强化学习笔记 (3)- 从 Policy Gradient 到 A3C
在之前的文章 强化学习笔记 (2)- 从 Q-Learning 到 DQN 中,我们已经知道 Q-Learning 系列方法是基于 value 的方法, 也就是通过计算每一个状态动作的价值,然后选择价值最大的动作执行。这是一种间接的做法,那有没有更直接的做法呢?有!那就是直接更新策略。本文要介绍的 Policy Gradient 就是这类 policy-based 的方法, 除此之外,还会介绍结合了 policy-based 和 value-based 的 Actor-Critic 方法,以及在 Actor-Critic 基础上的 DDPG、A3C 方法。
Policy Gradient
基本思想
Policy Gradient 就是通过更新 Policy Network 来直接更新策略的。那什么是 Policy Network?实际上就是一个神经网络,输入是状态,输出直接就是动作(不是 Q 值),且一般输出有两种方式:一种是概率的方式,即输出某一个动作的概率;另一种是确定性的方式,即输出具体的某一个动作。
如果要更新 Policy Network 策略网络,或者说要使用梯度下降的方法来更新网络,需要有一个目标函数,对于所有强化学习的任务来说,其实目标都是使所有带衰减 reward 的累加期望最大。即如下式所示
\(L(\theta) = \mathbb E(r_1+\gamma r_2 + \gamma^2 r_3 + ...|\pi(,\theta))\)
这个损失函数和 Policy Network 策略网络简直没有什么直接联系,reward 是环境给出的,跟参数 \(\theta\) 没有直接运算上的关系。那么该如何能够计算出损失函数关于参数的梯度 \(\nabla_{\theta} L(\theta)\)?
上面的问题没法给出更新策略,我们不妨换一个思路来考虑问题。
假如我们现在有一个 Policy Network 策略网络,输入状态,输出动作的概率。然后执行完动作之后,我们可以得到 reward,或者 result。那么这个时候,我们有个非常简单的想法:如果某一个动作得到 reward 多,那么我们就使其出现的概率增大,如果某一个动作得到的 reward 少,那么我们就使其出现的概率减小。
当然,用 reward 来评判动作的好坏是不准确的,甚至用 result 来评判也是不准确的(因为任何一个 reward,result 都依赖于大量的动作才导致的,不能只将功劳或过错归于当前的动作上。但是这样给了我们一个新的思路:如果能够构造一个好的动作评判指标,来判断一个动作的好与坏,那么我们就可以通过改变动作的出现概率来优化策略!
假设这个评价指标是 \(f(s,a)\), 我们的 Policy Network 输出的 \(\pi(a|s,\theta)\) 是概率, 那么可以通过极大似然估计的方法来优化这个目标。比如说我们可以构造如下目标函数
\(L(\theta) = \sum log\pi(a|s,\theta)f(s,a)\)
比如说,对于某局游戏,假如最终赢了,那么认为这局游戏中每一步都是好的,如果输了,那么认为都是不好的。好的 \(f(s,a)\) 就是 1,不好的就是 - 1,然后极大化上面的目标函数即可。
实际上,除了极大化上面的目标函数,还可以直接对 \(f(s,a)\) 进行极大化,如这篇博文 Deep Reinforcement Learning: Pong from Pixels 中直接最大化 \(f(x)\) 也就是 \(f(s, a)\) 的期望,可以看到,最后的结果跟上面的目标函数是一致的。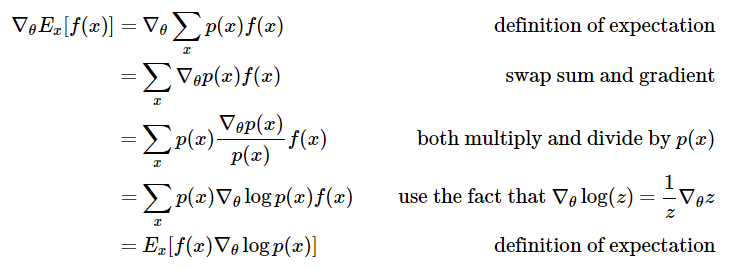
评判指标的选择
从上面的推导也可知道,在 Policy Gradient 中,如何确定评价指标 \(f(s,a)\) 是关键。 上面提到了一种简单地根据回合的输赢来判断这个回合中的每一步到底是好是坏。但是其实我们更加希望的是每走一步就能够获取到这一步的具体评价,因此出现了很多其他的直接给出某个时刻的评估的评价方式。如这篇论文 High-dimensional continuous control using generalized advantage estimation 里就对比了若干种评价指标。
上面公式(1)中的 \(\Psi_t\) 就是 t 时刻的评价指标。从上图可以看到我们可以使用 reward,使用 Q、A 或者 TD 来作为动作的评价指标。那这些方法的区别在哪里?
根据这篇文章 DRL 之 Policy Gradient, Deterministic Policy Gradient 与 Actor-Critic, 本质的区别在于 variance 和 bias 的问题
用 reward 来作为动作的评价是最直接的,采用上图第 3 种做法 reward-baseline 是很常见的一种做法。这样做 bias 比较低,但是 variance 很大,也就是 reward 值太不稳定,会导致训练不会。
那么采用 Q 值会怎样呢?Q 值是对 reward 的期望值,使用 Q 值 variance 比较小,bias 比较大。一般我们会选择使用 A,Advantage。A=Q-V,是一个动作相对当前状态的价值。本质上 V 可以看做是 baseline。对于上图第 3 种做法,也可以直接用 V 来作为 baseline。但是还是一样的问题,A 的 variance 比较大。为了平衡 variance 和 bias 的问题,使用 TD 会是比较好的做法,既兼顾了实际值 reward,又使用了估计值 V。在 TD 中,TD (lambda) 平衡不同长度的 TD 值,会是比较好的做法。
在实际使用中,需要根据具体的问题选择不同的方法。有的问题 reward 很容易得到,有的问题 reward 非常稀疏。reward 越稀疏,也就越需要采用估计值。
以上就是 Policy Gradient 的核心思想,通过 policy network 输出的 softmax 概率 和获取的 reward (通过评估指标获取) 构造目标函数,然后对 policy network 进行更新。从而避免了原来的 reward 和 policy network 之间是不可微的问题。也因为 Policy Gradient 的这个特点,目前的很多传统监督学习的问题因为输出都是 softmax 的离散形式,都可以改造成 Policy Gradient 的方法来实现,调节得当效果会在监督学习的基础上进一步提升。
Actor-Critic
上面提到的多种评估指标其实已经涵盖了 Actor-Critic 的思想,原始的 Policy Gradient 往往采用的回合更新,也就是要到一轮结束后才能进行更新。如某盘游戏,假如最后的结果是胜利了,那么可以认为其中的每一步都是好的,反之则认为其中的每一步都是不好的。其更新过程如下,图片摘自 David Silver 的 Policy Gradient 课件 ,这种方法也叫 Monte-Carlo Policy Gradient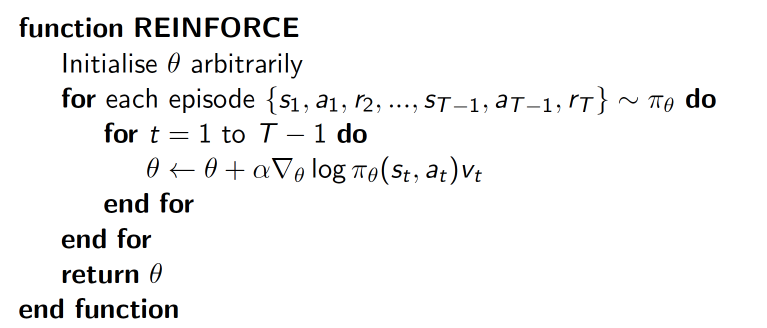
图中的 \(\log \pi_{\theta}(s_t, a_t)\) 是 policy network 输出的概率,\(v_t\) 是当前这一局的结果。这是 policy gradient 最基本的更新形式。但是这个方法显然是有问题的,最后的结果好久并不能说明其中每一步都好。因此一个很直观的想法就是能不能抛弃回合更新的做法,而采用单步更新?Actor-Critic 干的就是这个事情。
要采用单步更新,意味着我们需要为每一步都即时做出评估。Actor-Critic 中的 Critic 负责的就是评估这部分工作,而 Actor 则是负责选择出要执行的动作。这就是 Actor-Critic 的思想。从上面论文中提出的各种评价指标可知,看到 Critic 的输出有多种形式,可以采用 Q 值、V 值 或 TD 等。
因此 Actor-Critic 的思想就是从 Critic 评判模块 (采用深度神经网络居多) 得到对动作的好坏评价,然后反馈给 Actor (采用深度神经网络居多) 让 Actor 更新自己的策略。从具体的训练细节来说,Actor 和 Critic 分别采用不同的目标函数进行更新, 如可参考这里的代码 Actor-Critic (Tensorflow),下面要说的 DDPG 也是这么做的。
Deep Deterministic Policy Gradient(DDPG)
上面提到的的 Policy Gradient 处理问题其实还是局限在动作个数是离散和有限的情况,但是对于某些输出的值是连续的问题,上面的方法就不管用了,比如说自动驾驶控制的速度,机器人控制移动的幅度等。
最开始这篇论文 Deterministic Policy Gradient Algorithms 提出了输出连续动作值的 DPG (Deterministic Policy Gradient) ; 然后 论文 Continuous control with deep reinforcement learning 基于 DPG 做了改进,提出了 DDPG (Deep Deterministic Policy Gradient)。
这里 DPG 不详细展开说了,简而言之,主要就是证明了 deterministic policy gradient 不仅存在,而且是 model-free 形式且是 action-value function 的梯度。因此 policy 不仅仅可以通过 概率分布表示,也就将动作空间推到了无限大的。具体的理论课参考这篇文章 深度增强学习(DRL)漫谈 - 从 AC(Actor-Critic)到 A3C(Asynchronous Advantage Actor-Critic)
DDPG 相对于 DPG 的核心改进是引入了 Deep Learning,采用深度神经网络作为 DPG 中的策略函数 \(μ\) 和 \(Q\) 函数的模拟,即 Actor 网络和 Critic 网络;然后使用深度学习的方法来训练上述神经网络。两者的关系类似于 DQN 和 Q-learning 的关系。
DDPG 的网络结构为 Actor 网络 + Critic 网络,对于状态 \(s\), 先通过 Actor 网络获取 action \(a\), 这里的 \(a\) 是一个向量;然后将 \(a\) 输入 Critic 网络,输出的是 Q 值,目标函数就是极大化 Q 值,但是更新的方法两者又有一些区别。论文中显示 DDPG 算法流程如下
从算法的流程可知,Actor 网络和 Critic 网络是分开训练的,但是两者的输入输出存在联系,Actor 网络输出的 action 是 Critic 网络的输入,同时 Critic 网络的输出会被用到 Actor 网路进行反向传播。
原始论文没有给出两个网路的具体示意图,这里给出一张这篇文章画的示意图,可以看到,Critic 跟之前提到的 DQN 有点类似,但是这里的输入是 state + action,输出是一个 Q 值而不是各个动作的 Q 值。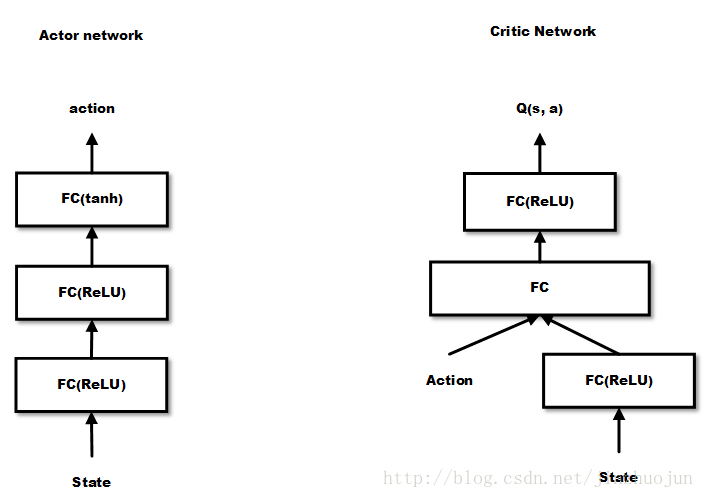
由于在 DDPG 中,我们不再用单一的概率值表示某个动作,而是用向量表示某个动作,由于向量空间可以被认为是无限的,因此也能够跟无限的动作空间对应起来。
Asynchronous Advantage Actor-Critic(A3C)
在提出 DDPG 后,DeepMind 在这个基础上提出了效果更好的 Asynchronous Advantage Actor-Critic(A3C),详见论文 Asynchronous Methods for Deep Reinforcement Learning
A3C 算法和 DDPG 类似,通过 DNN 拟合 policy function 和 value function 的估计。但是不同点在于 1. A3C 中有多个 agent 对网络进行 asynchronous update,这样带来了样本间的相关性较低的好处,因此 A3C 中也没有采用 Experience Replay 的机制;这样 A3C 便支持 online 的训练模式了 2. A3C 有两个输出,其中一个 softmax output 作为 policy \(\pi(a_t|s_t;\theta)\),而另一个 linear output 为 value function \(V(s_t;\theta_v)\) 3. A3C 中的 Policy network 的评估指标采用的是上面比较了多种评估指标的论文中提到的 Advantage Function (即 A 值) 而不是 DDPG 中单纯的 Q 值。
整体的结构如下所示,图片摘自这篇文章。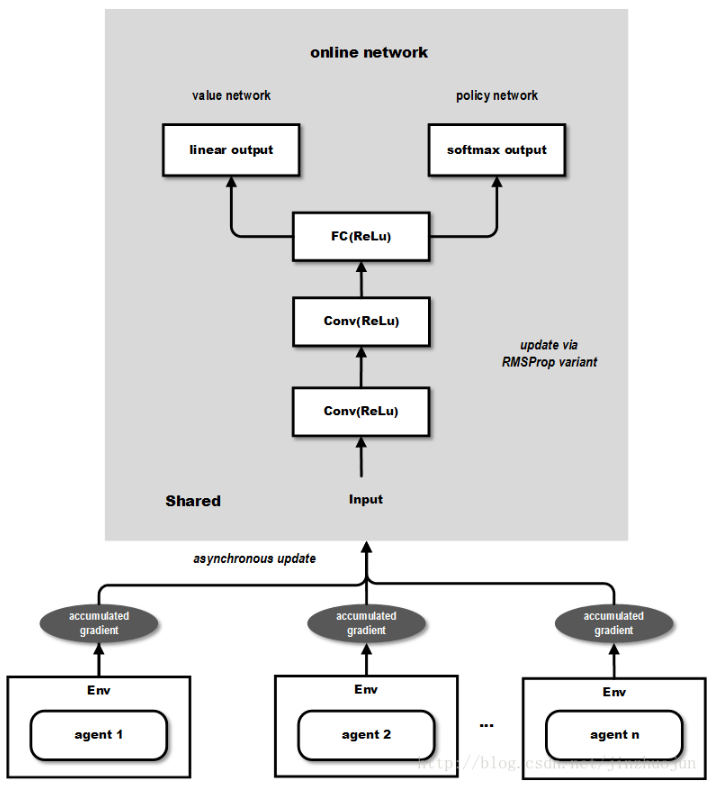
从上面的如可知,输出包含两部分,value network 的部分可以用来作为连续动作值的输出,而 policy network 可以作为离散动作值的概率输出,因此能够同时解决前面提到的两类问题。
两个网络的更新公式如下
A3C 通过创建多个 agent,在多个环境实例中并行且异步的执行和学习,有个潜在的好处是不那么依赖于 GPU 或大型分布式系统,实际上 A3C 可以跑在一个多核 CPU 上,而工程上的设计和优化也是这篇文章的一个重点。
综上,本文主要介绍了 Policy Gradient 这一类的方法,最基础的 Policy Gradient 是回合更新的,通过引入 Critic 后变成了单步更新,而这种结合了 policy 和 value 的方法也叫 Actor-Critic,Critic 有多种可选的方法。对于输出动作为连续值的情形,前面那些输出动作概率分布的方法无能为力,因此提出了 DPG 和 DDPG,DDPG 对 DPG 的改进在于引入深度神经网络去拟合 policy function 和 value function。在 DDPG 基础上又提出了效果更好的 A3C,这个方法在 DDPG 上引入了多个 agent 对网络进行 asynchronous update,不仅取得了更好的效果,而且降低了训练的代价。
参考
- 深度增强学习之 Policy Gradient 方法 1
- Deep Reinforcement Learning: Pong from Pixels
- 深度增强学习(DRL)漫谈 - 从 AC(Actor-Critic)到 A3C(Asynchronous Advantage Actor-Critic)
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction