《链接、装载与库》 阅读笔记 (2)- 可执行文件的装载
本文是链接、装载与库中关于可执行文件装载的过程,主要描述了进程在被装载时虚拟空间是如何分布的,物理内存空间与虚拟地址空间是如何映射的,同时描述了 Linux 系统下装载一个可执行文件的基本过程。
基本概念
可执行文件只有被装载到内存后才能被 CPU 执行,因为程序执行时所需要的指令和数据必须在内存中才能正常运行,这部分细节涉及到 CPU 的内部组成架构,具体可参考文章 程序的表示、转换与链接 - week1 中 现代计算机的模型结构和工作原理部分
而在每个程序被运行起来后都有自己独立的虚拟地址空间 (Virtual Address Space), 这个虚拟地址空间大小由计算机的硬件平台决定 (CPU 的位数),如 32 位的 CPU 上寻址空间是 0-2^32-1 (4GB)
但实际上这 4GB 的虚拟空间并不能全部被程序使用,因为操作系统会占掉一部分内存。如果进程访问了未经允许的地址,在 Linux 下会出现 segment fault 的错误
在程序装入内存过程中,往往会出现某个程序需要的内存比当前物理内存大得多的情况,这种情况下就需要动态装载了,动态装载的基本原理:程序运行时是有局部性的,因此可以将程序最常用的部分放在内存中,不常用的放在磁盘中
目前常用的方法是页映射 (paging), 就是把内存切成小块(page)再分配,当有新的空间申请时,按照一定算法驱逐已分配内存的空间(如 FIFO、LUR), 如下图所示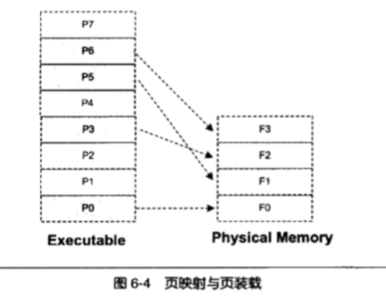
从操作系统看可执行文件的装载
从操作系统的角度来看,一个进程最关键的特征是它拥有独立的虚拟地址空间,这使得该进程能跟其他进程区分开来
从操作系统角度来看,创建一个进程,然后装载相应的可执行文件并执行,在有虚拟存储的情况下,需要做三件事
- 创建一个独立的虚拟地址空间
- 读取可执行文件头,建立虚拟空间与可执行文件的映射关系
- 将 CPU 的指令寄存器设置成可执行文件的入口地址,启动运行
宏观来说,步骤 1 相当于是建立虚拟地址空间到物理地址空间的映射关系,步骤 2 则是建立虚拟地址空间到可执行文件的映射关系,步骤 3 则是跳转指至可执行文件的入口(保存在 ELF 文件头中)然后开始执行。
步骤 2 是传统意义上 “装载” 的过程最重要的一步,因为步骤 1 只分配了一个页目录,具体的映射交给了步骤 2,而当程序执行发生页错误的时候,操作系统会从物理内存中分配一个物理页,然后将该 “缺页” 从磁盘读取到内存中,再设置缺页的虚拟页和物理页的映射关系
因此,操作系统捕获到页错误的时候,需要知道程序当前所需要的页在可执行文件中的偏移位置,这就是虚拟空间与可执行文件的映射关系,这种关系会保存在一个数据结构中,在 Linux 中会保存在进程中,记录每个段对应的虚拟地址范围和所在可执行文件的位置,称为 VMA (Virtual Memory Area)
如下图所示,在进程创建后,进程内部会有一个 .text 段的 VMA ,属性为只读,在虚拟空间的地址为 0x08048000-0x08049000,这个大小就是 32 位 IntelIA32 的一个页的大小,哪怕 .text 的数据没这么多也会占用掉一个页的大小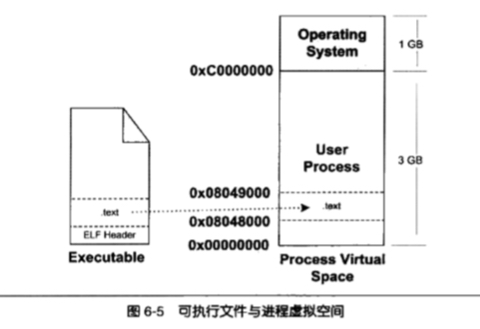
那上面提到的页错误(PageFault)指的是什么呢?其实在做完上面三个步骤后,只是建立了映射关系,可执行文件还没被装载到内存中执行。以上图为例,在进程开始执行时,会发现入口地址对应的页 0x08048000-0x08049000 是个空页面,进而触发一个页错误,CPU 把控制权交给操作系统,操作系统查询进程的 VMA,计算出相应页面在可执行文件中的位置,进而在物理内存中分配一个物理页,将进程中改虚拟页与物理页简历映射关系,再把控制权交给进程。如下图所示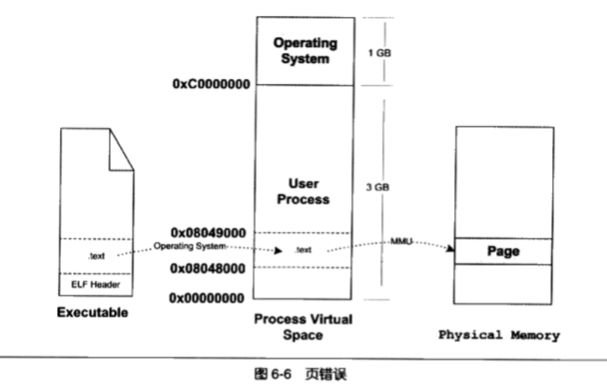
进程虚拟空间分布
section 与 segment
对于前面提到的可执行文件中的每个段,假如都要在物理内存中分别分配一个 页,这样会导致页面内部碎片情况严重,同时浪费内存,因为一个段的大小可能会远小于一个页的大小
解决这个问题的方法是将相同权限的段合并到一起当做一个段处理,称为 segment,如下图所示是将两个 .text 段合并成一个,从而使得原来需要分配三个页的物理内存变成只需要分配两个页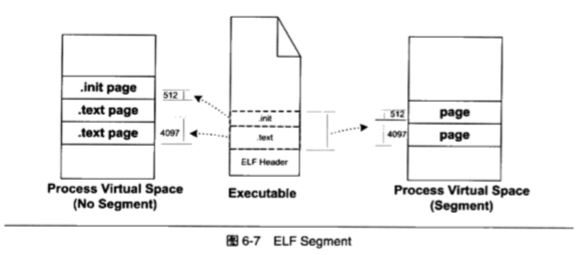
在最开始讨论 ELF 文件时也有段的概念,为了与这里的段区分开,在英文中 ELF 文件中原始的 “段” 被称为 section,虚拟空间地址后被称为 segment,实际上,这是看待 ELF 文件的两个视角,如下图所示,左边的 section 会被合并成右边的 segment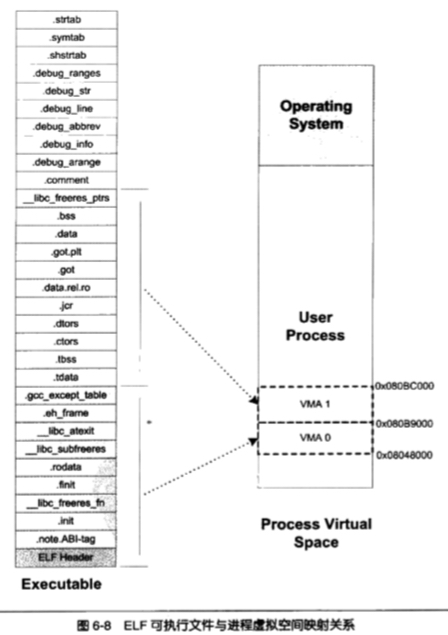
因此最终分配物理内存时是以 segment 来映射的,通过 readelf -S 可看到 elf 文件的 section,通过 readelf -l 则可看到 elf 文件的 segment, 如下图是一个简单例子,有 20 + 的 section,但是只有 5 个 segment,且 segment 中只有类型为 LOAD 的两个段才需要被映射到物理内存中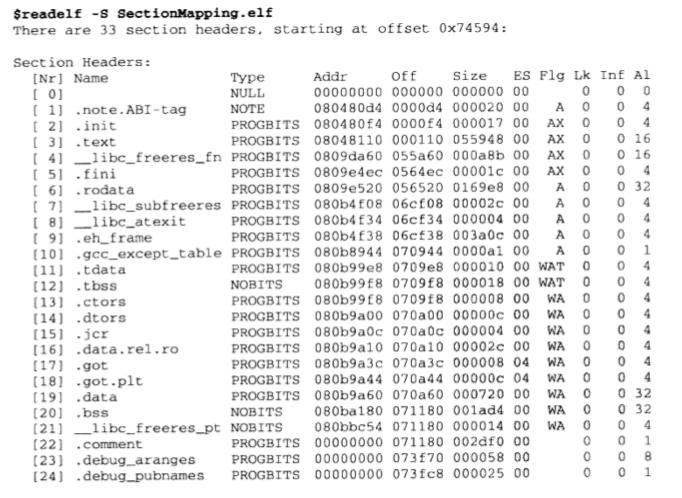
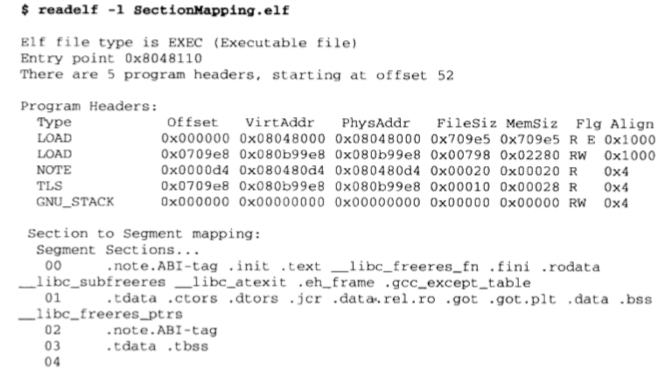
类似 section 有段表,ELF 可执行文件中也有 一个专门的数据结构叫程序头表(program header table),用来保存 segment 的信息,值得注意的是,因为 ELF 目标文件不需要被装载,所以没有程序表头
程序表头的结构体即各个字段的含义如下图所示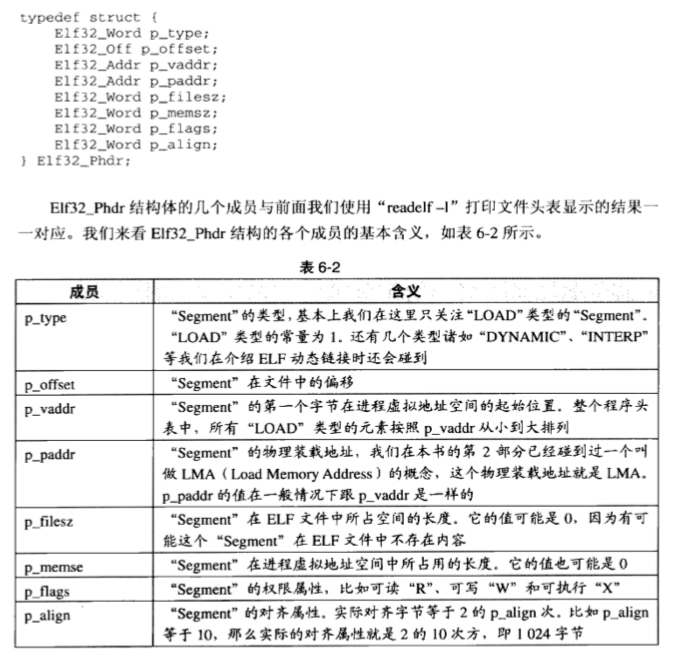
堆与栈
因为进程在运行过程中需要用到堆和栈,而堆和栈在虚拟空间中的表现也是以 VMA 形式存在的,在 Linux 下,可通过查看 /proc 来查看进程的虚拟空间分布,如下图所示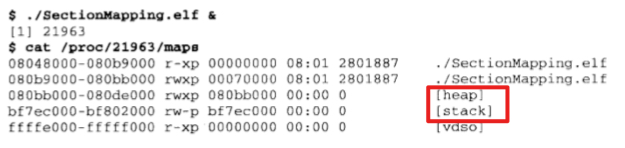
上面结果中主要关注的是几列表示的含义如下:第一列是 VMA 的地址范围,第二列是 VMA 的权限 (p 表示 COW,copy on write), 第三列是 VMA 对应的 segment 在映像文件中的偏移,最后一列是映像文件的路径
进程栈初始化
在进程刚启动的时候,需要知道一些进程运行的环境,如系统环境变量和进程的运行参数;因此操作系统在进程启动前会将这些信息提前保存到进程的虚拟空间的栈中(即 VMA 中的 stack VMA)
假设系统中有两个环境变量: HOME=/home/usr 和 PATH=/usr/bin, 如下图运行命令 prog 1234 后,进程的栈分布如下图所示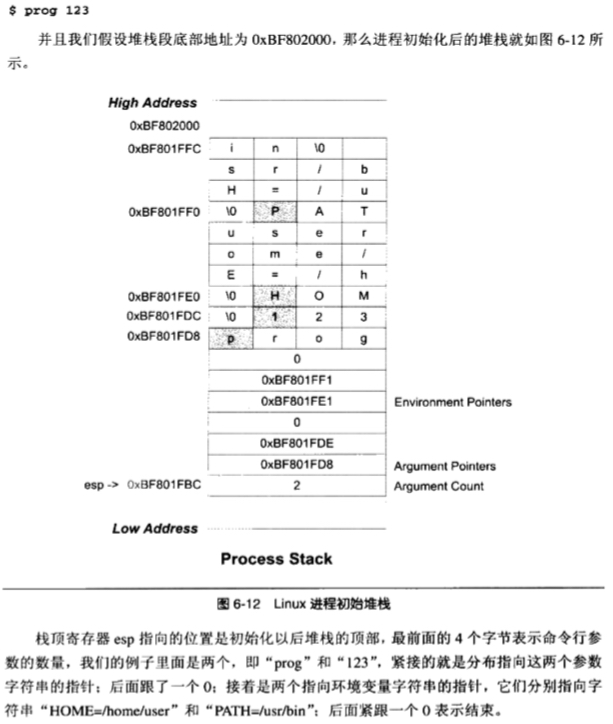
栈顶的 esp 寄存器指向的位置是初始化后的堆栈地址,前面四个字节表示的是命令行参数的格式,这里所谓 2 (即 prog 和 123),然后就是指向这两个参数的指针,后面跟着一个 0,紧着是指向两个环境变量的字符串的指针(即 HOME 和 PATH 这两个环境变量)
在进程启动后,程序的库部分会把堆栈的初始化信息中的参数信息传给 main() 函数,也就是熟知的 main () 函数的两个 argc 和 argv 两个参数,分别对应于命令行参数数量和命令行参数字符串指针数组。
小结
通过上面的例子可知,进程中的虚拟地址空间可理解为操作系统给进程空间划分出一个个的 VMA 来管理进程的虚拟空间,基本原则是将属性相同、有相同映像文件的映射成同一个 VMA,一个进程基本可映射成以下几个 VMA(segment)
- 代码 VMA,权限只读、可执行;有映像文件 (即 elf 文件)
- 数据 VMA,权限可读写、可执行;有映像文件
- 堆 VMA,权限可读写、可执行;无映像文件,可向上拓展
- 栈 VMA,权限可读写、不可执行;无映像文件,可向下拓展
因此,一个进程的虚拟地址空间如下图所示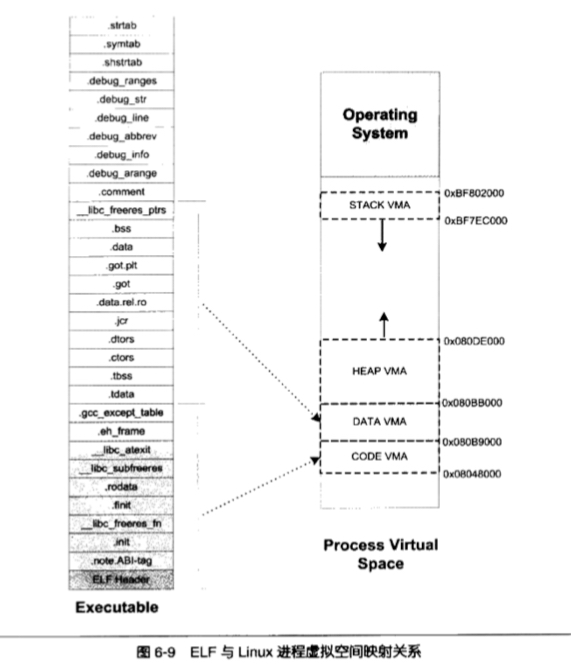
Linux 内核装载 ELF 可执行文件过程
下面会简单介绍在 Linux 系统的 bash 下输入一个命令执行某个 ELF 程序时,Linux 系统是怎么装载这个 ELF 文件并执行它的。
在用户层面,主要有三个步骤
- bash 进程会调用
fork()系统调用来创建一个新的进程 - 新的进程调用
execve()系统调用来执行指定的 ELF 文件 - bash 进程返回并等待前面启动的进程结束,然后用户再输入新的命令(可以用
&让程序在后台运行)
execve() 函数定义如下, 其三个参数分别表示可执行文件名、执行参数和环境变量,其中执行参数和环境变量对应于前面提到的进程栈的初始化中存储的相关内容
int execve(cosnt char* filename, char *const argv[], char *const envp[]);
execve() 在找到可执行文件后,首先会读取文件前 128 个字节,其目的是为了判断文件的格式,因为 Linux 执行的可执行文件不知 ELF 一种,还有 Java、以及以 #! 开始的脚本程序等
每种可执行文件
的格式的开头几个字节都是很特殊的,尤其是开头的四个字节(被称为 magic number),通过 magic number 可判断文件的格式和类型,如 ELF 文件前四个字节是 0x7F、'e'、'l'、'f';而 Java 可执行文件格式头 4 个字节为 'c'、'a'、'f'、'e';如果是 shell、python、perl 这类解释型的语言,第一行往往是 #!/bin/bash、 #!/usr/bin/python、 #!/user/bin/perl
execve() 读取了 128 个字节的文件头部后,会调用 search_binary_handle() 去搜索和匹配合适的可执行文件装载处理过程,不同类型的可执行文件格式都有相应的装载处理过程,如 elf 可执行的装载处理过程叫 load_elf_binary(), 装载可执行脚本程序的处理过程叫 load_scrip() , 这里主要描述load_elf_binary() 的基本过程
- 检查 elf 可执行文件的有效性,比如说 magic number,program header 中 segment 的数量
- 寻找动态链接的 .interp 段,设置动态链接的路径(后面会有一篇文章专门描述动态链接)
- 根据 elf 可执行文件的 program header 描述,对 elf 文件进行映射,比如代码、数据、只读数据等
- 初始化 elf 进程环境
- 将系统调用的返回地址改成 elf 文件可执行文件的入口点,这个入口点取决于程序的链接方式,如对于静态链接的 ELF 文件,这个入口就是 ELF 文件的文件头中
e_entry所指的地址;对于动态链接的 ELF 文件,这个入口就是动态链接器
当 load_elf_binary() 执行完后,第五步会令 EIP 寄存器直接跳转到 ELF 程序的入口地址,于是程序就开始执行,ELF 可执行文件装载完成。
总结
这一章主要描述了程序运行时是如何使用内存空间的,即程序如何被装载到内存中(页映射模式);然后详细介绍了进程虚拟地址空间的分布,即操作系统如何为程序的代码、数据、堆和栈在进程中分配虚拟地址空间 (VMA), 最后介绍了 Linux 系统下是如何装载 ELF 可执行文件的,且这一章中描述的都是在都是静态链接,即只有一个可执行文件,后面会描述动态链接,即一个可执行文件会被拆成若干个模块。