梯度裁剪及其作用
本文简单介绍梯度裁剪 (gradient clipping) 的方法及其作用,最近在训练 RNN 过程中发现这个机制对结果影响非常大。
梯度裁剪一般用于解决 梯度爆炸 (gradient explosion) 问题,而梯度爆炸问题在训练 RNN 过程中出现得尤为频繁,所以训练 RNN 基本都需要带上这个参数。常见的 gradient clipping 有两种做法
- 根据参数的 gradient 的值直接进行裁剪
- 根据若干参数的 gradient 组成的 vector 的 L2 norm 进行裁剪
第一种做法很容易理解,就是先设定一个 gradient 的范围如 (-1, 1), 小于 -1 的 gradient 设为 -1, 大于这个 1 的 gradient 设为 1.
第二种方法则更为常见,先设定一个 clip_norm, 然后在某一次反向传播后,通过各个参数的 gradient 构成一个 vector,计算这个 vector 的 L2 norm(平方和后开根号)记为 LNorm,然后比较 LNorm 和 clip_norm 的值,若 LNorm <= clip_norm 不做处理,否则计算缩放因子 scale_factor = clip_norm/LNorm ,然后令原来的梯度乘上这个缩放因子。这样做是为了让 gradient vector 的 L2 norm 小于预设的 clip_norm。
关于 gradient clipping 的作用可更直观地参考下面的图,没有 gradient clipping 时,若梯度过大优化算法会越过最优点。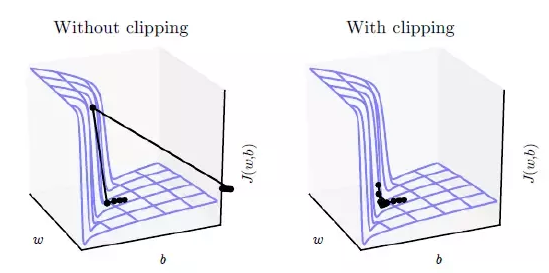
而在一些的框架中,设置 gradient clipping 往往也是在 Optimizer 中设置,如 tensorflow 中设置如下1
2
3
4optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
gvs = optimizer.compute_gradients(cost)
capped_gvs = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gvs]
train_op = optimizer.apply_gradients(capped_gvs)
Keras 中设置则更为简单1
optimizer = optimizers.SGD(lr=0.001, momentum=0.9, clipnorm=1.),
除此之外,调试 RNN 是个比较 tricky 的活,可参考知乎上这个问题:你在训练 RNN 的时候有哪些特殊的 trick?
另外,与 grdient explosion 相反的问题 gradient vanishing, 解决方法跟上面不同,不能简单地采用 scaling 的方法,具体可参考这个问题 梯度消失问题为什么不通过 gradient scaling 来解决?,实际的处理方法一般是采用 LSTM 或 GRU 这类有记忆的 RNN 单元。
参考:
- Gradient Clipping
- caffe 里的 clip gradient 是什么意思?
- What is gradient clipping and why is it necessary?