分布式机器学习 (3)-Application Driven
本文主要介绍了互联网几项重要业务(在线广告,推荐系统,搜索引擎)背后所需的一项共同技术:语义理解 (semantic understanding),同时介绍了实现语义理解的若干种方法:包括矩阵分解,主题模型 (Topic Models) 等。原视频见这里,需要自备梯子。
semantic understanding 支持的业务
在线广告
作者以其在腾讯参与开发的 Peacock 系统为例介绍了在线广告所需的语义理解技术,如下是 peacock 系统对 “红酒木瓜汤” 这个查询关键词返回的语义理解的结果
最下面的 topics 是从 query 中推断出来的主题,每行为一个 topic,weight 是 query 属于这个 topic 的概率,topic_words 则是这个 topic 中的词语,且按照与 query 的相关度从高到低进行了排序。
如果将广告主的广告描述生成同样的 topics 分布,则可以将 query 和广告对应起来。Peacock 系统是基于 LDA(Latent Dirichlet allocation) 开发的,发表的具体论文是 Peacock: Learning Long-Tail Topic Features for Industrial Applications.
除了用户的 query,同样可得出用户浏览的内容的 topic 分布,进而根据用户的浏览内容为其推荐关联的广告。
推荐系统
推荐系统中最耳熟能详的算法是协同过滤,通过 users-items 矩阵中的 user 向量衡量 users 之间的相似性,通过 item 向量衡量 items 之间的相似性,具体可参考这篇文章。但是遇到下面这种情况时,协同过滤是无能为力的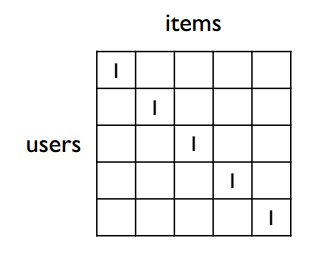
上图所示的状况是不同 user 向量之间没有共同出现的 item,这样无法计算 user 向量间的近似性;而实际中的数据往往是非常稀疏的,不同用户间相交的 items 很少,因此协同过滤在推荐系统中几乎不再被使用。
那么,如何将上面提到的 semantic understanding 应用到推荐系统中呢?如下图所示,假如将原来的 users-items 矩阵划分为两个大的 topics,则每个 user 和每个 items 都可以被映射成一个 topic 向量,这样通过比较 topic 向量即可比较两个 user 或 item 的相似性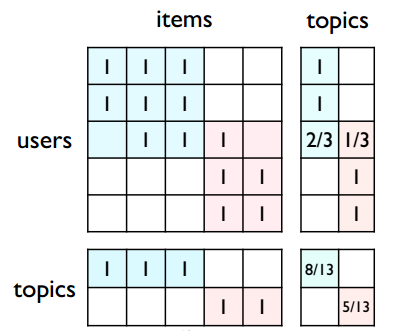
在实际中用得更多的是矩阵分解这一类方法,即无须事先对 users-items 矩阵进行划分,而是通过矩阵分解的方式得到每个 user 和每个 item 的 topic 向量。常见的 SVD、NMF 等都是这一类方法。
搜索引擎
搜索引擎跟在线广告有点类似,都会根据用户的 query 返回关联的内容,下图中的 text 可以理解为用户的搜索关键词和页面的关键词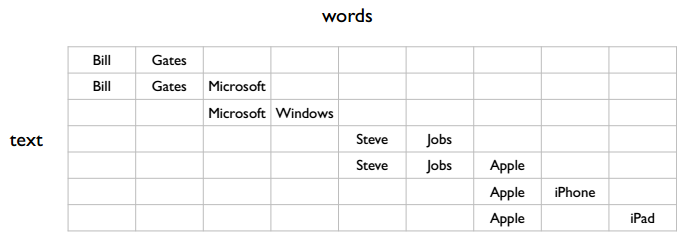
图中有几个 topic,最简单的是两个,如下图所示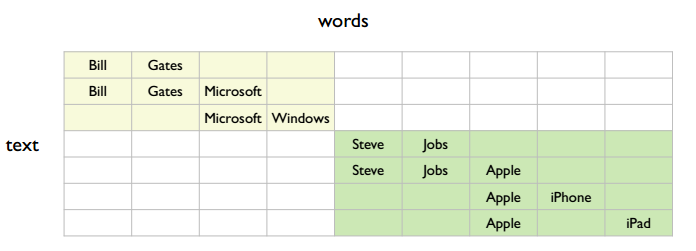
但是也可以认为有四个,如下图所示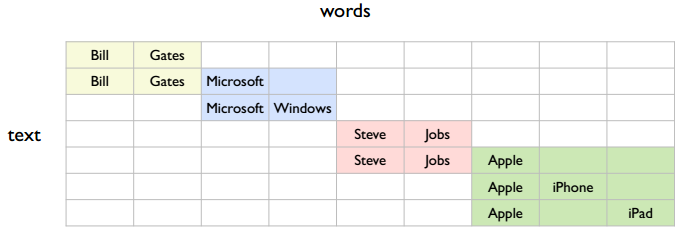
所以这里有个重要问题,就是应该学习什么样粒度的 topic ?作者的观点是学习更小粒度的语义的好处更多。比如说按照第一种大粒度的语义分法时,第一行和第三行是有关联的;而按照第二种小粒度的语义分法时,第一行和第三行直观上没有联系,但可通过第二行联系起来。即更小粒度的语义能够完成大粒度的语义所完成的事情,但是大粒度的语义未必能完成小粒度语义所完成的事情,如从搜索的精确性考虑,肯定是小粒度的语义比大粒度的语义搜索要来得精准。
实现 semantic understanding 的方法
实现 semantic understanding 的方法可以分为 unsupervised 和 supervised 两大类,supervised 其实就是分类(即将上面的 user 或 item 分类),但是 supervised 不仅需要人工标注的数据,而且还难以确定准确的类别数;因此实际中往往是采用 unsupervised 的方法,如下所示是一些 unsupervised 方法
Frequent itemset mining 在上一讲中已经讲过,实际中,Frequent itemset mining 和 collaborative filtering 使用得并不多
LSA(Latent semantic analysis) 实际上是对文本矩阵 (每行是一篇文本,每列是一个单词) 进行 SVD 分解,且得到的 U 矩阵 和 V 矩阵中分别含有每篇文本或每个单词的 topic 向量。其他矩阵分解类的方法也都是遵循着这个思路。
NMF(Non-negative matrix factorization) 是受限的 SVD,原因是这种方法分解后的矩阵中的元素必须要为正数。
pLSA(Probabilistic latent semantic analysis) 在 LSA 的基础上加入了概率,使得结果有可解释性
LDA(Latent Dirichlet allocation) pLSA 只能解释输入的数据,对于新来的数据无能为力,因此无法做到实时;因此有了 LDA 的出现,LDA 能够推断出新来的数据的 topic 分布,而 smoothed pLSA 指的是 LDA 在 pLSA 基础上加入了先验概率,具体为狄利赫里先验分布。
HDP(Hierarchical Dirichlet process) 与 LDA 效果类似,好处就是训练前不需要指定的 topics 的数量
作者认为,上面虽然列出了很多模型,但是不少模型之间是等价的,如 NFM 和 pLSA 的等价性可参考这篇文章,pLSA 和 LDA 之间的等价性可参考这篇文章;
最后 semantic understanding 应用在上面所述三个互联网业务 (在线广告,推荐系统,搜索引擎) 时,基本的步骤是一致的,均为
- Relevance: information retrieval
- Ranking: click-through rate prediction
第一步就是借助 semantic understanding 找到与 query 相关的结果,第二步要根据点击率等于具体业务相关的指标对这些相关结果排序。