Code Complete 阅读笔记 - 创建高质量的代码 (2)
本文主要是 Code Complete 中创建高质量的代码部分的的两章笔记:第 8 章(防范式编程)、第 9 章(伪代码编码过程),介绍了如何进行防范式编程(defensive programming),即保护程序免遭非法输入数据的破坏,目的其实就是增强程序的鲁棒性;同时介绍了如何通过伪代码编码方法来创建类和子程序。
防御式编程(defensive programming)
这里的防御式编程的主要思想是:子程序不应该因为传入错误的数据而被破坏,哪怕是由其他子程序产生的错误数据。下面主要就是讲述一些方法来处理这类问题
断言(assertion)
assert 关键字在多门语言中均有出现,如 Python, Java,c++ 等;其目的就是非常肯定某个条件表达式是成立的,否则就是出错了,如确保分母不为 0 等。而应用在防范式编程中,可以用来检查如下条件
- 输入参数和输出参数的取值处于预期的范围内
- 子程序开始(或结束)执行时,文件或流是打开(或关闭)的状态
- 子程序开始(或结束)执行时,文件或流的读写位置处于开头(或结尾)的状态
- 子程序开始(或结束)执行时,某个容器是空的(满的)
- 文件或流已用只读、只写或可读可写的方式打开
- 仅用于输入的变量的值没有被子程序修改
- 指针非空
- 传入子程序的数组或其他容器的 size 能容纳设定的数据元素个数
- ……..
需要注意的是,断言只是在开发阶段被编译到目标代码中,而在生成产品代码是并不编译进去,以降低系统的性能。
关于使用断言,有如下的建议
用错误处理代码来处理预期会发生的情况,而用断言来处理绝对不应该发生的状况
避免把执行代码放到断言中,因为这样会导致关闭断言时,编译器很可能就把这些代码排除在外, 正确的做法是先将执行代码的结果在断言外用变量存起来,如下所示
1
2
3
4
5
6// bad
assert PerformAction() == True
//good
result = PerformAction()
assert result == True用断言来注解并验证前条件(precondition)和后条件(postcondition)。简单来说,前条件就是在执行函数前需要为函数准备好的条件,后条件则是在函数执行后要完成的任务。
错误处理技术
上面提到用断言来处理绝对不应该发生的状况,而用错误处理代码来处理预期会发生的情况,如网络阻塞等。那么该怎么处理那些可能发生的错误呢?本章给出了如下可行的方法
- 返回中立值。如数值计算结果返回 0,字符串可以返回空字符,指针操作可以返回一个空指针等。
- 返回下一个正确的数据。如在处理数据流的时候,如果发现某一条记录已经损坏,可以继续读下去知道又找到一条正确记录为止,比如说以每秒 100 次的速度读取体温计的数据,那么如果某一次得到的数据有误,只需再等上 1 / 100 秒然后继续读取即可。
- 返回与前一次相同的数据。同样是上面的体温计的例子,如果在某次读取中没有获得数据,可以简单地返回前一次的读取结果,这是根据实际的应用情况决定的,在某些变化较大的场景下不能这么使用。
- 使用最接近的合法值。比如说汽车的速度盘,倒车时无法显示负值的速度,因此简单地显示 0,即最接近的合法值。
- 把警告信息记录到日志文件中,然后继续执行。
- 返回一个错误码。即只让系统的某些部分处理错误,其他部分不在本地处理错区,而是简单地报告说有错误发生。
- 调用错误处理子程序或对象。把错误处理都集中在一个全局的错误处理子程序或对象中。
- ….
异常
异常是把代码中的错误或异常事件传递给调用代码的一种特殊手段。异常的基本结构是:子程序使用 throw 跑出一个异常对象,再被调用链上层其他子程序的 try-catch 语句捕获。
使用异常时有以下建议
- 只有在真正例外的情况下才抛出异常。也就是说假如子程序局部能够处理这个错误就不要抛出异常;因为异常虽然能够增加程序的鲁棒性,但是会使程序的复杂性增加。调用子程序的代码需要了解呗调用的代码中可能会抛出的异常,因此异常弱化了封装性。
- 避免在构造函数和析构函数中抛出异常。比如在 C++ 里只有当对象完全构造后才可能调用析构函数,也就是说,如果在构造函数的代码里抛出异常,就不会调用析构函数,从而造成潜在的资源泄露问题。
- 在合适的抽象层次抛出异常。即抛出的异常应该与子程序接口的抽象层次一致的。如下所示,第一个例子中
GetTaxId()将更底层的EOFException返回给调用方, 这样破坏了封装性。与之相反的是第二个例子,GetTaxId()里的异常处理代码可能只要把一个io_disk_not_ready异常映射为EmployeeDataNotAvailable异常就好了。
1 | // 抛出抽象层次不一致的异常的类 |
- 把项目中对异常的使用标准化。为了保持异常处理尽可能便于管理,可以用以下几种途径把对异常的使用标准化
- 某些语言允许抛出的类型多种多样,如 C++ 就可以抛出对象、数据以及指针, 因此应该为可以抛出哪些种类的异常建立一个标准;可以考虑只抛出从
std::exception基类派生出来的对象 - 考虑创建项目的特定异常类,用作项目所有可能抛出的异常的基类
- 规定在何种场合先允许代码使用
throw-catch语句在局部对错误进行处理 - 规定在何种场合允许代码抛出不在局部进行处理的异常
- 某些语言允许抛出的类型多种多样,如 C++ 就可以抛出对象、数据以及指针, 因此应该为可以抛出哪些种类的异常建立一个标准;可以考虑只抛出从
隔离程序
隔栏(barricade)是一种容损策略,与防火墙类似,当火灾发生时,防火墙能阻止火势从建筑物的一个部位向其他部位蔓延。而以防御式编程为目的而进行隔离的一种方法,就是把某些接口选定为 “安全” 区域的边界。对穿越安全区域边界的数据进行合法性校验,并当数据非法时做出对策,如下图所示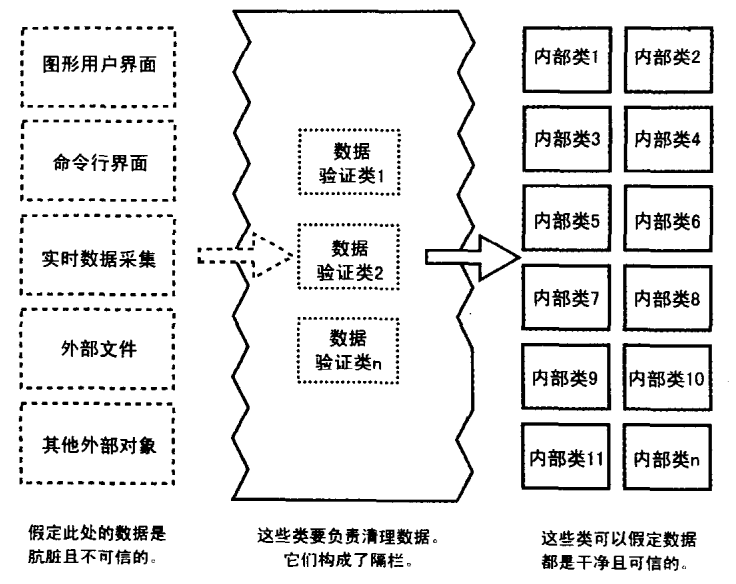
同样的可以在类的层次中使用这种方法,类的公用方法可以假设数据是不安全了,需要负责检查数据并进行清理。一旦类的公用 方法接受了数据,那么类的私有方法就可以假定数据都是安全的了。
隔栏的使用使断言和错误处理有了清晰的区分,隔栏外部的程序应使用错误处理技术,在哪里对数据做任何假定都是不安全的;而在隔栏的内部的程序就应该使用断言技术,因为传进来的数据应该已在通过隔栏时被清理过了。
小结
防御式编程能够让错误更容易发现和修改,并减少错误对产品代码的破坏,增加程序的鲁棒性,但是过度的使用也会引起问题。如果在每一个能够想到的提防用一种能想到的方法检查从参数传入的数据,那么程序将会变得臃肿而缓慢,而且引入了额外的代码增加了软件的复杂度。因此需要考虑好在那些重要的地方进行防御,然后因地制宜地调整进行防御式编程的优先级。
伪代码编码过程
这一章主要关注创建类及其子程序的一种方式:伪代码编码。伪代码编程过程是一种通过书写伪代码而更加高效的创建程序代码的专门方法。
伪代码
关于使用伪代码有以下指导原则
- 用类似英语的语言来精确描述特定操作
- 避免使用目标编程语言中的语法元素,而应该在一个比代码本身略高的层次上进行设计
- 在意图层面上编写伪代码,即用伪代码去描述解决问题的方法的意图,而不是写如何在目标语言中实现这个方法
如下是一段违背了上面的指导原则的伪代码,这段代码的意图不明确,而且包含了 C 语言的具体语法以及编码细节(返回 1 表示 null)1
2
3
4
5
6increment resource number by 1
allocate a dlg struct using malloc
if malloc() returns NULL then return 1
invoke OSrsrc_init to initialize a resource for the operating system
*hRsrcPtr = resource number
return 0
下面是针对同样功能所写的伪代码,比起上面的就要好很多了1
2
3
4
5
6
7
8
9
10Keep track of current number of resources in use
If another resource is available
Allocate a dialog box structure
If a dialog box structure could be allocated
Note that one more resource is in use
Initialize the resource
Store the resource number at the location provided by the caller
Endif
Endif
Return true if a new resource was created; else return false
使用这种风格的伪代码能够带来以下好处
- 伪代码使得评审更加容易。无须检查源代码就可以评审细节设计
- 伪代码支持反复迭代精化的思想。从高层设计开始,将其精化为伪代码,然后再把伪代码精化为源代码。这样持续不断的小步精化,可以在推向更低的细节层次的同时,不断检查已形成的设计;及时修复各个层次的错误
- 伪代码使变更更加容易。这跟在产品最具可塑性的阶段进行变动的原则是相同的
- 伪代码比其他形式的设计文档更加容易维护。使用其他方法时,设计和代码是分离的,当其中之一变动时,两者就不再一致,而使用伪代码编程时,伪代码中的语句将会变为代码中的注释。
通过伪代码创建子程序
通过伪代码创建子程序主要包括以下步骤
- 设计子程序
- 编写子程序的代码
- 检查代码
- 收尾工作
- 按照需要重复上述步骤
设计子程序
设计子程序可以从以下角度出发
(1)检查先决条件。即检查子程序与整体设计是否匹配,是否是真正必需的,至少是间接需要的 (2)定义子程序要解决的问题。应该详细说明如下问题
- 子程序将要隐藏的信息
- 传给这个子程序的各项输入
- 从该子程序得到的输出
- 调用程序前确保有关的前条件成立
- 在子程序将控制权交回给调用方之前,确保其后条件的成立
(3)为子程序命名,这一部分在上一篇笔记有提及 (4)决定如何测试子程序 (5)在标准库中搜寻可用的功能。即如果在标准库中已经有该子程序特定的功能的实现,可以直接使用而不重复造轮子 (6)研究算法和数据类型 (7)编写伪代码。首先为子程序编写一般性注释,然后为子程序编写高层次的伪代码。如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 一般性注释
This routine outputs an error message based on an error code
supplied by the calling routine. The way it outputs the message
depends on the current processing state, which it retrieves
on its own. It returns a value indicating success or failure.
// 伪代码
set the default status to "fail"
look up the message based on the error code
if the error code is valid
if doing interactive processing, display the error message
interactively and declare success
if doing command line processing, log the error message to the
command line and declare success
if the error code isn't valid, notify the user that an internal error
has been detected
return status information
编写子程序代码
主要过程就是在伪代码的每一句话下填入代码。如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51/* This routine outputs an error message based on an error code
supplied by the calling routine. The way it outputs the message
depends on the current processing state, which it retrieves
on its own. It returns a value indicating success or failure.
*/
Status ReportErrorMessage(
ErrorCode errorToReport
) {
// set the default status to "fail"
Status errorMessageStatus = Status_Failure;
// look up the message based on the error code
Message errorMessage = LookupErrorMessage( errorToReport );
// if the error code is valid
if ( errorMessage.ValidCode() ) {
// determine the processing method
ProcessingMethod errorProcessingMethod = CurrentProcessingMethod();
// if doing interactive processing, display the error message
// interactively and declare success
if ( errorProcessingMethod == ProcessingMethod_Interactive ) {
DisplayInteractiveMessage( errorMessage.Text() );
errorMessageStatus = Status_Success;
}
// if doing command line processing, log the error message to the
// command line and declare success
else if ( errorProcessingMethod == ProcessingMethod_CommandLine ) {
CommandLine messageLog;
if ( messageLog.Status() == CommandLineStatus_Ok ) {
messageLog.AddToMessageQueue( errorMessage.Text() );
messageLog.FlushMessageQueue();
errorMessageStatus = Status_Success;
}
else {
// can't do anything because the routine is already error processing
}
else {
// can't do anything because the routine is already error processing
}
}
// if the error code isn't valid, notify the user that an
// internal error has been detected
else {
DisplayInteractiveMessage(
"Internal Error: Invalid error code in ReportErrorMessage()"
);
}
// return status information
return errorMessageStatus;
}
检查代码
主要包含以下几个步骤
1. 人肉运行代码 2. 编译子程序。把编译器的告警级别调到最高;消除产生错误消息和警告的所有根源 3. 在调试器中逐行执行代码 4. 测试代码,编写测试用例来测试代码 5. 消除程序中的错误
收尾工作
收尾工作就是重新审视整个子程序代码来确保子程序的质量合乎标准
- 检查子程序的接口。确保所有的输入、输出数据都参与了计算,且所有的参数也都用到了
- 检查整体的设计质量。确认子程序只干一件事;子程序之间的耦合是松散的;子程序采用了防御式编程;
- 检查子程序中的变量。检查是否存在不准确的变量名称、未被用到的对象、未经声明的变量、未经初始化的对象等
- 检查子程序的布局。确保正确地使用了空白来明确子程序、表达式及参数列表的逻辑结构
- 检查子程序的文档,确认有伪代码转化而来的注释仍是准确无误的。
- 出去冗余的注释
- 。。。
小结
伪代码编码是创建类和子程序的一个有效途径,在编写时需要使用易懂的英语,避免使用特定编程语言中才有的特性,同时要在意图层面上写伪代码,即描述该做什么,而不是怎么去做。