2017 小结
一个多月没写文章了,这个月主要是被各种焦头烂额的事情所烦扰:比赛、数据的采集与筛选、各种无聊的报告等等。一眨眼就踏入了 2018,本来也不打算写年度总结,但是后来想想还是做一下简单的记录,一是因为自己本来就有总结的习惯,要不也不会一直在写这个博客;二是因为不总结下,都不知道自己这一年过得有多烂(捂脸)。言归正传,下面主要写一下在这一年里干了啥。
关于课程
研究生的第一年还是以上课为主,当初从电信转到计算机一个原因就是对计算机更有兴趣,所以这一年的课程也是学得挺顺利的。计算机的基本素养课程:操作系统、计算机网络和数据库都有,虽然本科上过,但是研究生的课是对某些知识点进行了更深入的讲解,操作系统和计算机网络都在本站点上做了相应的总结,虽说当时总结起来一顿操作猛如虎,考试也考了 90+,但是现在的内容却忘得七七八八了,似乎是水过鸭背。但我还是觉得这个东西虽然不能被我清晰记起,但是当要再次捡起来的时候,还是会比较快的。现在回想如果我本科时候没那么认真学习操作系统和计算机网络,研究生这两门课也不会学得这么顺利,知乎有个高票答案就说到知识或者技能这种东西,学到了就跟你一辈子,也许说的就是这种情况吧。
除了这几门常规课,其他让我觉得最有用的两门课就是 最优化基础 和 凸优化了,两门都是关于优化的数学课,以往基本没接触过,搞数学建模的时候接触过一点线性规划,这里则是更详细地介绍了各种优化问题和解决方法。非常有用的两门课,尤其是对于我这种接触过机器学习和计算广告的人,因为从本质上来讲,这种优化思想在生活中无处不在:资源往往是有限的,我们总是想借助着有限的资源来最大化我们所希望的获取的利益。 将这类问题量化成一个最优化的问题,就有了一个目标,然后通过优化算法,就有了一个方向,这样或早或晚都能走到局部最优或全局最优。
还有一门就是模式分类,这门课是跟本科生一起上的,因此讲的内容并不是很深入,都是传统的机器学习算法,但是让我收获最大的是课程论文的阅读,读的论文是 12 年提出 AlexNet 的经典论文 ImageNet Classification with Deep Convolutional Neural Networks,当时为了讲好 PPT,做了较多的调研,还写了阅读笔记,这篇论文涵盖了很多深度学习的重要概念,毕竟是开山之作。详细了解了这篇论文后使得我后面上手深度学习的项目时比较快,还是印证了前面的那句话:知识或者技能这种东西,学到了就跟你一辈子。
学校安排的课程中,能被我记住的基本就是上面提到的,其他的那些如上得不痛不痒的数据库,让人备受煎熬的中特,都没有多大印象了。这一年的课程成绩也还可以,最后的评优中虽然没有专利、活动之类的加分,但是因为成绩优势,最终也拿了一等奖学金,比刚入学时候的二等奖学金要好了,虽然我觉得如果我不跨院保研的话入学的时候也能拿一等(捂脸逃)。
除了学校的课程,主要还学习了与机器学习和计算广告相关的课程。
机器学习的几门课程包括吴恩达在斯坦福的公开课,台大林轩田的机器学习基石和机器学习技法;这几门课都是理论为主,数学偏多,硬着头皮也算啃了下来,其中让我印象最为深刻的不是各种各样的模型算法,而是 NFL (No Free Lunch) 定理和 VC 维理论,NFL 定理指出了模型之间并的差距必须要到某一个具体的数据集上才能体现出来,也就是说要解决一个机器学习问题时,必须要先对数据的分布等信息有较好的理解,才能选出适合这个数据的模型;VC 维理论需给我们揭示了一个很直观的概念:要取得较好的泛化能力,用于训练模型的样本数目应该至少是模型参数数目的 10 倍。这个能够很好的解释复杂模型容易过拟合的问题。但是对于目前如火如荼的深度学习,VC 维理论并不适用,因此 2017 ICLR 的最佳论文 Understanding deep learning requires rethinking generalization 通过实验指出了这个问题,同时深度学习目前也还没有公认的理论基础,因此这个问题也是亟需解决。
计算广告算是今年看到的一门比较新的课程,之前对广告的认知只限于弹窗、强制推送等,后来看了刘鹏的计算广告学,才发现这门学科集理论知识(主要是优化方面)和工程技法于一体,而且广告可以说是大数据为数不多的正真落地的一个产业。看了视频后又买了跟视频配套的书计算广告又看了一遍,对于书中众多概念及需要解决问题才有了初步了解。
这两方面的课程的内容虽然都看完了一遍,也做了一些笔记,但是还是感觉理解得还不够深入,还要重温一遍。
关于项目
研一基本在上课,直到研一的暑假才被大老板叫去做项目,之前一直是跟小老板做 NLP 方向的研究,但是大老板的项目是图像相关的,具体的就是做人脸的表情识别。由于很久没接触图像相关知识了,刚开始还有点害怕做不来。但是后来才发现有了一些机器学习的知识,上手也是挺快的。
在这个过程中,对比了人工特征 + 传统机器学习方法和深度学习方法,传统的人工特征基本就是人脸的 68 个特征点以及特征点衍生出来的特征,在几个数据集上深度学习的效果基本上都要优于传统的机器学习方法,也许是我们提特征不够好,但是这也是深度学习的强大之处,将特征抽取和分类器的训练融合到一个模型中。
暑假做了大概一个月的算法研究,开学后被派去搭建系统了,主要就是实现从监控获取图像,对图像中的人脸进行表情识别并可实时观察具体的识别效果。首先要解决的是数据传输问题,就是图像从摄像头传到服务器,服务器处理后送到展示端,展示端为了维护的便利性,采用的网页展示方式。因为之前已经听说过 kafka 这个工具,知道这个工具的大概作用,因此这里就做了一下调研,没想到这个工具还是挺好用的,吞吐量高且拓展性强,部署起来也不麻烦,因此系统中有数据传输的部分都用了 kafka,需要存储的部分用了 redis,在数据传输存储中将图像按照 base64 编码后,能够避免很多问题。而网页端的显示则是用了 multipart/x-mixed-replace 这个 content type,简单来说这个 content type 能够替换掉原位置上的数据,如果将图像一帧一帧地传过来,便可达到动态视频的效果。
下面是具体效果
在这个过程中需要用到人脸检测、图像处理的工具,因此也接触了 opencv, dlib 这两个功能强大的库, 在人脸检测上 dlib 的效果要优于 opencv,opencv 则主要用在图像处理,如标注、裁剪等。
后面由于模型在已有的数据集 (如 CK+, KDEF 等) 上的效果很好,但是人肉测试时效果并不好,因此就考虑数据扩充,除了常规的在已有的数据集上进行裁剪、翻转、颜色抖动等操作。还通过爬虫在网上采集人脸数据库,主要就是通过关键词在谷歌中搜索对应的图片,然后获取其下载链接并下载图片,这个小工具已开源,具体地址见
https://github.com/WuLC/GoogleImagesDownloader
通过这个工具搜集了一定数量的图片,通过预处理和人工筛选后得到最终的图片,其中人工筛选过这个步骤由于每个人的标准都不一样,因此最后出现某些类别很少的情况。但是在一定程度上也算是扩充了原有的数据集(7 种类别仅有 2000 多张图片)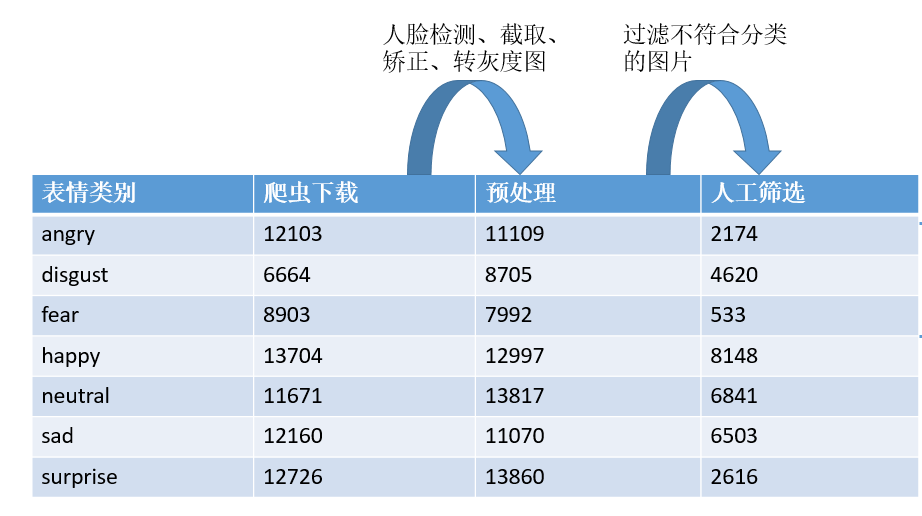
因为之前的测试都是内部的测试,没有一个对比的标准,因为我们做的这个项目是以实用性为主,而目前提供表情识别服务且比较有名公司有 微软、谷歌、Face++、竹间智能等,因此就想到到了构建一个公有的数据集,来对比一下我们的模型和商用的差距。经过讨论后,决定去采集真实的人脸表情,这样一来所有的模型都不可能接触过这些数据集,因而能够比较公平地验证各个模型的泛化能力。因此就用 python 写了一个采集程序,去采集一个人的 7 种表情,并以视频形式存储。下图是采集的页面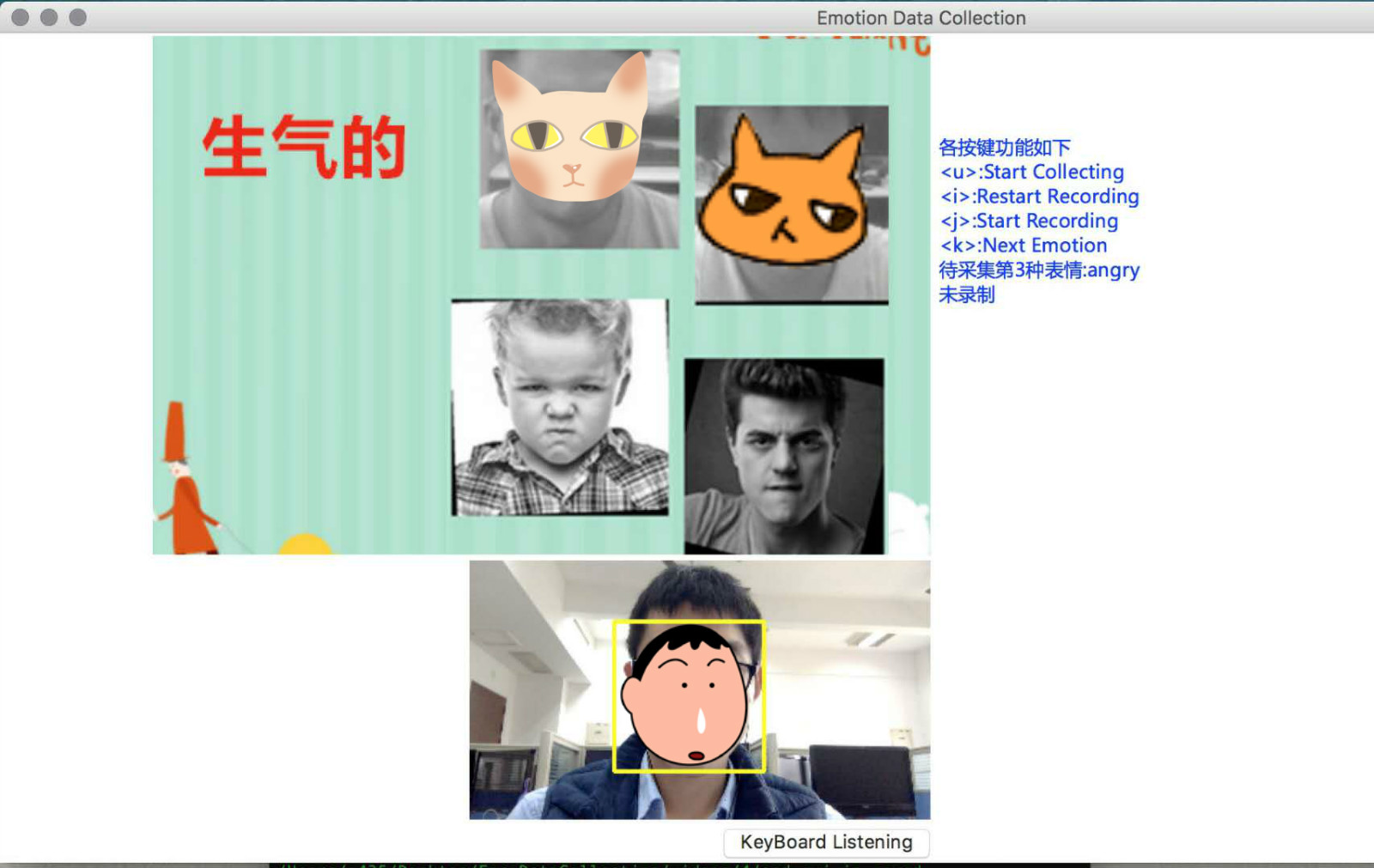
采集完了需要将视频转为图像帧序列,然后人工选出若干帧作为表情变化序列进行后续操作。不得不说人工筛选就是累。
采集完验证集后,测试了上述的四个提供表情识别服务的公司的 API 在验证集上的准确率,结果显示准确率大概在 52%~58%(七分类) ,我们的模型最好的效果能达到 61%,且通过 confusion matrix 可以看到所有模型基本上都有这个问题,就是 angry、fear、disgust、sad 这几类表情被误分为 neutral,原因就是正常人在做这些表情的时候幅度并不会太大,而训练集中的数据却都是动作幅度较大,表情比较明显。
最后,还需要将从监控中获取到的不同人脸分来,就是一个人脸聚类问题。最开始采用的是人脸识别经典做法,就是每个人采用已知的人脸图片,然后通过预训练的 FaceNet 抽取图像的 128 维特征,对于未知的人脸图片,也用 FaceNet 抽取出 128 维特征,并和已知人脸的 128 维特征计算相似度,这种做法对于人脸的角度鲁棒性不好,就是只能识别出与已知的人脸图片中人脸角度差别不大的人脸。后来改用了 Chinese whispers 聚类算法,同样也是要通过预训练的 FaceNet 抽取图像的 128 维特征,但是不需要提供已知的人脸图片,且算法对于人脸角度的鲁棒性较好。
去年就只做了这个项目,虽然做的内容比较杂,但是也算是学到了不少东西。
关于比赛
上课的时候参加了一些比赛,但是由于课程作业、考试等原因,基本都半途而废;暑假以后主要参加了两个比赛:AI Challenger 的图像中文描述 和 CCF 的计算智能大赛。
参加第一个比赛主要是这个方向可能是我的毕设方向,通过这个比赛,也算是基本入门了这个方向,代码主要是参考了 tensorflow 中提供的 im2txt 例子,基本看懂后做了一些改动,代码见这里,参数没有细调,因为到后面去搞 CCF 的比赛了, 最后 B 榜大概 30 名左右 。
CCF 的比赛中主要参加了法海风控的比赛,做的是命名实体识别 + 文本分类,我主要负责的是文本分类,就是判断抽取出来的实体到底是正向、负向还是中性的,尝试了一些开源的工具,也实现了一些模型如 TextCNN 等,综合效率和准确率,fastText 是最好的,了解这个工具也是我觉得是比赛中一个较大的收获。比赛过程很繁琐,最终以 Top5 的成绩去了江苏答辩,最后第四名,也算是收获了一个奖项。
总的来说,2017 年里主要完成的就是上面这三个方面的事了,其他琐碎的也基本记不起。2018 就要找工了,时间真的过得好快, 希望在 2018 里能够继续保持 stay hungry,stay foolish 的状态吧。