分布式系统笔记 (1)-MapReduce
一直都想系统性地学习一下分布式系统的一些理论,所以打算开个坑学习一下 MIT 的课程 6.824: Distributed Systems 。本文主要是 LEC 1 中的内容,简单介绍了分布式系统的几个核心问题,以及经典的分布式计算框架 - MapReduce, 虽然这是耳熟能详的一个框架(或者说是编程范式)了,但是其设计思想至今还是非常值得参考的。
分布式系统概述
简单来说,分布式的目的就是通过多台机器进行协作来提供一台机器所无法提供的运算能力和存储能力。除了通过增加机器来拓展运算能力和存储能力的伸缩性,分布式会额外带来机器隔离后的安全性、多份数据副本的错误容忍性等。
性能 (performance),一致性 (consistency), 容错 (fault tolerance) 是分布式系统中比较关注的问题。
如何让总体的运算能力随着机器数量的增长而线性增长?这是 performance 所关心的,各台机器的负载差别大吗 (load balance)? 网络能承受得住随着机器数量增加而增加的通信吗 (共享资源的瓶颈)?所有的代码都能够被并行化吗?
如何让多台机器上的同一份数据副本被多个进程读写后仍然保持一致?这是 consistency 所关心的,这个过程需要考虑的问题就太多了,因此也产生了很多一致性协议 (Paxos, Raft 等) 专门处理这个问题。比如说当 client 或 server 在写数据的不同阶段时宕机该怎么办?网络的抖动导致了 server 的假死 (脑裂) 怎么办?性能 (performance) 与一致性 (consistency) 总是相悖的,也就是说强一致性往往会导致比较慢的系统,高性能的系统通常会以牺牲强一致性为代价,需要根据具体场景进行 trade-off。
如何让不可避免的宕机不影响总体的服务?这是 fault tolerance 所关心的,在一台机器宕掉后,其执行过的 tasks 该怎么办?其他与这台机器发生过的 communication 的机器的依赖性该怎么解决?
可以说任意的分布式系统都会涉及到这三个问题,只是会各有侧重;目前常见的分布式系统从功能上可分为分布式计算框架 (MPI, MapReduce, Spark 等)、分布式文件系统 (GFS, HDFS 等)、分布式调度系统 (Mesos, Yarn 等)。
MapReduce
很久之前写过一篇关于 MapReduce 使用的文章:分布式机器学习 (4)-Implement Your MapReduce,这里则主要是根据 MapReduce 论文着重讲述 MapReduce 的一些原理。
下图是从 MapReduce 的论文 MapReduce: Simplified Data Processing on Large Clusters 中摘取的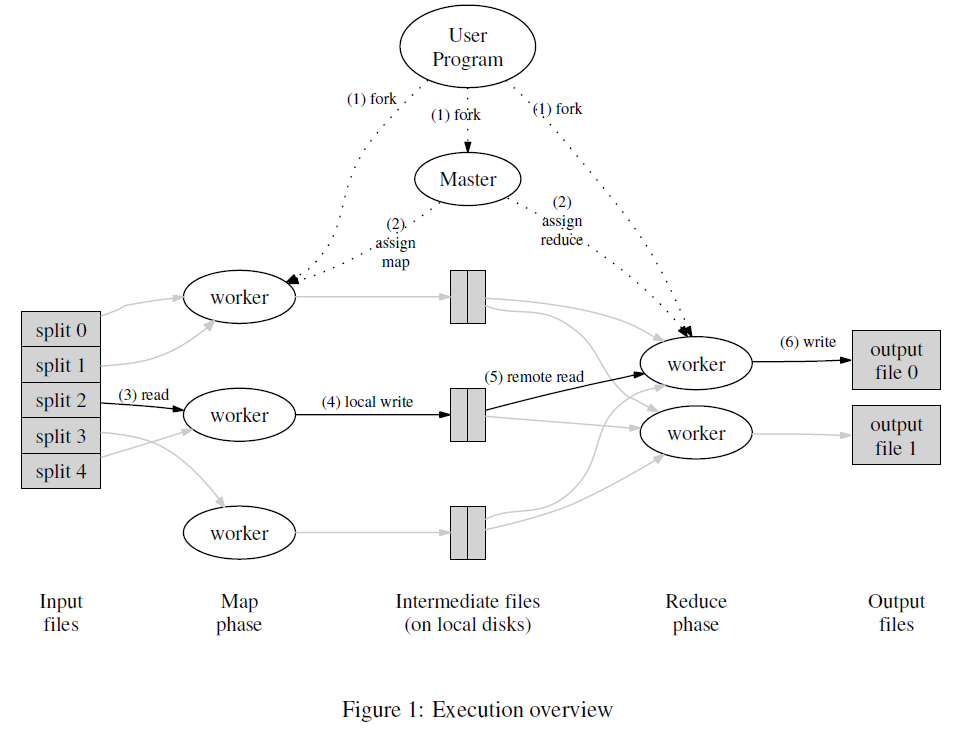
通常 MapReduce 被人所了解的是上图中 (3)(4)(5)(6) 的过程,也就是输入文件被分成 M 个小文件,每个小文件分别在 Map phase 被 Map 函数处理后输出一系列的(key,valu) 对,然后对 key 进行哈希取模找到除了这个 key 的 reducer worker,reduce worker 在 Reduce phase 会对通过 reduce 函数处理相同的 key,两个函数的输入输出如下所示1
2Map: (k1,v1) → list(k2,v2)
Reduce: (k2,list(v2)) → list(v2)
这个过程理解起来很简单,框架使用起来也不麻烦,这是因为 MapReduce 框架隐藏了上图中通过 master 追踪各个 task 是否顺利完成、以及如何进行 fault tolerance,而这也是论文最值得关注的点之一。
Execution Overview
上面讲的 MapReduce 过程可以说是一个编程范式,下面主要根据原始论文讲述整体的执行流程,各个步骤的编号跟上图保持一致
- User Program 中的 MapReduce 库会将输入分成 M 个小文件(通常是 16MB 到 64MB),然后 fork 出多个子进程
- 子进程中有一个作为 master,其他作为 worker。假设有 M 个 map task 和 R 个 reduce task(M 和 R 都远大于机器数量),master 会分配挑选处于 idle 的 worker 分配 task
- 被分配了 map task 的 worker 读入对应的输入文件,从输入文件中解析出 key/value pairs,并将每个 pair 输入用户自定义的 Map 函数,Map 函数输出的 intermediate key/value pairs 被缓存在内存中
- 缓存在内存中的 intermediate key / value pairs 会被周期性地写入 map worker 本地的磁盘,根据 key 的不同分别写入到 R 个本地文件中,然后这些文件在本地的路径会传输给 master,从而 master 可以告知 reducer worker 到哪里读取数据
- 直到所有的 Map 过程完成,Reduce 过程才能开始;当 reduce worker 被 master 告知要读取的文件的位置时,会通过 RPC 从 map worker 的磁盘读取这些数据;reduce worker 读取完所有的 intermediate key / value pairs 后会针对 key 进行排序 **,从而让所有相同的 key 汇聚在一块
- reduce worker 遍历排序后的 pairs,并将每个独立的 key 及其对应的 value 集合传输给 Reduce 函数,Reduce 函数则会将输出添加至最终的文件中。
在完成一个 MapReduce 计算过程后会产生 R 个文件,但是一般不需要对这 R 个文件进行合并,因为这些文件可能会被作为下一个 MapReduce 计算的输入,或者被另外的分布式引用处理,而分布式应用往往能够处理这样被分隔后的小文件。另外,这里的 MapReduce 配合了 GFS 的使用,所以从磁盘读写直接使用的是 GFS 文件系统。
Master 与 Fault Tolerance
master 会记录每个 map task 和 reduce task 的状态 (idle, in-progress 或者 completed), 对于那些不是 idle 的 task,master 还会记录执行这个 task 的机器。
从上面描述的 MapReduce 流程可知,master 是 map worker 和 reduce worker 的桥梁,每个 map task 完成后都会将其产生的 M 个文件的路径和大小传输给 master,master 则会将这些信息 push 给那些有处于 in-progress task 的 reduce worker。
Fault Tolerance 可分为两大类:worker 的 Fault Tolerance 和 master 的 Fault Tolerance;而 worker 又可分为 map worker 和 reduce worker 两种,下面分别介绍针对这三种角色的 Fault Tolerance 的策略。
首先,master 会周期性地 ping 各个 worker,并根据是否收到回复来判断 worker 是否发生了宕机。
当一个 map worker 被 master 判为宕机后,这个 worker 所有的 task (包括 in-progress 和 completed 的) 都会被重置为 idle 状态,从而让这些 task 能够被重新分配给其他的 map worker 来重新执行。而发生这种重新执行的情况时,所有的 reduce worker 都会被告知重新执行的这个 task 的是哪个 map worker,从而让 reduce worker 从新的 map worker 那里读取数据(针对那些还没从已经宕机的 map worker 读取数据的 reduce worker,原来那些已经读了数据的 reduce worker 不需要)
当一个 reduce worker 被 master 判为宕机后,这个 worker 那些未完成的 task (也就是处于 in-progress 状态的) 会被置为 idle 状态,而已完成的 task 不会。这是因为 reduce worker 将输出写入 GFS,worker 宕机后数据仍然可以被读取,而 map worker 则是将输出结果写入到本地的磁盘,宕机后数据无法被读取
这里有两个问题值得思考:
- map worker 宕机后,reduce worker 从新的 map worker 读取的结果与从原来宕机的 map worker 读取的结果是否一致?
- 如果 reduce worker 在数据写入一半的时候宕机了,已经写入的数据怎么办?
第一个问题的答案是肯定的,因为 map 函数不记录状态,也就是对固定的输入有固定的输出,此外,reduce task 会在所有的 map task 完成后才开始执行,因此也保证了 reduce worker 总能读到 map worker 完整的输出文件。
第二个问题与 GFS 提供的 atomic rename 特性有关,reduce worker 会先将结果写入到临时文件中,直到所有的结果都完成后才将临时文件重命名为最终文件并写入 GFS 中;这个特性也让多个 reduce worker 重复执行一项任务时最终只产生一个文件。
针对 master 宕机的情况,论文的做法是令 master 周期性地往磁盘写入 checkpoint,重启 master 后从上次的 checkpoint 重新执行。
Load Balance,Backup Task 与 Locality
load balance 指的是某个 worker 执行 task 时间过长,导致其他已完成 task 的 worker 都在等待这个 worker 完成(因为任务之间有依赖性),这一执行时间过长的 worker 也被称为
文章针对这一问题的做法是把每个 task 分得尽量小,即 M (map task 的数量) 和 R (reduce task 的数量) 的值要远远大于机器数量。这样就不会出现某个 task 执行过的时间过长,不仅解决了上面的问题,还加速了 fault tolerance 后的 recovery。
除了 task 过大,出现 straggler 的原因也可能是机器本身的硬件问题,哪怕 task 已经分得很小了。文章解决这一问题的做法是当 straggler 出现的时候,master 会把 straggler 在做的 task 分给另外一个 worker 做,谁先做完就汇报给 master,而 master 也只会接收其中一个的完成的消息,这在文中称为 Backup Task。
在任意分布式系统中,当 worker 数量增多,网络通信的负载都会变大。文章利用了 MapReduce 和 GFS 架设在同一组机器上的特性,从而让 Map 过程从 GFS 读取文件时尽可能读取处于本地磁盘的的 copy(GFS 为每份数据创建了三份 copies),在本地磁盘找不到时才读取其他 worker 磁盘的数据,这样就大大减少了网络的开销,而文中又称这一特性为 Locality。
小结
回到文章开头提到的分布式系统中三个比较关注的问题,MapReduce 这篇论文中主要是关注其中的 performance 和 fault tolerance。
为了提升 performance,通过把 task 分得更小来获得更好的 load balance,通过 backup task 来降低 straggler 对整个系统的影响,通过 locality 来减少网络的负载。
针对 fault tolerance,则通过为 task 设定状态,失败的 worker 的 task 被重置为 idle 状态,从而找到新的 worker 重新执行这些 task。
每种框架都有其适用场景,而对于 MapReduce,首先就是任务要能够表达成一个或多个 MapReduce 过程,文中提到的一些任务包括: Distributed Grep、Distributed Sort、Count of URL Access Frequency、ReverseWeb-Link Graph、Inverted Index 等;其次数据量要足够大才能显示出 MapReduce 的效率 (其实对于任意分布式系统基本都是这样, 否则整个系统调度的开销比计算的开销还要大);还有就是涉及到多次 shuffle (也即是多个 MapReduce 过程) 时,由于要与磁盘多次交互,因此虽然能够实现,但是效率很低,这时候就要考虑其他更灵活的框架了。不要局限于一定要把算法表达成 MapReduce 过程,而是可以考虑更加灵活的框架,如 spark 等。