分布式系统笔记 (2)-RPC and threads
本系列文章是学习课程 6.824: Distributed Systems 时的一些学习笔记,整个课程的相关材料已整理至 DistributedSystemInGo。本文是 LEC2 的内容,主要介绍了 RPC 的概念并通过 RPC 实现了一个简单的 c/s 架构的 kv 数据库;同时介绍了多线程编程并通过两种方式实现了一个多线程爬虫。
这门课程采用的语言是 go,原因是 go 对 concurrency、RPC 和 gc 等有较好的支持,且上手较快,可以把问题集中在分布式系统而不是由于对语言不熟悉而带来的 bug。因此,上面提到的两个 demo 也是采用 go 实现。
RPC
RPC 基本概念
RPC (Remote Procedure Call) 的概念很好理解,类比函数调用,只是两个函数不在一个内存空间,不能直接调用,需要通过网络进行远程调用。RPC 的调用过程如下,图片摘自 Remote Procedure Calls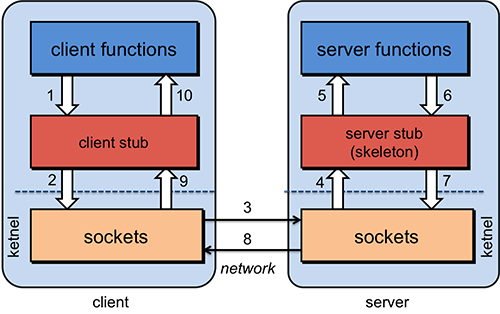
需要明确的一点是 RPC 只是一个概念,因此广义上任意实现远程调用的方法都可称为 RPC(如 http),而区别于各个 RPC 的实现 (RPC 框架) 在于其实现的协议的不同,而最基本的协议包含编码协议和传输协议。
编码协议表明了该如何将要传递的参数等信息打包好;常见的有基于文本编码的 xml、 json,也有二进制编码的 protobuf、binpack,也可自定义协议。
而传输协议则表明如何将打包好的数据传输到远端;如著名的 gRPC 使用的 http2 协议,也有如 dubbo 一类的自定义报文的 tcp 协议 (精简了传输内容) 等。
类似于计算机网络中的各种协议一样,这些协议是比较繁琐的且通用的,因此产生了很多 RPC 框架来完成这些协议层面的东西,而除了上面提到的最基本的编码协议和传输协议,成熟的 rpc 框架还会实现额外的策略, 如服务注册发现、错误重试、服务升级的灰度策略,服务调用的负载均衡等。上面提到的 gRPC 和 dubbo 就是两个比较有名的 RPC 框架,通过 RPC 框架,在编码时能够像本地调用一样使用 RPC。
对于一个 RPC 框架,实现中最关注以下三点 (1) Call ID 映射:即告诉远程服务器要调用的是哪个函数或应用 (2) 序列化和反序列化:即上面的编码协议 (3) 网络传输:即上面的传输协议 更详细的解析可参考这个回答,谁能用通俗的语言解释一下什么是 RPC 框架? - 洪春涛的回答,
RPC in go
go 提供了自己的 rpc 库,这里通过这个库来实现一个简单的 c/s 架构的 kv 数据库
server 端的核心代码如下,KV 这个 struct 提供了 Put 和 Get 这两个存取方法,且存取时通过 sysc.Mutex 进行加锁来保证一致性。通过 go 内置的 rpc 框架启动一个 server 且将 KV 注册在 1234 端口,网络传输采用的是 tcp 协议;每当 server 与一个 client 建立一个连接时,server 会启动一个线程 (goroutine) 去处理这个连接对应的请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52type KV struct {
mu sync.Mutex
keyvalue map[string]string
}
func (kv *KV) Get(args *GetArgs, reply *GetReply) error {
kv.mu.Lock()
defer kv.mu.Unlock()
reply.Err = "OK"
val, ok := kv.keyvalue[args.Key]
if ok {
reply.Err = OK
reply.Value = val
} else {
reply.Err = ErrNoKey
reply.Value = ""
}
return nil
}
func (kv *KV) Put(args *PutArgs, reply *PutReply) error {
kv.mu.Lock()
defer kv.mu.Unlock()
kv.keyvalue[args.Key] = args.Value
reply.Err = OK
return nil
}
func server() {
kv := new(KV)
kv.keyvalue = map[string]string{}
rpcs := rpc.NewServer()
rpcs.Register(kv)
l, e := net.Listen("tcp", "ServerIP:1234")
if e != nil {
log.Fatal("listen error:", e)
}
go func() {
for {
conn, err := l.Accept()
if err == nil {
go rpcs.ServeConn(conn)
} else {
break
}
}
l.Close()
fmt.Printf("Server done\n")
}()
}
client 端的程序如下,client 首先通过 Dial 函数 与 server 建立连接,Get 和 Put 则分别调用了 server 端对应的 Get 函数和 Put 函数(在 rpc.Call 中声明), 可以看到,进行 RPC 就如同本地调用一样1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30func Dial() *rpc.Client {
client, err := rpc.Dial("tcp", "ServerIP:1234")
if err != nil {
log.Fatal("dialing:", err)
}
return client
}
func Get(key string) string {
client := Dial()
args := &GetArgs{"subject"}
reply := GetReply{"", ""}
err := client.Call("KV.Get", args, &reply)
if err != nil {
log.Fatal("error:", err)
}
client.Close()
return reply.Value
}
func Put(key string, val string) {
client := Dial()
args := &PutArgs{"subject", "6.824"}
reply := PutReply{""}
err := client.Call("KV.Put", args, &reply)
if err != nil {
log.Fatal("error:", err)
}
client.Close()
}
完整的代码可参考这里
failure in RPC
上面只是一个简单的 RPC 例子,没有考虑到这个过程中可能出现的异常情况。而最常见的异常个情况就是 client 发出 request 后收到不 server 的 response,引起这种问题的原因有很多:网络断了、server 宕机了等。针对这个问题有什么解决方法呢?
最直观也是最简单的方法是让 client 等待一段时间收不到回复后的重新发送 request,且设置重复发送的次数的上限,如果超过这个上限,则先调用的应用程序返回 error 异常信息。
但是,当 client 重复发送请求时,server 有可能已经收到了 client 的前一个请求,只是网络的延迟使得 client 还没收到 response,那这时候 server 就会收到重复的 request。如果 client 发出的是读请求,那么问题不大;但是如果是写操作,server 端就需要处理这些重复的写请求从而使得最终只有一个被执行。
这里可针对 server 端采取 at most once 的策略,即同一个 request 最多只能在 server 端被执行一次,如果收到了重复的 request,那么就将之前的结果返回。这样需要解决的问题就是为每个 request 生成一个 unique id,生成 unique id 也有很多方法,比如说可以利用 client 的 ID 及其 request 编号的组合等方法。
go 的 RPC 库采用的就是 at most once 的策略,库已经在传输层进行了过滤重复 request 的操作,因此在代码中无需体现这一操作。
threads
多线程是 concurrency 的重要手段,在 golang 中的 thread 也被称为 goroutine,一般多线程都能够充分利用 CPU 的多个核 (Python 的 Cpython 解析器除外,GIL 的限制)
进行多线程编程时有以下几点值得注意:
(1)同一个进程内的线程是共享地址空间的,因此在对共享数据进行写操作时需要加锁 (2)当任务间有依赖性,一项任务拆分给多个线程去完成时,线程间往往需要先共完成任务 A 才能开始任务 B (3)要确定线程并行的粒度,比如说多线程爬虫,每个线程是负责一个站点?还是站点下的一个目录?一般粗粒度的实现会很简单,但是并行性不高;而细粒度的并行化程度会更高,但是会更容易出现死锁等问题。
下面会通过 golang 实现一个多线程爬虫,分别采用了两种方式,第一种是通过经典的队列方法(channel),这种防范没有加锁;第二种则通过加锁 (mutex) 和设定任务完成的 threshold (waitgroup);在这个例子中两种方式的并行化粒度均是网页
channel
队列是很常见的多线程编程采用的方式,将需要执行的任务送入队列,然后线程从队列中取出任务执行,并将新的任务入列 (在这个例子中就是当前网页所含有的其他网页的链接),这里还需要额外检查网页是否已经被抓取过原因有两个
(1)网页间的指向有可能形成闭环,不判断会导致死循环 (2)效率问题,不希望执行重复工作
因此,golang 通过 channel 完成的多线程爬虫如下所示,master 从队列头读出一个网页并判断其是否已经被执行,如果没有执行,就启动一个 goroutine 来执行 dofetch 任务,dofetch 会将其当前网页所指向的其他网页入列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37func dofetch(url1 string, ch chan []string, fetcher Fetcher) {
// body is content of url1, urls are those to which url1 refer
body, urls, err := fetcher.Fetch(url1)
if err != nil {
fmt.Println(err)
ch <- []string{}
} else {
fmt.Printf("found: %s %q\n", url1, body)
ch <- urls
}
}
func master(ch chan []string, fetcher Fetcher) {
n := 1
fetched := make(map[string]bool)
for urls := range ch {
for _, u := range urls {
if _, ok := fetched[u]; ok == false {
fetched[u] = true
n += 1
go dofetch(u, ch, fetcher)
}
}
n -= 1
if n == 0 {
break // or close(ch)
}
}
}
func CrawlConcurrentChannel(url string, fetcher Fetcher) {
ch := make(chan []string)
go func() {
ch <- []string{url}
}()
master(ch, fetcher)
}
那终止的条件是什么呢?队列为空,但是在 golang 中没有显示判断 channel 为空的方法,且通过 for 遍历 channel 时,只有关闭了 channel 后循环才能正常退出,否则会出现 deadlock 的错误,但是显然无法随意关闭 channel,因为每一个 goroutine 都不知道是否还有其他的 goroutine 要写入这个 channel;上面的解决方法是通过 n 来记录当前队列的长度,如果 n == 0 就关闭 channel 或退出
mutex 与 waitgroup
上面只是在 master 中判断某个 url 是否已经被访问过了,那么每个独立的 goroutine 能否自行判断某个 url 是否别访问过了呢?答案是肯定的,只是需要对存储 url 是否被访问的 hashmap 进行加锁,在 golang 中可通过 sys.Mutex 对某个数据进行加锁和解锁操作
同样,我们需要设定终止条件。该如何衡量所有任务都完成,这里我们可以想像一颗多叉树的结构,每个节点表示一个网页,而每个节点的子节点是其网页中指向的其他网页,那么一个节点被判为完成当且仅当其所有的子节点都完成,这就涉及到了上面提到的任务间的依赖性问题,实际上就是要等待 goroutines 共同完成当前节点的所有子节点,这要用到 sys.Waitgroup 实现的具体代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44type fetchState struct {
mu sync.Mutex
fetched map[string]bool
}
func (f *fetchState) CheckAndMark(url string) bool {
defer f.mu.Unlock()
f.mu.Lock()
if f.fetched[url] {
return true
}
f.fetched[url] = true
return false
}
func mkFetchState() *fetchState {
f := &fetchState{}
f.fetched = make(map[string]bool)
return f
}
func CrawlConcurrentMutex(url string, fetcher Fetcher, f *fetchState) {
if f.CheckAndMark(url) {
return
}
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("found: %s %q\n", url, body)
var done sync.WaitGroup
for _, u := range urls {
done.Add(1)
go func(u string) {
defer done.Done()
CrawlConcurrentMutex(u, fetcher, f)
}(u) // Without the u argument there is a race
}
done.Wait()
return
}
上面可以说是 sync.WaitGroup 的经典用法,在为每个线程分配任务时通过 done.Add(1) 增加未完成任务, 在线程完成任务时通过 done.Done() 表示当前子任务已完成,通过 done.Wait() 阻塞直到所有的子任务都完成。
小结
这一课介绍了 RPC 和多线程编程的基本概念,并分别用 go 语言实现了一个简单的例子,主要是为后面的几个实验做准备。
RPC 是个广义的概念,RPC 需要解决最基本的通信协议和编码协议;除此之外,一些高级的 RPC 框架还帮我们处理了、服务注册发现、错误重试等细节,让远程调用如同本地调用一样。
关于多线程编程,给出的爬虫例子实现了两种形式的多线程编程,一种是 Mutex + WaitGroup 的方式,一种则是 Channel 的方式;需要注意的是,这两种方式不是非此即彼,而是可以混用的,可以参考 MutexOrChannel 的介绍,比如说通过 Mutex 来让每个单独的线程判断某个 url 是否被访问过,通过 Channel 来将未完成的队列入列,通过 WaitGroup 来分类下载资源(其实这也涉及到了并行的粒度的划分,即并行地下载某一类的资源)。回想起来,很久之前写的一个爬取几个输入法的词库的程序 ThesaurusSpider 就是这么做的,只是通过 python 实现而已,有兴趣可参考。
参考:
- 既然有 HTTP 请求,为什么还要用 RPC 调用?
- 谁能用通俗的语言解释一下什么是 RPC 框架?