通过 word2vec 与 CNN / RNN 对动作序列建模
本文主要讲述如何通过 word2vec 和 CNN / RNN 对动作序列建模,在最近的一个比赛中验证了这个思路,的确有一定效果,在二分类的准确率上能达到 0.87. 本文主要介绍这个方法的具体步骤,并以比赛和代码为例进行说明。
这里提到的比赛是目前正在进行的精品旅行服务成单预测, 该比赛就是要根据用户的个人信息,行为信息和订单信息来预测用户的下一个订单是否是精品服务。本文提到的方法是仅利用用户的行为信息,主要的思路是:将每个动作通过 word2vec 转化为 embedding 表示,然后将动作序列转化为 embedding 序列并作为 CNN / RNN 的输入。 下面依次介绍通过 word2vec 获得动作 embedding,将 embedding 作为 CNN 的输入和将 embedding 作为 RNN 的输入这三部分内容。
word2vec 获取动作 embedding
word2vec 是一个很著名的无监督算法了,这个算法最初在 NLP 领域提出,可以通过词语间的关系构建词向量,进而通过词向量可获取词语的语义信息,如词语意思相近度等。而将 word2vec 应用到动作序列中,主要是受到了知乎上这个答案的启发。因为 word2vec 能够挖掘序列中各个元素之间的关系信息,这里如果将每个动作看成是一个单词,然后通过 word2vec 得出每个动作的 embedding 表示,那么这些 embedding 之间会存在一定的关联程度,再将动作序列转为 embedding 序列,作为 CNN 或 RNN 的输入便可挖掘整个序列的信息。
这里训练动作 embedding 的方法跟训练 word embedding 的方法一致,将每个户的每个动作看做一个单词、动作序列看做一篇文章即可。训练时采用的是 gensim, 训练的代码很简单,embedding 的维度设为 300, filter_texts中每一行是一各用户的行为序列,行为之间用空格隔开。1
2
3from gensim.models import word2vec
vector_length = 300
model = word2vec.Word2Vec(filter_texts, size = vector_length, window=2, workers=4)
由于动作类型只有 9 种(1~9),也就是共有 9 个不同的单词,因此可将这 9 个动作的 embedding 存在一个 np.ndarray 中,然后作为后面 CNN / RNN 前的 embedding layer 的初始化权重。注意这里还添加了一个动作 0 ,原因是 CNN 的输入要求长度一致,因此对于长度达不到要求长度的序列,需要在前面补 0(补其他的不是已知的动作也可以)。代码如下1
2
3
4import numpy as np
embedding_matrix = np.zeros((10, vector_length))
for i in range(1, 10):
embedding_matrix[i] = model.wv[str(i)]
CNN 对动作序列建模
CNN 采用的模型是经典的 TextCNN, 模型结构如下图所示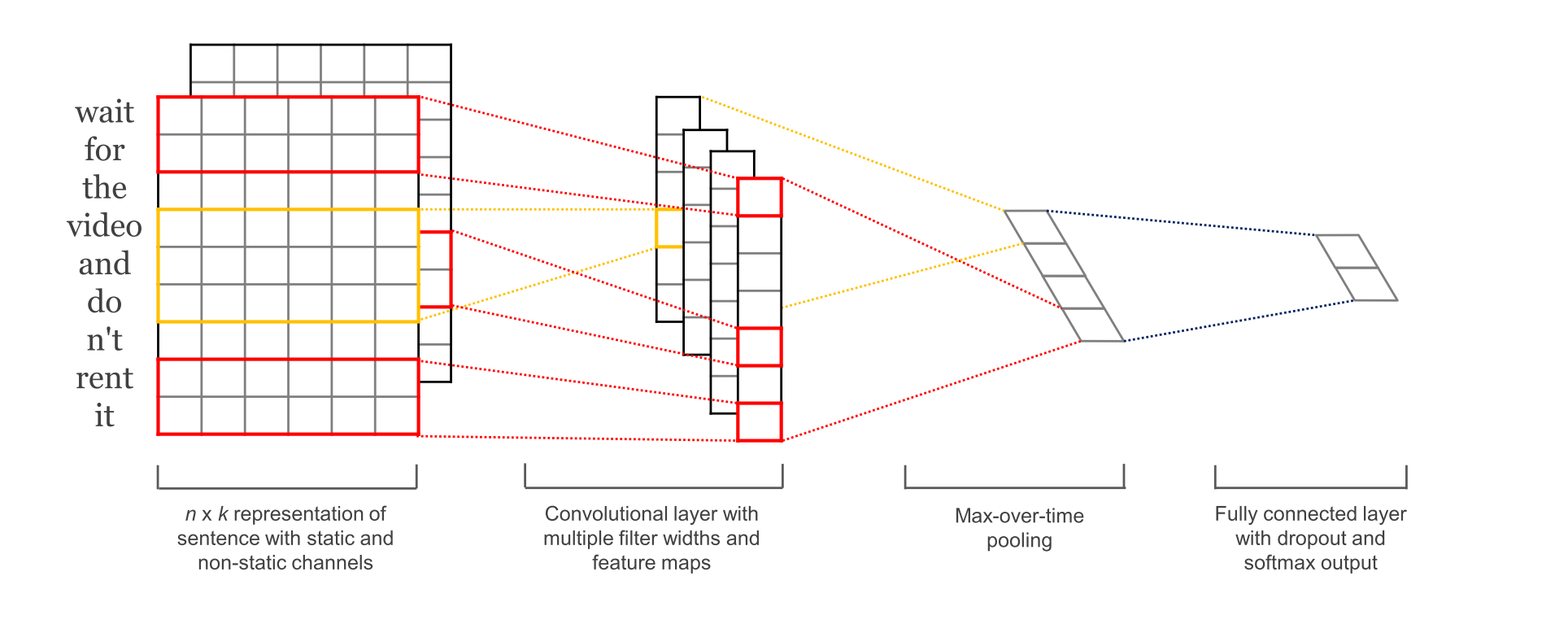
这里通过 Keras 实现,具体代码如下
首先需要处理序列,使得所有序列长度一致,这里选择的长度是 50,具体代码如下,代码中的 x_original 是一个 list[list[int]] 类型,表示所有用户的所有动作序列,对于长度比 max_len 长的,从后往前截取 50 个最近时间的动作,而短的则在前面补 0.1
2
3
4
5from keras.preprocessing import sequence
max_len = 50
x_train = sequence.pad_sequences(x_original, maxlen=max_len)
y_train = np.array(y_original)
print(x_train.shape, y_train.shape)
然后通过前面得到的 embedding_matrix 初始化 embedding 层1
2
3
4
5
6
7
8
9
10from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Input, MaxPooling1D, Convolution1D, Embedding, BatchNormalization, Activation
from keras.layers.merge import Concatenate
from keras import optimizers
embedding_layer = Embedding(input_dim=embedding_matrix.shape[0],
output_dim = embedding_dim,
weights=[embedding_matrix],
input_length=max_len,
trainable=True)
然后建立模型并训练, 这里用了四种不同步长的卷积核,分别是 2、3、5、8,比起原始的 TextCNN, 用了两层的卷积层 (在这个任务上经过测试比一层的要好), 后面的全连接层也拓展到了三层,具体代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44NUM_EPOCHS = 100
BATCH_SIZE = 64
DROP_PORB = (0.5, 0.8)
NUM_FILTERS = (64, 32)
FILTER_SIZES = (2, 3, 5, 8)
HIDDEN_DIMS = 1024
FEATURE_DIMS = 256
ACTIVE_FUNC = 'relu'
sequence_input = Input(shape=(max_len, ), dtype='int32')
embedded_seq = embedding_layer(sequence_input)
# Convolutional block
conv_blocks = []
for size in FILTER_SIZES:
conv = Convolution1D(filters=NUM_FILTERS[0],
kernel_size=size,
padding="valid",
activation=ACTIVE_FUNC,
strides=1)(embedded_seq)
conv = Convolution1D(filters=NUM_FILTERS[1],
kernel_size=2,
padding="valid",
activation=ACTIVE_FUNC,
strides=1)(conv)
conv = Flatten()(conv)
conv_blocks.append(conv)
model_tmp = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
model_tmp = Dropout(DROP_PORB[1])(model_tmp)
model_tmp = Dense(HIDDEN_DIMS, activation=ACTIVE_FUNC)(model_tmp)
model_tmp = Dropout(DROP_PORB[0])(model_tmp)
model_tmp = Dense(FEATURE_DIMS, activation=ACTIVE_FUNC)(model_tmp)
model_tmp = Dropout(DROP_PORB[0])(model_tmp)
model_output = Dense(1, activation="sigmoid")(model_tmp)
model = Model(sequence_input, model_output)
opti = optimizers.SGD(lr = 0.01, momentum=0.8, decay=0.0001)
model.compile(loss='binary_crossentropy',
optimizer = opti,
metrics=['binary_accuracy'])
model.fit(x_tra, y_tra, batch_size = BATCH_SIZE, validation_data = (x_val, y_val))
由于最后要求的是 auc 指标,但是 Keras 中并没有提供,而 accuracy 与 auc 还是存在一定差距的,因此可以在每个 epoch 后通过 sklearn 计算 auc,具体代码如下1
2
3
4
5
6from sklearn import metrics
for i in range(NUM_EPOCHS):
model.fit(x_tra, y_tra, batch_size = BATCH_SIZE, validation_data = (x_val, y_val))
y_pred = model.predict(x_val)
val_auc = metrics.roc_auc_score(y_val, y_pred)
print('val_auc:{0:5f}'.format(val_auc))
这种方法最终的准确率约为 0.86,auc 约为 0.84
RNN 对动作序列建模
通过 RNN 进行建模与 CNN 类似,不同的是 RNN 可接受不同长度的输入,但是根据这里的说明,对于输入也需要 padding 的操作,只是 RNN 会将其自动忽略。
因此,数据的预处理和构建 embedding 层的代码与 CNN 中基本一致,这里只给出建立模型的代码,模型比较简单,首先是将输入通过 embedding 层的映射后,作为以 LSMT / GRU 为基础单元构建的 RNN 的输入, 最后通过 sigmoid 进行分类,具体代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# RNNs are tricky. Choice of batch size is important,
# choice of loss and optimizer is critical, etc.
model = Sequential()
model.add(embedding_layer)
model.add(Bidirectional(LSTM(256, dropout=0.2, recurrent_dropout=0.2)))
# model.add(LSTM(256))
# model.add(Bidirectional(GRU(256)))
model.add(Dense(1, activation='sigmoid'))
opti = optimizers.SGD(lr = 0.01, momentum=0.8, decay=0.0001)
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
通过 RNN 得出的最终效果比 CNN 要好一点,准确率约为 0.87,auc 约为 0.85。但是训练起来非常慢,且参数非常的 tricky,需要精调,这里我没有细调参数,模型也没有搞得很复杂,应该还有提升空间。
综上,本文提供了一种对动态序列建模的思路:将动作序列通过 word2vec,得到每个动作的 embedding 表示,然后将动作序列转化为 embedding 序列并作为 CNN / RNN 的输入。希望能够起到抛砖引玉的作用,如果您有更好的想法,欢迎交流。