《Embedding-based Retrieval in Facebook Search》阅读笔记
Embedding-based Retrieval in Facebook Search 是 FB 在 2020 年发表的一篇搜索场景下如何做向量化召回的 paper,整篇文章读下来,就像是一个奋战在一线的工程师向你娓娓道来他们是怎么从 0 到 1 构建一个召回系统,从训练数据与特征的选取, 到模型的 training 与 serving、再到把新的召回策略融入现有的 ranking system, 整篇 paper 并没有太多的公式与推导,但是却有很多在实战中总结出来的经验,而且这些经验相信也可以推广搜索以外的推荐 / 广告领域。本文主要是根据笔者对这篇 paper 的理解做一些提炼,推荐读原文。
笔者认为这篇 paper 值得关注的点如下
- 召回模型的负样本的选取(为什么不能只选取曝光未点击的样本作为负样本,easy negative 与 hard negative)
- 新的召回策略如何克服当前 ranking system 的 bias
- 构建一个召回系统的常规流程及每个流程中的一些经验
后面介绍的内容与 paper 中的基本保持一致,且主要介绍其中一些关键点
System Overview
在推荐、广告和搜索的场景下基本的架构都是召回 (Retrival)+ 精排(Ranking),因为这三者其实都是要在每条请求到来的时候从一个庞大的候选集中选取出 topk 个返回给用户,而召回作为这个流程的入口,面对的几乎是整个候选集,为了在延迟上满足要求,召回不会采用太复杂的模型和特征,且往往会对 item 做倒排索引 (Inverted Index)。
paper 中的系统总体的架构如下,在每条请求到来的时候会实时计算用户的 embedding,然后利用构建好的 document embedding 倒排索引做 retrival,为了加速,在向量化召回中还会采用 Quantization 技术 (在后面的 serving 步骤中介绍)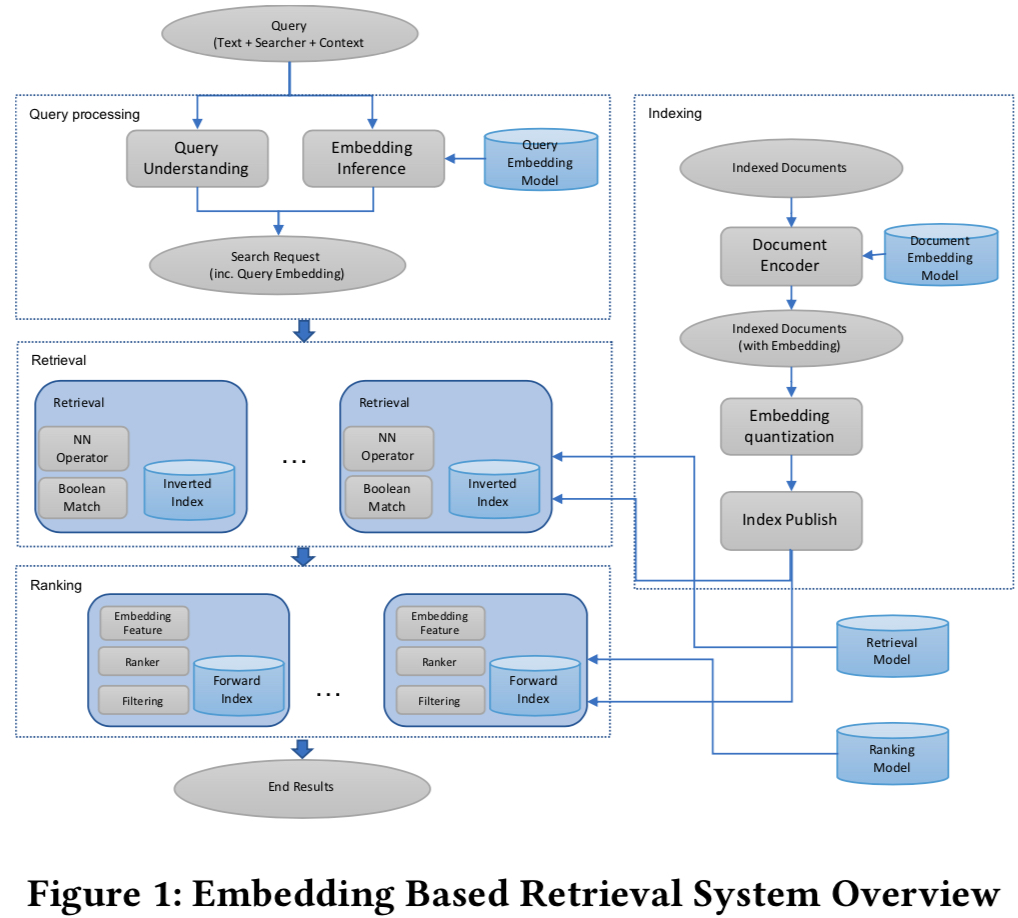
Model
这里的 model 主要指上图中的 Query Embedding Model 与 Document Embedding Model,即生成 embedding 的模型,采用的也是很经典的双塔模型,如下图所示; 这里的 unified embedding 主要是指这个 embedding 输入的原始 feature 不仅仅包含 query 和 document 本身的文本信息,还有对应的上下文信息 (context) 信息, 这种做法其实在 google 2016 发表的那篇 Deep Neural Networks for YouTube Recommendations 已经有了,而这也是 NN 模型比起 Matrix Factorization 等方法生成 embedding 的优点;可以添加更多的 feature 到模型中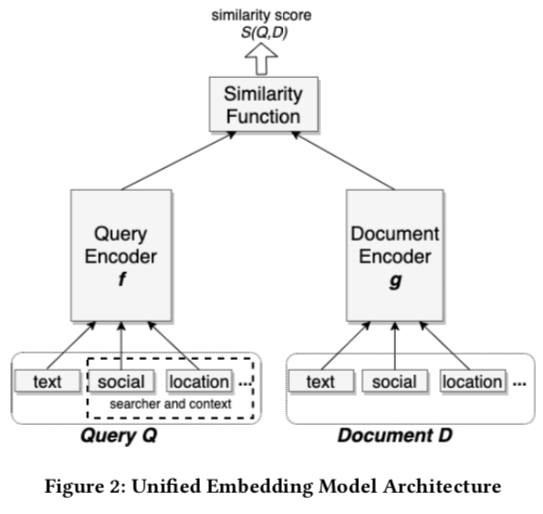
损失函数
模型采用的损失函数是 triple loss,最早是在人脸识别中提出的一个 loss,假设每条训练样本是 \((q^{(i)},d_+^{(i)}, d_-^{(i)})\), 式子中的 \(d_+^{(i)}\) 表示与 query \(q^{(i)}\) 相关的 document,而 \(d_-^{(i)}\) 表示与 query \(q^{(i)}\) 不相关的 document, 则 paper 中的 loss 定义如下
\[\begin{align} L=\sum_{i=1}^{N} \max(0, D(q^{(i)},d_+^{(i)}) - D(q^{(i)},d_-^{(i)}) + m) \end{align}\]
上式中的 \(m\) 是一个超参,表示正样本与负样本的 enforced margin,表示正负样本的 distance 假如大于 m,则认为这个是一个 easy example 不需要模型进一步学习去区分了;paper 中提到了这个超参对结果影响较大,因为不同的任务的最优的 m 往往不一样。
上面的 D 表示距离函数 (越小表示越相似),paper 中采用的 distance 函数是 \(D(q,d) = 1-cos(q, d)\),
此外,针对 paper 中的训练样本对,其实也可以采用经典的 LTR 中的 pariwise loss,具体可参考 From RankNet to LambdaRank to LambdaMART: An Overview
此外,paper 中的 采用的指标是离线评估的召回率(recall),采用的验证集是 10000 个 search session 中每个 query 及其 target result(paper 中并无明确给出这一标准,只是提到按照点击或人工评估方式来获取均可以)
训练样本
训练样本的选取是 paper 中的一个着重强调的一个点,且关键点在于负样本的选取,paper 中选取的正样本是点击样本,而负样本则做了下面的两组对比
- 随机选取负样本
- 选取曝光未点击的样本作为负样本
实验结果显示选取曝光未点击的样本作为负样本时,其效果比随机选取负样本要差很多;paper 中对这一现象的解释是
We believe it is because these negatives bias towards hard cases which might match the query in one or multiple factors, while the majority of documents in index are easy cases which do not match the query at alll. Having all negatives being such hard negatives will change the representativeness of the training data to the real retrieval task, which might impose non-trivial bias to the learned embeddings.
笔者理解采用曝光未点击的样本作为负例,其实就是造成了 training 与 serving 的不一致性,因为曝光未点击的样本大部分是 hard cases,即使最终未被点击,但是与 query 也还是有一定相关性的,但是线上召回时面对的候选集是全部的候选,其中有绝大部分与本次 query 无关的 easy cases。当负例全部采用 hard cases,实际上与最终的 serving 就是不一致的,而 paper 中共则说这种行为 “might impose non-trivial bias to the learned embeddings”
除了负例,paper 中也探索了正例的选择,关于正例的选择做了下面两组的对比
- 选取点击作为正例
- 选取曝光作为正例
实验结果显示在数据量相同的情况下,两者效果基本一致,即使是在曝光的正例基础上叠加点击正例,结果也没有进一步的提升。
关于正例的选择,虽然 paper 中称两类正样本差别不大,但是笔者认为在实际中采用曝光样本作为正例更合适,原因如下
- 点击一般是比较稀疏的,数据量较少
- 未点击的样本不应就不是好的样本,有可能只是位置等原因导致的,相比于点击样本,采样这样的样本一定程度上相当于做了 Explore
hard mining
这部分内容是 paper 中第六节的内容,但也是训练样本选取的一个关键点,因此放在这里一起说明。
前面提到,选取负样本的时候不能选择曝光未点击的 hard cases,但是凡事有多个度,当负例中的样本都是很容易就能跟正例区分开的 easy cases,模型也不一定能学得好,paper 中对这一现象描述如下
This motivated us believe that the model was not able to utilize social features properly yet, and it’s very likely because the negative training data were too easy as they were random samples which are usually with different names. To make the model better at differentiating between similar results, we can use samples that are closer to the positive examples in the embedding space as hard negatives in training.
这里的 hard nagative 指的就是那些与正例相似性较高的负例 (现对于随机选取的负例),但是这里的 hard nagative 并不是那些曝光未点击的负例,paper 中提出了两种方法来挖掘 hard nagative:online hard negative mining 和 offline hard nagative mining,两种方法的基本流程如下
online hard negative mining
在每个 batch 的训练中,假设正样本对为 \(\lbrace(q^{(i)},d_+^{(i)})\rbrace_{i=1}^{n}\), 则对于每个 query \(q^{(i)}\), 会从 \(\lbrace d_+^{(1)} \dots d_+^{(j)} \dots d_+^{(n)} | j \ne i\rbrace\) 中随机选出 k 个 document 作为 hard nagative,paper 中称其场景下 k = 2 是最优的,如果多了会导致模型的效果下降
paper 中的实验数据表示加入这样的 hard nagative 后,在不同类型的 iterm 的搜索上的召回率均有提升。
但是实际上以这种方式选取出来的负样本还不够 hard,原因也很简单,因为这些 negative 是属于不同的 query 的,不同 query 的相关性不高,因此这些样本的相似性也不高,因此有了 offline hard negative mining
offline hard nagative mining
offline hard nagative 的做法更像 LTR 的 pairwise 样本构造了,其选取 negative 的方式是在每个 query 的所有 document 中,选择那些排序在 101-500 的位置的样本作为 hard nagative;值得注意的是,选择那些 hardest 的 negative 的效果并不是最优的(如排序在第二名的那些)
上面提到的是负样本的 mining,但是同样也可以针对正样本做这样的 hard mining,但是 paper 这一块篇幅较少,细节说的也不是非常清晰,只是提到了 “we mined potential target results for failed search sessions from searchers’ activity log”, 大意就是从那些失败的 search session 的日志中找到那些没被系统召回的但是 positive 的样本,笔者猜测这些可能是因为工程上的失败导致没被 send 出来但是日志里面已经显示排序的第一名的样本
综上,在召回样本的选取上,paper 强调了负样本中的要同时包含 easy nagative 和 hard nagative,paper 的观点是 hard nagative 更关注 non-text 的特征(如 social 特征等),而 easy nagative 则更关注 text 的特征,因此需要混合两者使用,而混合的方式有两种,分别是
(1)blending, 即混合两者一起来训练,paper 中给出两者的最优比例大概是 easy:hard ≈ 100:1
(2)transfer learning from “hard” model to “easy” model, 即先用 hard nagative 训练模型,然后用 easy nagative 训练模型(但是 paper 提到从 “easy” model 到 “hard” model 并不能达到相同的效果)
Feature Engineering
这里的 Feature Engineering 着重强调的是在 query 和 document 的 text feature 基础上加入一些其他的 context feature (paper 中主要提出了两种,location feature 和 social embedding feature) 能取得取得较大提升,下面简单介绍一些这几种 feature
text feature
对于文本特征的构建,paper 中采用的是 character n-gram 而不是 word n-gram,这里的 n-gram 其实就是把连续的 n 个 character 或 word 作为一个 item 输入到 embedding table 中做 embedding lookup,paper 中通过实验证明了采用 character n-gram 比起 word n-gram 效果要更优,分析其优点如下
- embedding lookup table 的 size 更小,能更好的学习到 embedding table 中的参数,其实就是降低了 model size
- 对于出现在训练集以外的单词有更好的鲁棒性,因为 embedding 的粒度是 character
location feature
paper 在 query 和 document 中均添加了了 localtion feature;对于 query,添加的 feature 包括 searcher’s city/region/country/language, 对于 document,则采用一些 publicly available information 如一些 explicit group location 的 tag 之类的
下面是加入了 localtion feature 前后同一个 query 返回的 document 的对比,可以看到加入 location feature 后,返回的搜索结果中的 document 的 location 信息与 searcher 的更加相似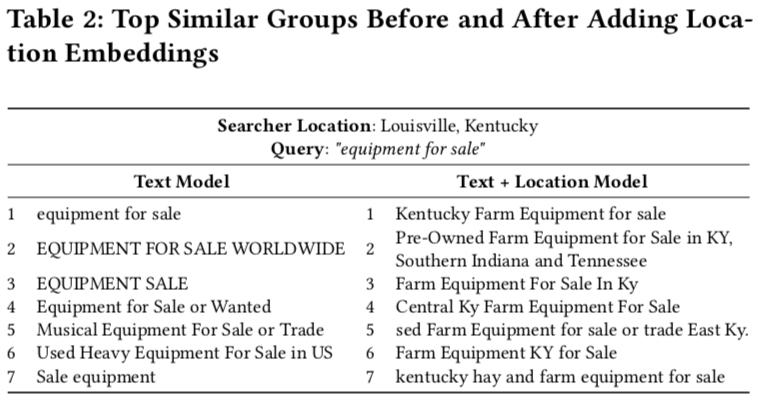
social embedding feature
关于这个 feature paper 中并无详细说明,猜测是通过类似 graph embedding 的方式来得到这个 embedding,然后作为 feature 输入给召回模型
下面是加了 location feature 和 social embedding feature 后得效果提升情况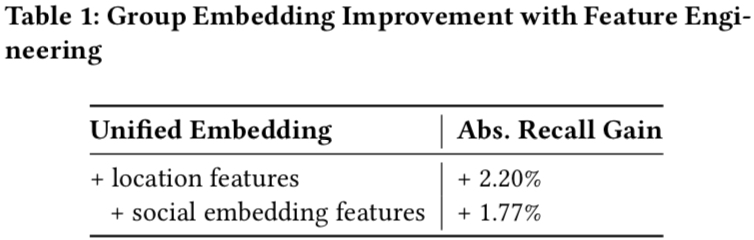
Serving
serving 采用的是 ANN(Approximate Near Neighbor),且通过 quantization 来进一步缩短向量间相似性的计算时间,quantization 相当于是一种向量压缩的技术;关于 product quantization 可参考 理解 product quantization 算法 这篇文章
实际中的向量化召回系统往往会包含两个步骤,indexing 和 scoring,indexing 是为了过滤大部分基本无关的候选,而 scoring 则是在相关的候选中进行计算与排序,indexing 常用的技术有 K-means、HNSW、LSH 等,而 scoring 则主要是各种 quantization 及其变种方法
上面这两个步骤在不同的地方的叫法可能也不一样,如在 paper 中这两个步骤就被称为 coarse quantization 和 product quantization;coarse quantization 其实就是通过聚类的方法将整个候选库中的分为若干个 clsuter,在 query 到来的时候,选出 topk 个 cluster,并通过 product quantization 来计算出分数进行排序。具体工程实现上采用的是 facebook 开源的 faiss 库,关于上面的步骤细节可参考 PQ 和 IVF 介绍
而在这个过程中 paper 总结的一些经验如下
- 对比 coarse quantization 的算法时,需要固定条数对比召回率 (如 paper 中采用的是 1-Recall@10),其实这种做法也比较常见,因为不同的 coarse quantization 算法聚类的结果差别比较大,因此在固定 cluster 数量和召回时 topk 中 k 的数值,得到的结果差异也会比较大
- 当模型有较大 (non-trivial) 变动时,ann 的一些超参也需要相应进行调整来适应新的模型
- PQ 算法中的 OPQ(Optimized Product Quantization) 效果一般较好,值得进行相应的尝试
- PQ 算法中对 embedding 进行子空间划分时,划分的空间大小是个超参,理论上这个值越大,计算结果越精确,同时资源开销也越大;paper 中的建议值是 4, paper 中表示 “From empirical results, we found that the accuracy improvement is limited after x > d / 4.”
实际 serving 的时候,只会实时计算 query 塔的 embedding,而 document 塔的 embedding 则会离线计算好并构建倒排索引,且在实际的系统中,新的 document 会不断生成,因此还会计算新 document 作为增量索引,而间隔一段时间好需要重新计算全量的倒排索引。
Later-stage Optimization
这一部分主要描述了所有推荐系统现在存在的一个 bias,就是训练数据都是由当前系统产生的并反哺给系统的,因此很可能会造成 “马太效应”,即强者约强,弱者越弱;更广义来说,这也属于一个 E & E 问题.
在 paper 中,这一点体现在新的 ANN 召回的结果可能并不会被精排认可,paper 中描述如下
since the current ranking stages are designed for existing retrieval scenarios, this could result in new results returned from embedding based retrieval to be ranked sub-optimally by the existing rankers
为了克服这个问题,paper 中提出了两种方法
- 将召回的 embedding 作为精排模型的特征,paper 中称这样做的 motivation 是能更快让精排学到新召回的特性;embedding 加入精排作为特征的方式有:embedding 作为 feature 直接加入精排模型、基于 embedding 计算出的值加入精排模型 (如 query embedding 与 document embedding 的 cosine similarity)等,其中效果最好是通过 cosine similarity 计算出 feature 加入精排模型。
- 人为干预加入新召回后训练数据的分布。为了避免新召回的结果不被 ANN 认可,paper 中并不仅仅依赖系统自身产生的数据作为训练数据,而是通过人工的方式对被召回的结果重新打上 label,但是在实际中感觉这个操作成本会比较高~
小结
这篇 paper 主要讲了 FB 在搜索场景下构建一个 ANN 召回系统的基本步骤,包括训练数据的选择、模型的训练、 serving 等,每一部分都给出了一些实战经验,值得参考;而其中比较值得关注的是负样本的选择,paper 将负样本分为 easy negative 与 hard nagative 两大类,并通过实验证明只用 easy nagative 或 hard nagative 训练出来的都不是最优的,而是需要联合两者共同训练。
此外,paper 最后还提到了 embedding ensemble 方法,基本的方法就是 weighted concatentation (parallel,类似 bagging) 和 cascade model (cascade, 类似 boosting),但是笔者觉得召回阶段本来的候选就非常大,对耗时要求严格,如果再加上 ensemble,耗时会更严重,在实际中是否具有可行性?ensemble 做在精排是否更合理?
最后,知乎上也有一篇针对这篇 paper 的解读,也值得看一下 负样本为王:评 Facebook 的向量化召回算法,而关于 embedding 在推荐 / 广告上的各种应用推荐看 推荐系统 embedding 技术实践总结