分布式机器学习 (2)-Infrequent Pattern Mining using MapReduce
这一讲主要介绍了挖掘频繁项集中的经典方法 FP-growth,以及如何通过 MapReduce 实现这个算法,通过 MapReduce 实现的 FP-growth 也称为 PFP,这个方法不仅能够挖掘频繁项集,还能够挖掘非频繁项集。原视频在这里,需要自备梯子。
频繁项挖掘
频繁项集挖掘(Frequent Itemset Mining)指的是将那些共同出现较为频繁的项集找出来,其中一个经典的例子就是啤酒和尿布。下图展示了频繁项挖掘中的一些基本概念
- Transaction:每一行就是一个 Transaction,表示一个订单
- Item & ItemSet:每个 Transaction 包含了若干个 Item,表示订单中的商品,任意数量的 Item 可组成一个 ItemSet
- Support:表示某个 ItemSet 出现的次数
挖掘频繁项集有两个基本方法:Apriori 和 FP-growth,其中 Apriori 需要对原始数据进行多次的扫描,导致速度很慢。这里不展开讲述,具体可参考这篇文章。
这里讲述的是 FP-growth 算法,该算法通过构建一棵 prefix tree,使得只需要遍历两次原始的数据,下面先介绍这个算法的流程,再介绍如何通过 MapReduce 实现。
FP-growth 算法
FP-growth 算法首先需要构建一棵 FP-tree ,FP-tree 是一棵 prefix tree,构造的方法跟一般的 prefix tree 一样,但是在构造前需要对每个 transaction 中的 items 按照统一的规则排序(可以按照 item 出现的频率,也可以按照 item 的名称,总之各个 transaction 保持一致即可)
由于原始的 items 已经按照 items 名称排序,因此这里直接按照构建 prefix tree 的方法构建 FP-tree 即可,如下图所示是读入前两条记录的构建结果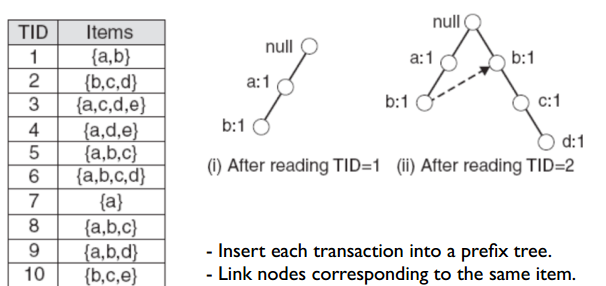
按照这种方法可以构建出整棵 FP-tree 如下图所示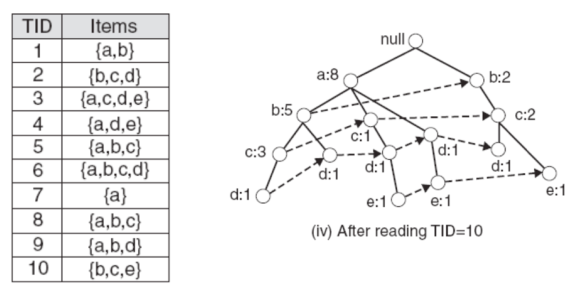
这里需要注意的是上述的过程忽略了一步,就是在构造 FP-tree 前还还需要设定一个 min-support 值,这个值表示某个 item 至少要出现 min-support 次,如果小于 min-support 次,则将这个 item 从所有的 transaction 中剔除,再按照上面的方法构造 prefix tree。
这么做的原因一是出现频率不高的 itemset 中的 item 被认为是相关度较低的,二是当输入很大的时候,构造出来的树也会很大,因此可通过设定阈值,去掉 infrequent item。但是从我们前面讲的内容可知,这样做其实已经去掉了部分长尾数据。
构造完 FP-tree 后,挖掘频繁项集时需要先指定一个 item,再挖掘与这个 item 相关的频繁项集,挖掘与这个 item 相关的频繁项集需要构造 Conditional FP-tree,所谓的 Conditional FP-Tree,就是与该 item 相关的所有 transaction 所组成的 FP-tree。如要挖掘与 e 这个 item 相关的频繁项集,则构造 Conditional FP-tree 过程如下
首先需要找到以 e 为叶子节点的所有 branch 组成的 tree,如下图 (a) 所示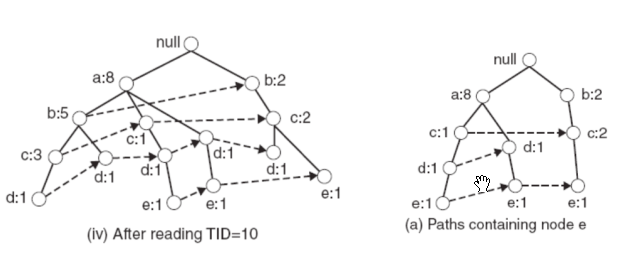
接着更新父节点的计数为子节点的计数之和,并且去掉 e 这个叶子节点,如下图所示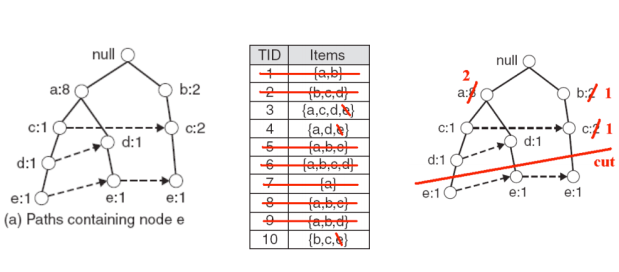
在这个过程中需要去掉那些 support 数不满足 min-support 的 item,这里令 min-support 为 2,,则由于上图中的 b 的 support 数只有 1,需要去掉 b 这个 item,如下图所示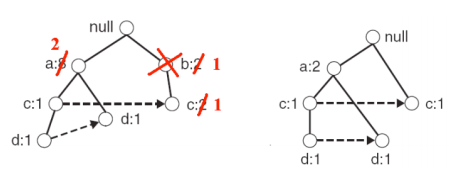
构造出 e 的 conditional FP-tree 后,只需要挖掘出 conditional FP-tree 中的频繁项集,并在所有的频繁项集后加上 e 即可,如从 conditional FP-tree 中挖掘出的频繁项集为 {a:2, d:2} 和 {c:2}, 则关于 e 的频繁项集为 {a:2, d:2, e:2} 和 {c:2, e:2}。这样实际上是在解决一个递归问题了。
MapReduce 实现 FP-growth
一般来说,挖掘频繁项集的原始数据都相当庞大,因此构造出来的 FP-tree 也会很大,当内存无法存储 FP-tree 时,一种解决方法就是通过提高 min-support 的值,从而将 FP-tree 的大小降低,但是根据之前讲的长尾效应,这样做会将长尾数据切掉。
另外一种方法就是通过分布式的方式实现该算法,通过分布式使得能够 构建 FP-tree 时支持更小的 min-support,从而能够挖掘非频繁项集。这里采用的分布式框架就是 MapReduce,下面讲述的是这个方法实现的细节。
下面首先介绍一下 MapReduce 的编程范式,输入、中间结果和输出均是 key-value pairs, 中间的 shuffling 过程目的就是要将 key 相同的 pairs 交给同一个 worker 处理。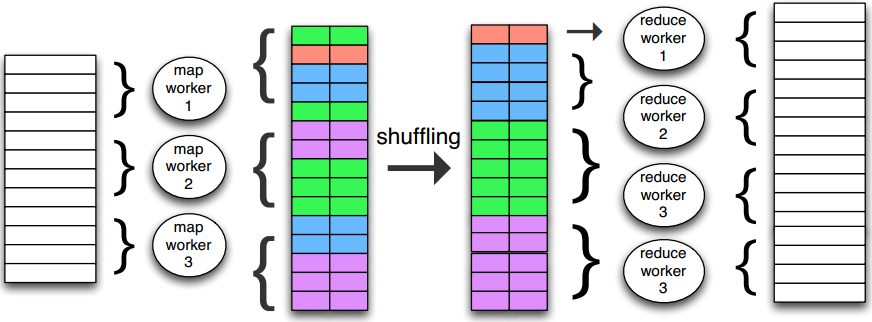
在具体的实现上,shuffling 过程可通过对 key 做 hash 后,再取模(worker 的数量)决定这个 kv 对由哪个 worker 来负责。
另外数据的传输是通过分布式文件系统实现的,也就是需要通过反复写磁盘来进行数据的传输,这导致了 MapReduce 的速度无法快起来。
从上面可知,找到 item A 和 item B 的频繁项集这两个任务是不相关的,只需要分别找出 item A 和 item B 的 conditional FP-tree 即可,因此可以分别交给两个 worker 进行处理。
通过 MapReduce 实现的 FP-growth,每一次的 map + reduce 过程能够输出 item 对应的 conditional FP-tree,下图所示的是 map 过程,能够从 transaction 中输出各个 item 对应的 conditional transaction
上图中最左边的 map input 是最开始的 transactions, 经过排序和过滤掉非频繁项后能够得到各个 item 对应的 conditional transaction,作为 map output 输入到 reduce 过程中,reduce 过程如下图所示,reduce 能够将相同的 key (item) 的 conditional transactions 聚合在一起,进而构建出这个 item 对应的 conditional FP-tree。
得到这个 item 的 conditional FP-tree 后,可对这棵 conditional FP-tree 进行相同的 MapReduce 操作,因此,原始的 FP-growth 算法递归一次在这里就是一个 MapReduce Job。
上面的实现方法实际上就是 PFP(Parallel FP-growth) 算法,目前在 spark 框架中有相应的实现,可以直接调用。
最后需要注意的一点是,PFP 虽然能够挖掘出非频繁项集,也就是长尾数据的尾巴部分,但是却无法判断出这些非频繁项集中那些项集是有效的,那些是噪声。
综上,本文主要介绍了频繁项挖掘中的 FP-growth 算法以及如何通过 MapReduce 实现这个算法,通过 MapReduce 实现的版本能够支持更小的 min-support,因此能够挖掘出非频繁项集,也就是长尾数据中的尾巴部分,但是这个方法不能判断出那些非频繁项集是有效的。
参考
分布式机器学习系列讲座 - 01 Infrequent Pattern Mining using MapReduce FP Tree 算法原理总结