分布式机器学习 (1)-A New Era
这个分布式机器学习系列是由王益分享的,讲的是分布式机器学习。正如作者在分享中所说,分布式机器学习与我们今天常听到的机器学习存在比较大的差异,因此分享中的很多观点跟我们从教课书上学到的机器学习是背道而驰的。作者在这方面具有丰富的经验,虽然是三年前的分享,或许分享中提到的部分技术改变了,但是其中的一些观点还是具有一定参考价值的。
笔者对于分享中的一些观点也是存在疑惑的,这里还是按照分享中作者表达的意思记录下来, 也许等到笔者工作后,才有机会去验证这些观点的正误。
本文主要介绍了分布式机器学习中的一些重要概念,如互联网的真实数据是长尾分布的、大比快要重要、不能盲目套用一个框架等,本文对应的视频在这里,需要自备梯子。
机器学习与分布式机器学习
机器学习最重要的是数学知识,而这里的分布式机器学习更关注的是工程技法。且一般的机器学习模型假设数据是指数簇分布,而实际的数据是长尾分布的,分布式机器学习需要去对长尾的数据进行建模,对于这点,后面会有详细的描述。
长尾效应
根据维基百科,长尾指的是指那些原来不受到重视的销量小但种类多的产品或服务由于总量巨大,累积起来的总收益超过主流产品的现象。在互联网领域,长尾效应尤为显著。下图所示黄色的部分就是长尾部分,之所以要关注长尾的数据,是因为长尾的数据的量并不小,蕴含着重要的价值
以互联网广告为例,长尾现象指的是有大量频次低的搜索词,这些搜索词并非为大多数人所了解。如搜索 “红酒木瓜汤” 时不应该出红酒、木瓜或者汤的广告,因为这个是一个丰胸健美类的产品,这就是一个长尾的搜索词。
另外一个例子如下所示,下图是从 Delicious 的网页中挖掘出的一些频繁项集,最左边便是这个频繁项集,最右边表示这个频繁项集在所有网页(数亿)中出现的次数,可以看到这些频繁项集是长尾的数据了,然而,这些数据都是有具体意义的。
大比快重要
并行计算关注的是更快,而分布式机器学习关注的则是更大,因为数据是长尾的,要涵盖这些数据中的长尾数据,首要的处理的是首先是大量的数据。
在讲述下文前,需要先说明几个概念,Message Passing 和 MapReduce 是两个有名的并行程序编程范式(paradigm),也就是说,并行程序应该怎么写都有规范了 —— 只需要在预先提供的框架(framework)程序里插入一些代码,就能得到自己的并行程序。Message Passing 范式的一个框架叫做 MPI。MapReduce 范式的框架也叫 MapReduce。而 MPICH2 和 Apache Hadoop 分别是这 MPI 和 MapReduce 两个框架的实现(implementations)。
对于框架而言,其中重要的一点是要支持 Fault Recovery,简单来说就是要支持失败的任务的回滚。MPI 无法实现 Fault Recovery,这是因为 MPI 允许进程之间在任何时刻互相通信。如果一个进程挂了,我们确实可以请分布式操作系统重启之。但是如果要让这个 “新生” 获取它 “前世” 的状态,我们就需要让它从初始状态开始执行,接收到其前世曾经收到的所有消息。这就要求所有给 “前世” 发过消息的进程都被重启。而这些进程都需要接收到他们的 “前世” 接收到过的所有消息。这种数据依赖的结果就是:所有进程都得重启,那么这个 job 就得重头做。
虽然很难让 MPI 框架做到 fault recovery,我们可否让基于 MPI 的应用系统支持 fault recovery 呢?原则上是可以的 —— 最简易的做法是做 checkpoint—— 时不常的把有所进程接收到过的所有消息写入一个分布式文件系统(比如 HDFS)。或者更直接一点:进程状态和 job 状态写入 HDFS。
与 MPI 相反的框架是 MapReduce,MPI 容许进程间在任意时刻互相通信,MapReduce 则只允许 进程在 Map 和 Reduce 间的 shuffle 进行通信,MPI 几乎能够将所有的机器学习算法并行化,而部分复杂的算法无法通过 MapReduce 实现。
一些坑
这里是作者认为一些需要避开的坑, 下面选择几个展开说明
De-noise data
这里的 noise data 指的是将数据中出现频率不高的数据,将这些数据去掉,根据前面讲的长尾,这相当于是将长尾的尾巴截掉了,因此会丢失大部分有用的数据。
为什么不能将长尾的尾巴割掉,作者在 描述长尾数据的数学模型 这篇文章是这么说的
那条长尾巴覆盖的多种多样的数据类型,就是 Internet 上的人生百态。理解这样的百态是很重要的。比如百度和 Google 为什么能如此赚钱?因为互联网广告收益。传统广告行业,只有有钱的大企业才有财力联系广告代理公司,一帮西装革履的高富帅聚在一起讨论,竞争电视或者纸媒体上的广告机会。互联网广告里,任何人都可以登录到一个网站上去投放广告,即使每日广告预算只有几十块人民币。这样一来,刘备这样织席贩屡的小业主,也能推销自己做的席子和鞋子。而搜索引擎用户的兴趣也是百花齐放的 —— 从人人爱戴的陈老师苍老师到各种小众需求包括 “红酒木瓜汤”(一种丰胸秘方,应该出丰胸广告)或者 “苹果大尺度”(在搜索范冰冰主演的《苹果》电影呢)。把各种需求和各种广告通过智能技术匹配起来,就酝酿了互联网广告的革命性力量。这其中,理解各种小众需求、长尾意图就非常重要了。
Parallelize models in papers and textbooks
教科书或 paper 中的模型无法应用到大数据环境下,原因是教科书上的模型假设数据是指数簇分布(Exponential family)的,而真实的数据是长尾分布(Long tail)的。
用指数簇分布的模型去拟合长尾分布的数据,会有什么后果?答案就是会将长尾数据的尾巴给割掉了。比如说对于 pLSA 和 LDA 这两个 Topic model,如果大家尝试着把训练语料中的低频词去掉,会发现训练得到的语义和用全量数据训练得到的差不多。换句话说,pLSA 和 LDA 模型的训练算法没有在意低频数据。
目前大部分的数学模型都假设数据是指数簇分布的,如 Topic model 中的 LDA 和 PLSA 其先验分布和后验分布均是指数簇分布,像 SVD 这种矩阵分解的方法也做了高斯分布的假设,而像 Linear Regression 这类方法,从损失函数可以看到也倾向于优化数量多的样本。
既然如此,为什么这类模型还要假设数据是指数族分布的呢?,作者在 描述长尾数据的数学模型 中是这么说的 > 这么做实在是不得已。指数族分布是一种数值计算上非常方便的数学元素。拿 LDA 来说,它利用了 Dirichlet 和 multinomial 两种分布的共轭性,使得其计算过程中,模型的参数都被积分给积掉了(integrated out)。这是 AD - LDA 这样的 ad hoc 并行算法 —— 在其他模型上都不好使的做法 —— 在 LDA 上好用的原因之一。换句话说,这是为了计算方便,掩耳盗铃地假设数据是指数族分布的。
因此,要对长尾建模,作者提到,Dirichlet process 和 Pitman-Yor process 是一个可能的新方向。
Use existing frameworks
MPI 和 MapReduce 是两个极端,介于两者之间的是 Pregel(google),spark 等框架,这些主要思想就是在磁盘上做 checkpooint 从而实现灵活的通信和有效的 Recovery。
像 PageRank 这种算法在这些框架上能 work,但是像 LDA 这种通信量大的算法,做 checkpoint 时需要写入磁盘,会导致 buffer 过大,进而出现 out of memeory 的情况。因此,并不能通过一个通用的计算框架来解决所有问题。
下面是一些被广泛使用的开源框架,需要注意的是,在设计机器学习系统时,需要权衡效果与代价,选择甚至是开发合适的框架
- MPI
- MapReduce
- Pregel
- GraphLab
- Spark
另外一个需要注意的问题就是不要将计算框架和分布式操作系统混在一起,如 Hadoop 1.0 设计中将集群管理系统和分布式计算框架混合在一起就显得非常混乱,因此在 2.0 中出现了 Yarn 这个分布式操作系统专门负责任务的调度。
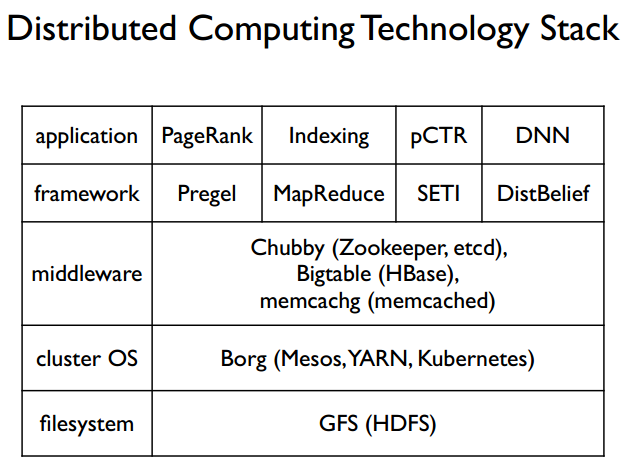
分布式机器学习技术栈
最后这张图是分布式技术栈,从下到上依次涵盖了分布式文件系统,分布式操作系统,一些中间件,分布式计算框架,以及构构建在这套分布式系统上的应用。由于是 15 年的视频了,因此相应的技术也会有所改变,至少我所知的 DNN 的 framework 已经是 tensorflow,pytorch,caffe,mxnet 等占主流了。
参考
分布式机器学习系列讲座 - 00 A New Era 分布式机器学习的故事:评价标准 分布式机器学习的故事:pLSA 和 MPI 描述长尾数据的数学模型