通过 Keras 实现 LRCN 模型
本文主要介绍了如何通过 Keras 实现 LRCN 模型,模型出自论文 Long-term Recurrent Convolutional Networks for Visual Recognition and Description,最近需要用这个模型做个实验,在网上搜到的实现代码不多,因此这里记录一下,以供参考。
这里的 LRCN 模型的结构如下图所示, 输入是 image sequence,然后通过 CNN 提取每帧图像的特征,作为 LSTM 的输入,LSTM 可以为每帧预测一个 label,也可在只在最后预测一个 label 作为整个 sequence 的 label。这种想法非常自然,也是 video / image sequence 中的一个 base model。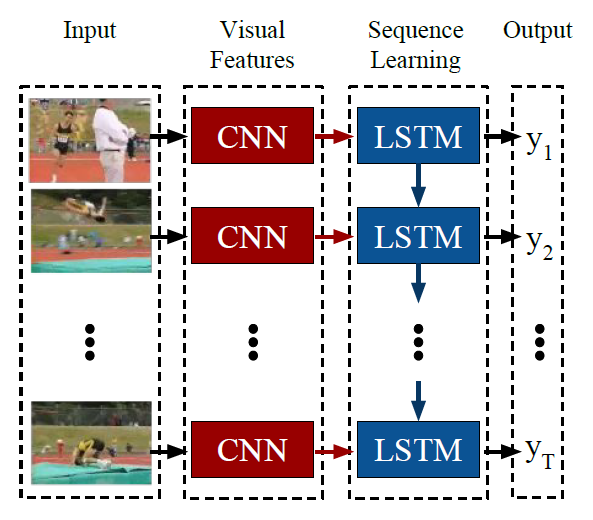
下面首先讲述如何在 Keras 中构建这个模型,然后讲述数据加载的两种模式:分别对应于不定长的输入序列和固定长度的输入序列。
构建模型
在具体的实现中,对于训练数据集不大的情况下, CNN 部分一般可采用预训练的模型,然后选择是否对其进行 FineTunning,这里我采用的是在 ImageNet 上预训练的 VGG16,并且对 VGG16 最上面的 5 层进行 FineTunning, 其他层的参数不变。
另外,对于输入的每帧图像,通过 CNN 抽取出的 feature map 的 大小为 (7,7,512),而 LSTM 的输入的 size 是 (batch_size, timesteps, input_dim),因此需要将 (7,7,512) 转为一个一维的 vector,这里我采用最简单的 Flatten() 方法。实际上,在这里可以采用更加灵活的转换,如这篇论文 Diversified Visual Attention Networks for Fine-Grained Object Classification 就提出了一种 attention 机制处理这些 feature map。
(7,7,512) 直接 Flatten 后的大小为 25088,直接输入 LSTM 的话比较大,因此这里还加了一个 2048 的全连接层,这样输入 LSTM 的 input_dim 的大小就是 2048.
LRCN 模型中的关键点在于为每个 LSTM 的 step 前连上 CNN 网络部分,在 Keras 中可通过 TimeDistributed 层来实现,同时如果需要长度不固定的输入序列时,对应的 sequence length 的参数要设为 None,在下面的代码中 input_shape 设为了 (None, 224, 224, 3), None 便是输入序列长度不固定,而 (224, 224, 3)则是预训练 VGG 固定的输入大小。
构建模型的 keras 代码如下,这里为了加快训练速度,将 LSTM 替换成了 GRU1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, TimeDistributed, Flatten, GRU, Dense, Dropout
from keras import optimizers
def build_model():
pretrained_cnn = VGG16(weights='imagenet', include_top=False)
# pretrained_cnn.trainable = False
for layer in pretrained_cnn.layers[:-5]:
layer.trainable = False
# input shape required by pretrained_cnn
input = Input(shape = (224, 224, 3))
x = pretrained_cnn(input)
x = Flatten()(x)
x = Dense(2048)(x)
x = Dropout(0.5)(x)
pretrained_cnn = Model(inputs = input, output = x)
input_shape = (None, 224, 224, 3) # (seq_len, width, height, channel)
model = Sequential()
model.add(TimeDistributed(pretrained_cnn, input_shape=input_shape))
model.add(GRU(1024, kernel_initializer='orthogonal', bias_initializer='ones', dropout=0.5, recurrent_dropout=0.5))
model.add(Dense(categories, activation = 'softmax'))
model.compile(loss='categorical_crossentropy',
optimizer = optimizers.SGD(lr=0.01, momentum=0.9, clipnorm=1., clipvalue=0.5),
metrics=['accuracy'])
return model
上面 LSTM 的参数初始化参考了知乎上这个答案:你在训练 RNN 的时候有哪些特殊的 trick?,主要就是 initializer 的方式选择、drop-out 和 graddient clipping 的设置。在我的实验中也证实了 graddient clipping 的设置会直接影响到最终的进度,而且影响比较大。
数据加载
由于 RNN 本身的结构特点,使得其可接受变长的输入,而且往往原始的 img sequence 数据也会符合这一特点,因此这里就有两种数据加载的方式,第一种是对原始数据不做处理, 每个样本的长度不一定相同;第二种是从各个样本中抽取出固定的长度。
但是这两种加载方式的输入的数据的 shape 都遵循着下面的模式 (batch_size, sequence_length, width, height, channel)
对于第一种加载方式,根据 这个 issue,有两种处理方法
- Zero-padding
- Batches of size 1
这里采用的是第二种处理方法,也就是将 batch_size 设置为 1, 即每次只用一个样本更新模型。因为第二种处理方法要事先设定一个固定长度 (可以是最长序列长度或其他方式获取的长度),而且 padding 会让原来较短的序列变得更长,消耗的内存会有所增加。
而对于第二种加载方式,给定固定的长度,需要尽可能 “均匀” 地从原始序列中抽出固定长度的序列,即帧与帧之间的间隔尽可能相等。但是这个可能会取决于具体的数据集和任务,在我的数据集上这样做是比较合理的。
两种加载方式的比较如下: 1)存储数据的方式不一样,固定长度的加载方式由于每个样本的 shape 一样,因此可以直接 concatenate 成一个大的 ndarray,然后在训练时的 batch_size 可设置成任意值;但是对于变长的加载方式,只能每次取一个样本, 然后要通过 np.expand_dims(imgs, axis=0) 的方式为样本添加 batch_size 这个维度(前一种方式不用,因为 concatenate 后会自动生成这个维度),然后训练模型同时将 batch_size 和 epoch 设为 1。 2)训练速度和效果有差别。首先是 batch_size 的不同使得训练速度上固定长度的方式比变长方式要快,这个比较好理解。 其次,由于 batch_size 也是一个影响 RNN 性能的重要参数,因此也会影响收敛性和效果。在我的实验中,batch_size 设置大于 1 时效果更好。
两种加载方式实现代码如下,加载的是一个样本的数据, img_dir 目录中包含了一个样本的所有 image sequence,且根据文件名排序后的序列是根据时间序列的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27from collections import deque
from keras.preprocessing import image
def load_sample(img_dir, categories = 7, fixed_seq_len = None):
label = int(img_dir.split('/')[-2].split('_')[0]) - 1 # extract label from name of sample
img_names = sorted(os.listdir(img_dir))
imgs = []
if fixed_seq_len: # extract certain length of sequence
block_len = round(len(img_names)/fixed_seq_len)
idx = len(img_names) - 1
tmp = deque()
for _ in range(fixed_seq_len):
tmp.appendleft(img_names[idx])
idx = max(idx-block_len, 0)
img_names = tmp
for img_name in img_names:
img_path = img_dir + img_name
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
imgs.append(x)
imgs = np.array(imgs)
label = np_utils.to_categorical(label, num_classes=categories)
if not fixed_seq_len: # add dimension for batch_size
#(seq_len, width, height, channel)-> (batch_size, seq_len, width, height, channel)
imgs = np.expand_dims(imgs, axis=0)
label = label.reshape(-1, categories)
return imgs, label
最后,在设计网络结构的时候,可通过逐层测试输出的大小来判断每一层是够达到了预期输出的效果,在 keras 中直接通过 model.predict(input) 即可获得当前 model 最后一层的输出。
另外,Keras 虽然能够比较快速地通过其提供的各层 layer 搭建出模型,但是如果要对模型进行更细致的设计的时候, Keras 就不是那么好做了,这时候就要上 tensorflow/pytorch/mxnet 这一类更加灵活的框架了。