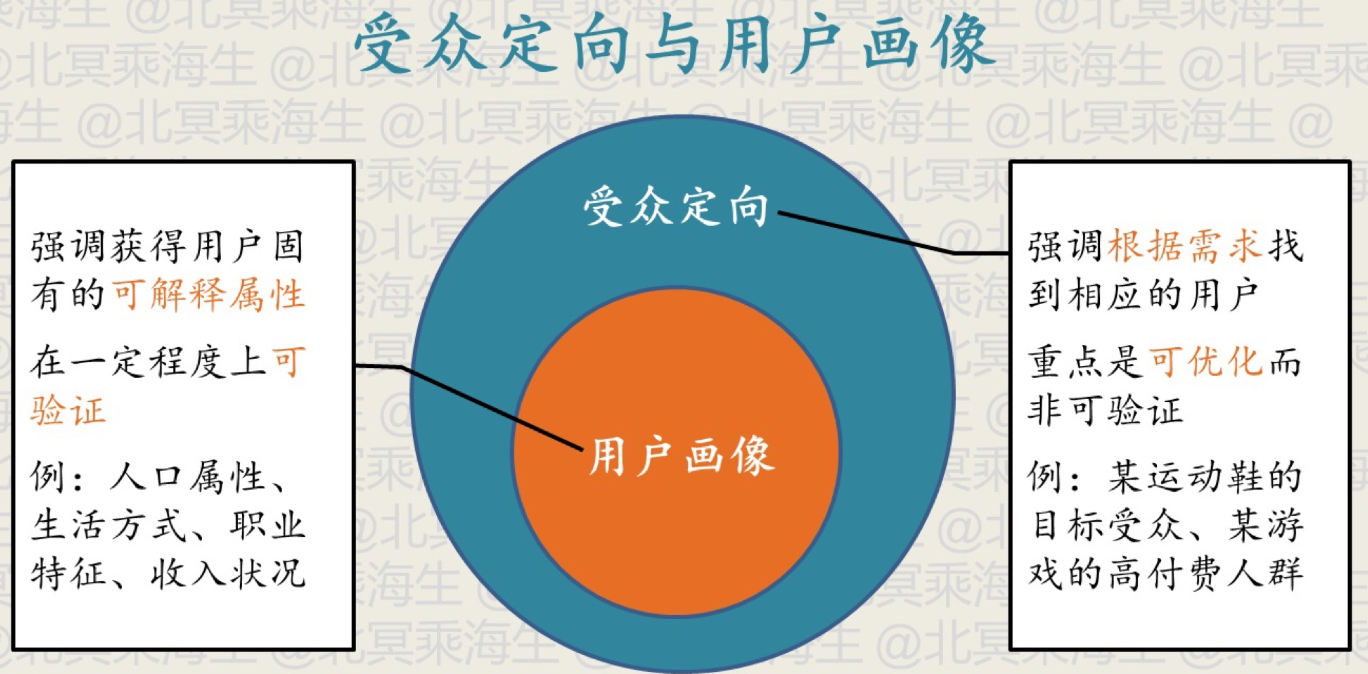
受众定向的分类
下面以计算广告为例阐述可受众定向需要在哪些维度上做打标签
1)用户维度 \(t(u)\), 描述用户的固有属性 2)上下文维度 \(t(c)\),描述用户浏览的内容 3)用户 - 广告维度 \(t(a,u)\),描述用户在某个广告主下的特有属性
实际中需要为广告打上标签 \(t(a)\),用于描述广告的固有属性,从而与用户匹配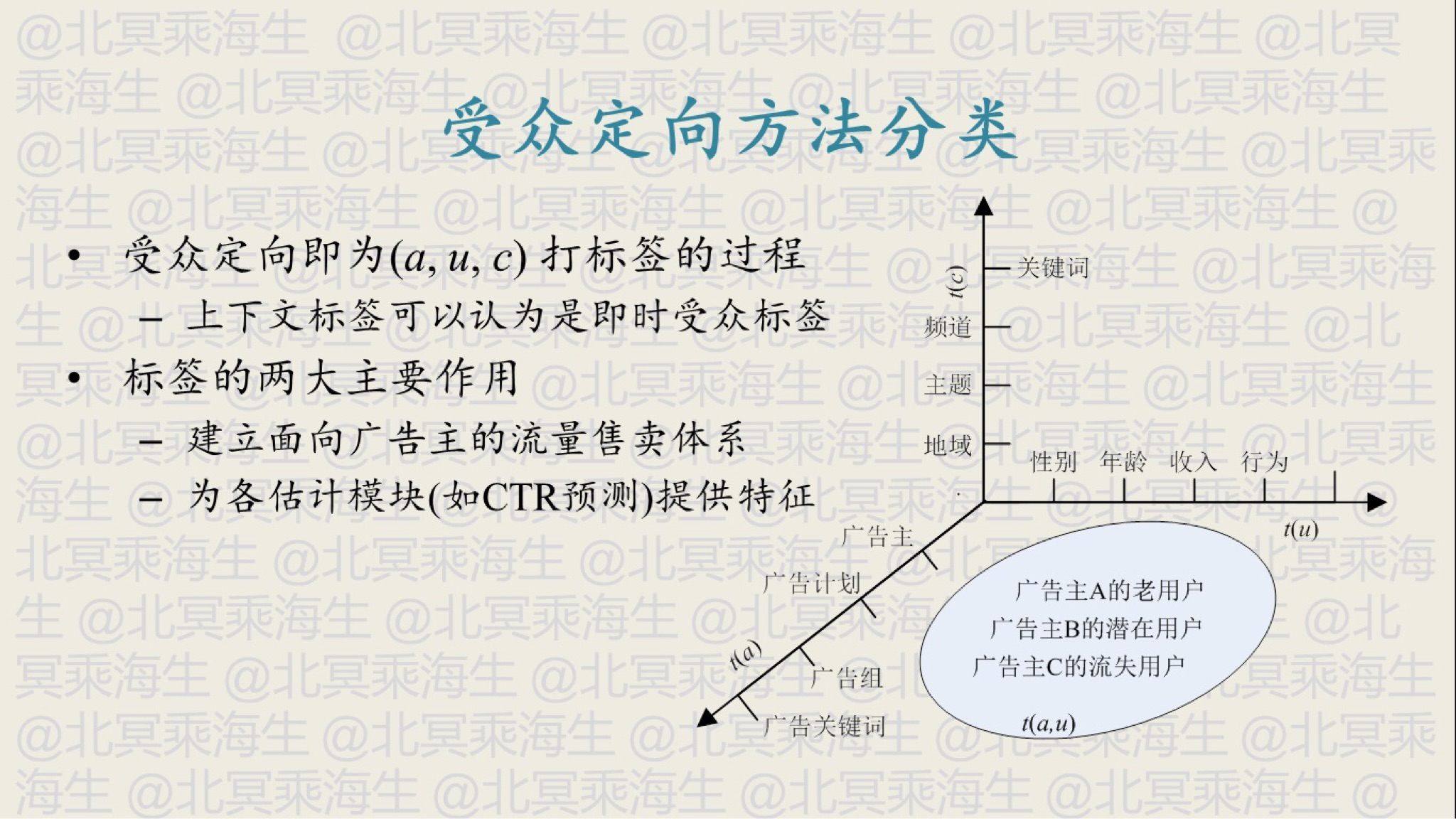
如上图所示,受众定向建立的标签一般有两种作用,而第一种作用的标签需要可解释性,第二种作用的标签则更强调其效果
受众定向的方法
同样以计算广告为例,下图展示了受众定向常用的方法,左边表示广告的生命周期,右边表示各个阶段的受众定向的方法和效果,其中越往左效果越好,具体方式的含义可参考这里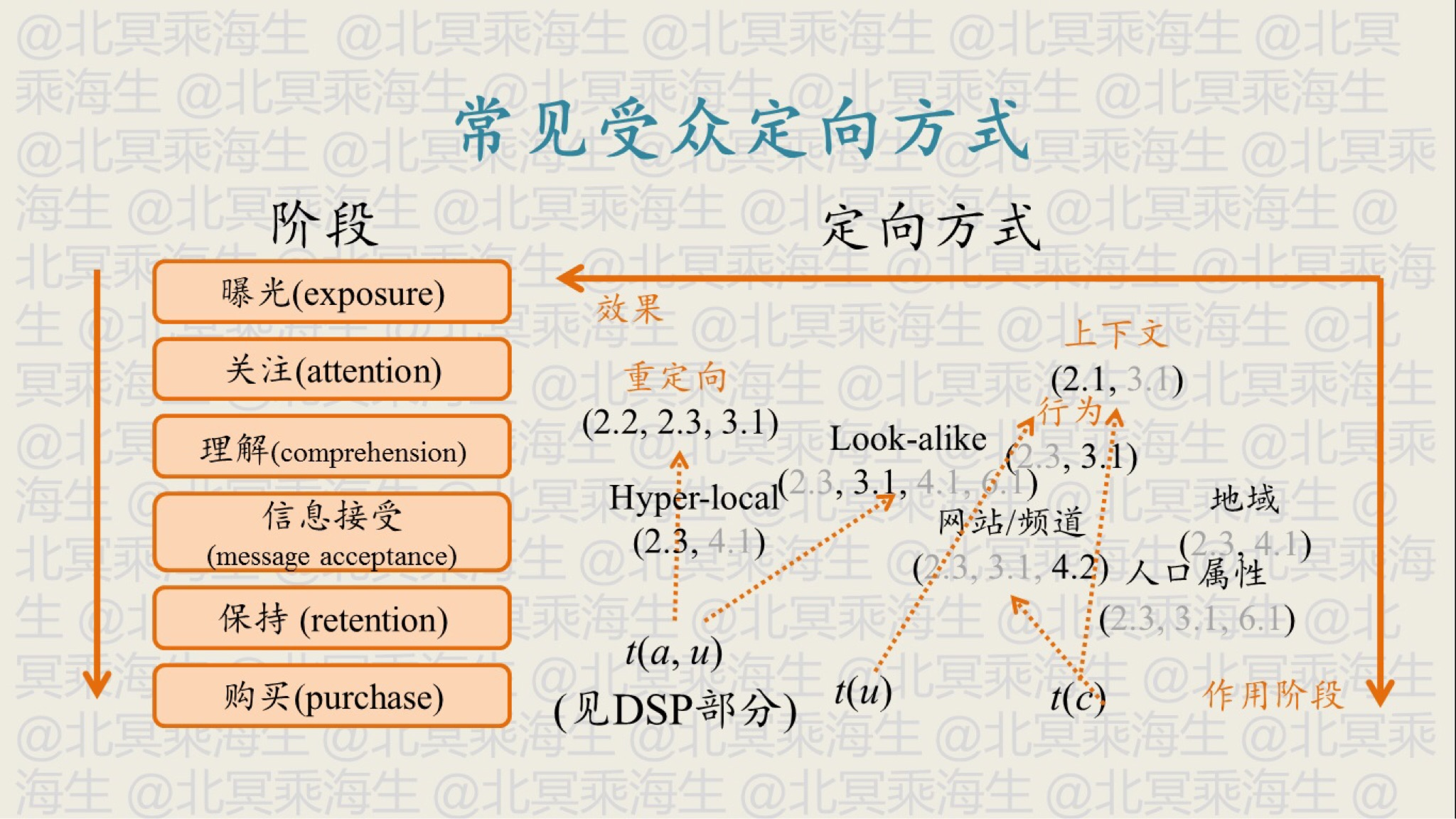
重定向只需要用到第一方数据 look-alike 需要用到第一方数据和第二方数据 s hyper-local 表示根据更精细的位置做定向 (移动端)
标签体系的建立
上面讲述了该在那些方面建立标签体系以及建立标签体系的方法,下面要讲一个重点的内容,就是该建立怎样的标签体系
如下图所示,标签体系可以分为两大类,其中一类是结构化标签,可以认为这一类的标签是一个大的树状结构;另外一类则是非结构化的,也就是根据效果和需求驱动的标签体系,关键词就是一个典型的非结构化标签体系。
这里需要注意的是,由于结构化标签结构上的完备性,往往会被大部分人采用,但是这种标签体系的效果未必就好,原因是这些结构化标签将重点放在了标签体系的完备性而往往忽略了广告主的具体需求。
结构化的标签体系的一个典型例子是雅虎的 GD 系统的标签体系,这个标签体系根据主观的判断来分类标签,并没有结合广告主的具体需求,在实际的效果并不好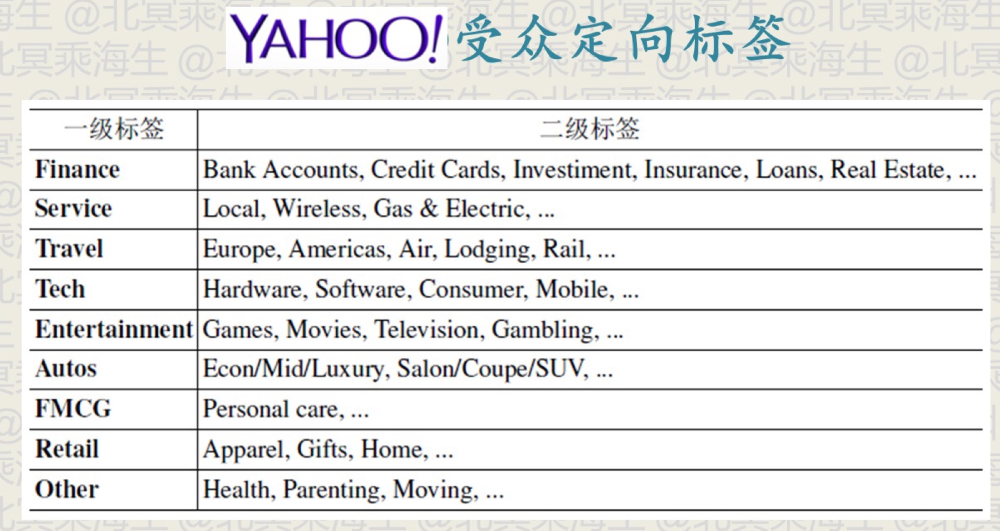
下面的标签体系中虽然形式上类似于结构化标签,但是是根据各个广告主的需求来定制各个标签的,因此是非结构化的,也更实用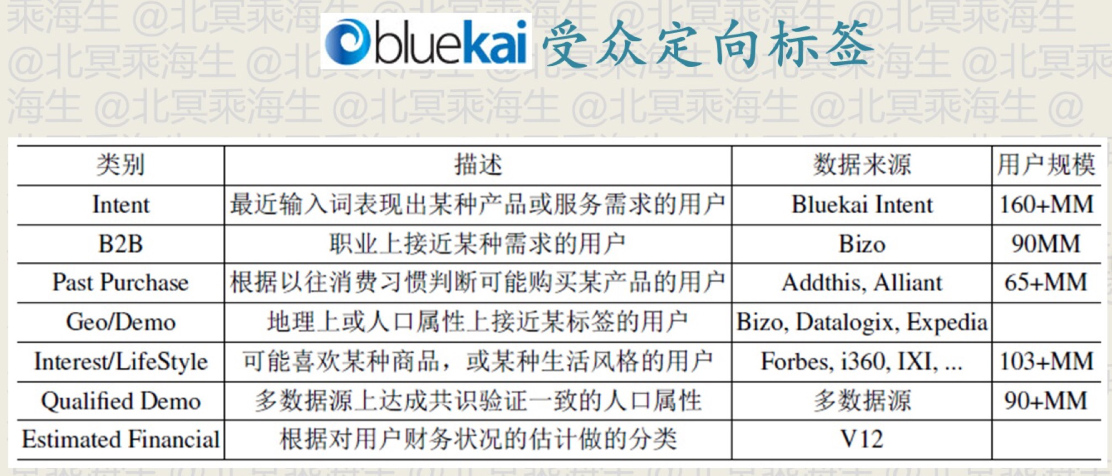
非结构化标签体系的建立过程如下 1)确定行业 2)了解行业里面用户的决策流程 3)根据决策流程定制各个流程中的标签
如对于汽车行业,一般用户购买时会先考虑预算 (价格区间标签),然后考虑车的用途(车型、大小等标签),最后考虑品牌(品牌标签)。
实际中,具体的标签可通过不同的方法获取,下文要讨论的行为定向中也提供了一种获取具体标签的方法。
行为定向
下面讲述受众定向中的一个重点:行为定向,就是根据用户的历史行为给用户打标签。
行为定向首先要将用户的各种行为转化为标签,同时对各种行为进行加权,如下图所示就是通过三种行为(广告点击,搜索,浏览)为用户打标签,其过程都是根据用户操作对象的具体内容提取出标签(关键词,主题等)并进行叠加。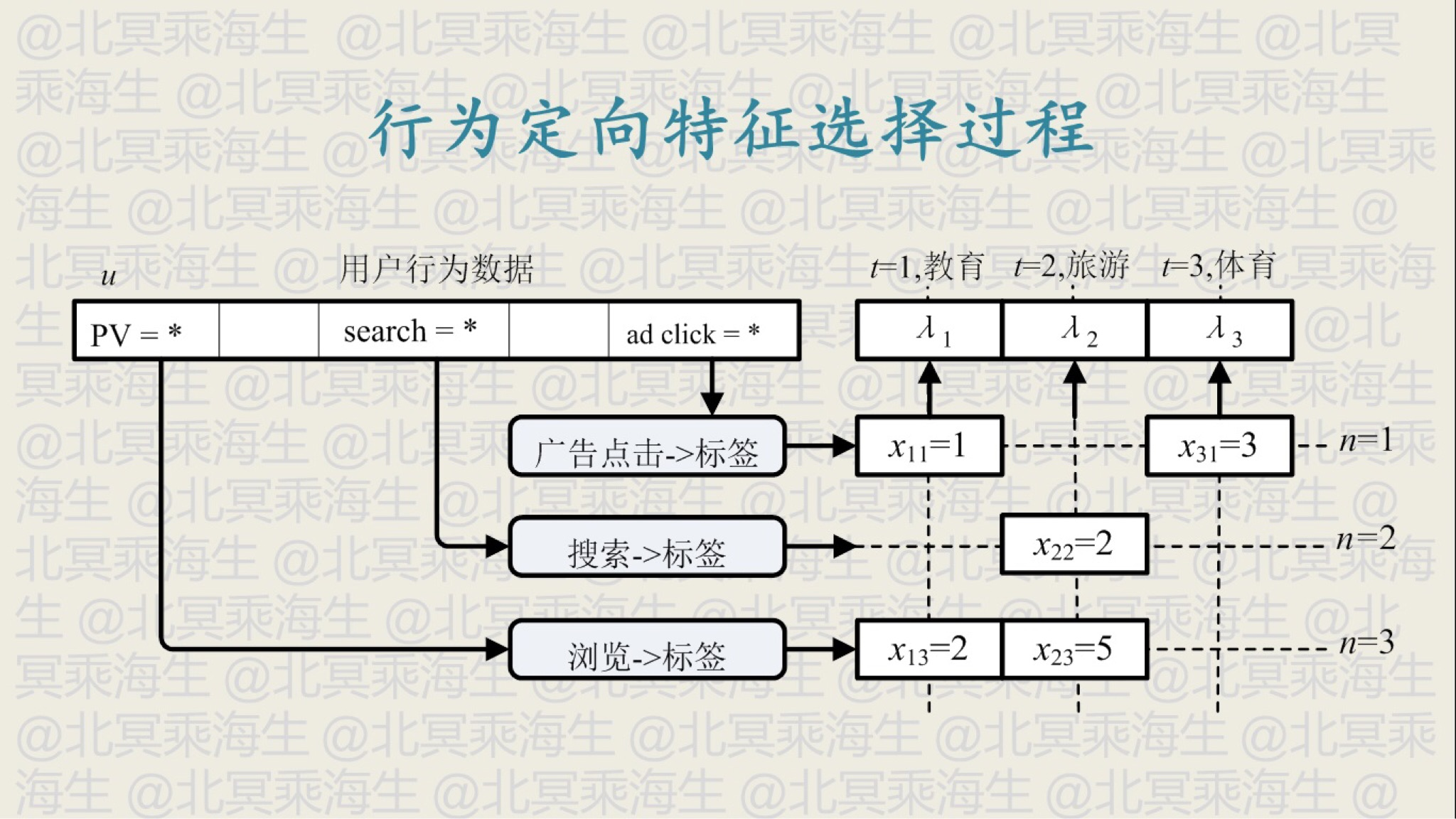
上面采用的方法并不复杂,其中一个很重要的原因就是行为定向的实时性要求,因为用户的行为的有效期一般不长,即从关注到最终的购买所持续的时间往往并不长,其次是因为要处理的用户的量级非常大。
此外,由于各种行为所反映的用户的意图不一,因此需要对不同行为进行加权,而且对于不同的标签,加权的方式还不完全一样,如下是对不同标签的不同行为加权的一种方法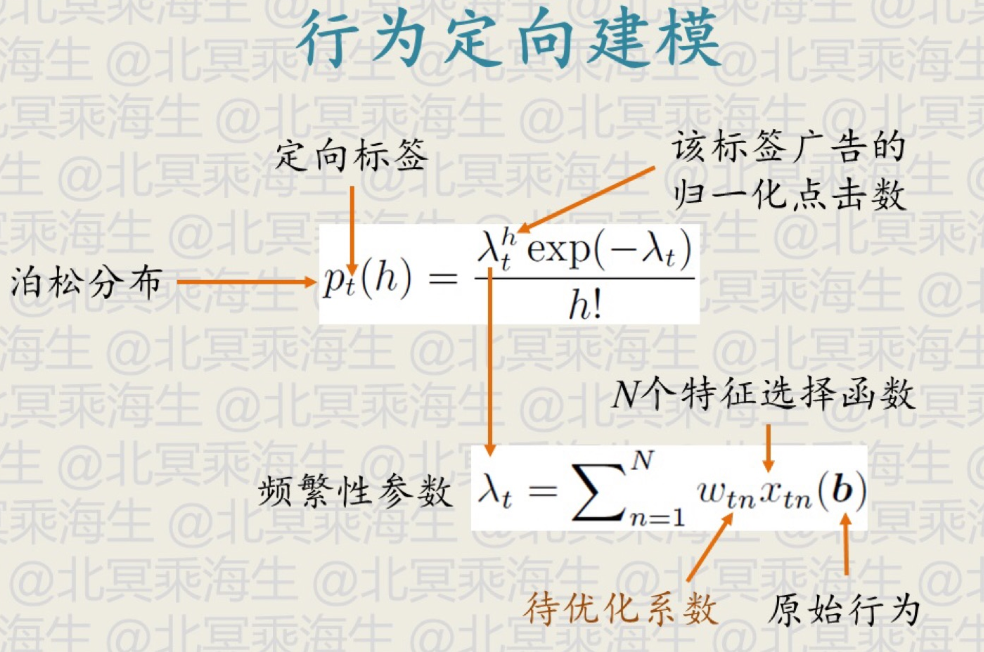
上面建模采用泊松分布来处理,因为泊松分布就是描述某段时间内,具体数量的事件发生的概率,如上式表示在时间 \(t\) 内,用户点击广告次数为 \(h\) 的概率。其中 \(\lambda\) 表示用户点击广告的频繁程度,也叫频繁性参数,该值越大,表示点击越频繁。
\(\lambda\) 可描述为各种原始行为的加权和, 其中 \(w_{tn}\) 为权重系数, \(x_{tn}\) 为原始行为(N 种,如浏览、搜索等)的统计量,求解时通过 \(h\) 的历史数量进行极大似然估计即可求出权重系数 \(w_{tn}\) ,然后直接在线上使用权重系数。
此外,上面式子中 \(t\) 表示对不同的标签建立不同的权重体系。
上图中将各类行为变为具体的标签方法有以下几种,主要思路是找到用户的行为对应的内容(一般是具体文本),然后借助 NLP 技术将内容转为标签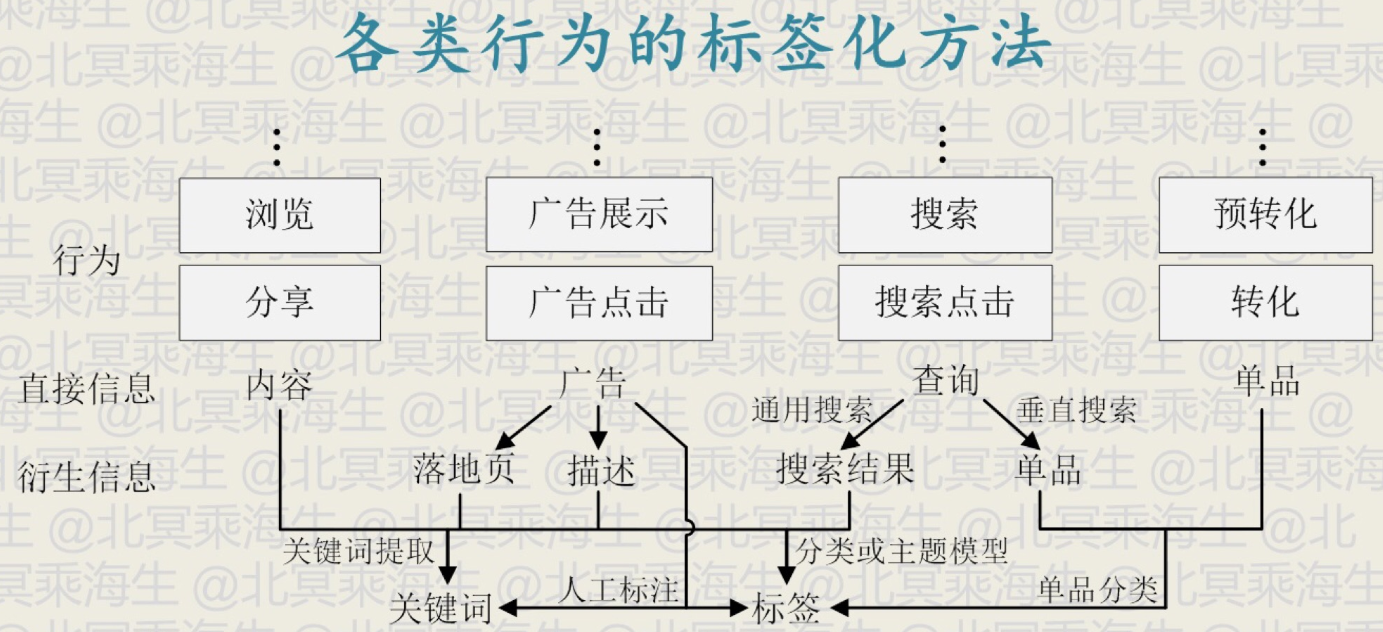
主要方法可以分为两种 1)针对浏览行为、点击行为,相应的都会有具体内容,如浏览的页面的内容,点击的广告的具体内容,通过 NLP 技术对内容提取关键词或主题分布,作为标签 2)针对搜索行为,可分为通用搜索和垂直搜索,要解决的问题都是如何将搜索关键词变为标签。对于通用搜索,可以利用已有搜索引擎(百度,谷歌等)模拟用户搜索行为,从得到的搜索结果作为内容,从中提取标签方法可以采用与第一种相同的 NLP 技术;对于垂直搜索,可以通过淘宝、携程、汽车之家等垂直搜索引擎,直接从关键词返回的结果中提取标签,因为像这种垂直搜索引擎一般都会自定义好一套标签了,因此这里是采用了垂直网站已经分好的类。
实际工程中,往往会从不同渠道获取用户不同的行为数据,将各种方式获取的日志整理在一起,称为 Session log。Session log 中一行表示一个用户的数据,这样通过 MapReduce 进行计算时,通过 map 过程即可完成某个用户的 targeting 过程,也就是下图中的局部计算。
除此之外,行为定向中往往要用到用户过去一段时间的数据(7 的整数倍,避免周六日带来的偏差),处理的数据是一个时间序列数据,处理的方法有以下两种:滑动窗口和时间衰减。
实际中一般采用时间衰减方式,因为时间衰减的方式计算的效率较高
场景定向
场景定向指的是判断出用户当前所处的场合和状态(地铁上、开会中、健身房等),针对的是移动设备。利用移动设备的传感器等搜集的信息,可以判断用户当前所处场景。
以早餐推送为例,根据用户当前的速度可以判断出用户是否在坐地铁,根据时间判断用户是要去上班,根据用户的位置可以为用户推荐附近的早餐店,实际上这是一个真实的例子,在东京的一次肯德基推广活动中,通过移动设备行为数据的分析,活动方准确找到了那些从地铁出来准备吃早餐的人群,实时给他们送出了早餐优惠券。
这里需要注意的是场景定向不是上下文定向,上下文定向针对的是媒体内容,而场景针对的是用户。
人口属性定向
人口属性定向中主要是要预测性别和年龄阶段,实际上就是分类问题
受众定向的评判标准
上述的受众定向的过程其实就是依据某个用户的各种历史行为,为该用户在所有的标签上打出一个分数,然后线上设定分数阈值,大于这个阈值则判断用户是这个标签的人群。因此一般来说阈值越大,标签人群越少,但是结果也会越可信。
下图展示了该如何评测受众定向的有效性,横轴表示被打上标签的人群的比例,纵轴表示被打上标签的人群对广告的点击率,一般来说,某个标签圈定的人数越少,效果越好,也就是点击率越高,违反了这一变化规律则说明受众定向不起作用。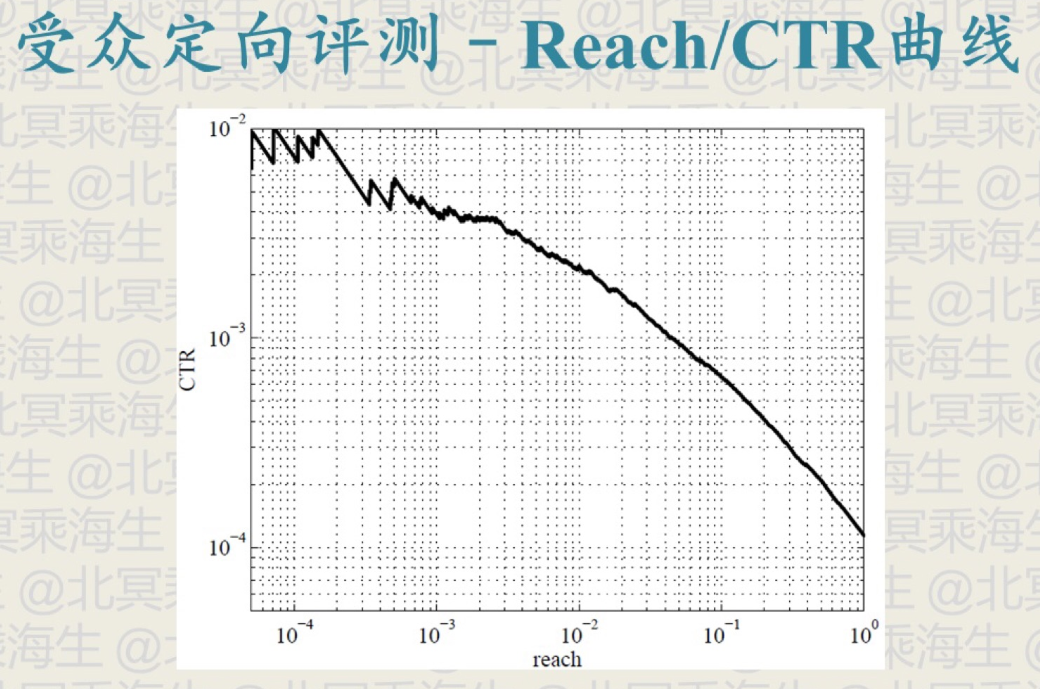
综上,本文主要讲了受众定向中的行为定向
- 确定具体行业
- 研究行业用户决策过程,制定用户标签体系
- 制定标签体系不要刻意追求规整、结构化的标签体系
- 把用户的原始行为映射到标签体系中,并求出各种行为类型的权重
- 根据 4 可为用户在各个标签上打出一个分数,为标签设定阈值,则通过比较分数和阈值可以判断用户是否属于该标签人群
- 通过 Reach / CTR 曲线评测定向是否有效