程序的表示、转换与链接 - week10、11
本文是 程序的表示、转换与链接 中第 10、11 周的内容,主要介绍了从源文件生成可执行文件的步骤 (预处理、编译、汇编、链接),并详细描述了其中的链接这一步骤中的两大过程:符号解析与重定位,并对比了链接输入的可重定位目标文件和输出的可执行目标文件的差别;对了解文件的从编译到执行原理有一定帮助,可配合 《链接、装载与库》 阅读笔记 一起阅读。
通过对源文件的预处理、编译,汇编等转换 可以得到一个个模块对应的机器代码, 也就是目标文件; 但是目标还不能直接执行,还需要将这些目标文件链接起来才能得到一个可执行文件
链接过程用到的目标文件主要有:
- 编译、汇编后得到的目标文件,称为可重定位目标文件
- 链接后生成的目标文件,称为可执行目标文件,
- 共享库文件
下面以 Linux 平台所用的 elf 格式 为例,来讲解这些目标文件的相关内容
程序转换过程
以 c 语言为例,从源码到可执行文件的典型过程如下图所示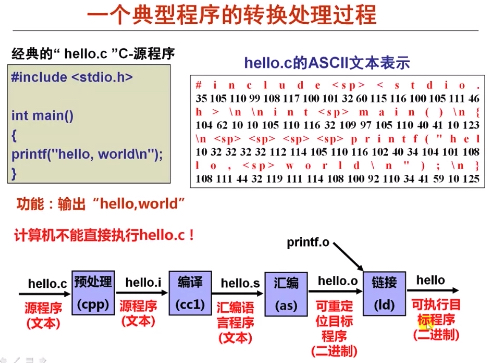
在 Linux 下,通过 gcc 命令能完成上面各个步骤,而实际上, gcc 命令实际上是由具体程序 (如 ccp,cc1, as,ld 等) 包装的命令,用户实际上是通过 gcc 命令来使用具体的预处理程序 ccp,编译程序 cc1 ,汇编程序 sa 和链接程序 ld 等。
以 c 语言为例,各个步骤的 input/output 及其主要做的事情如下所示
预处理
主要处理以 # 开头的代码,具体处理包括宏展开、条件预编译等
input: 源代码文件(文本文件,.c 文件)
output:预处理后的代码文件(文本文件,.i 文件)
预处理主要做的事情有
- 删除
#define并展开所定义的宏 - 处理所有条件预编译指令,如
#if、#ifdef、#endif等 - 插入头文件到
#include处,可用递归方式进行处理 - 删除所有注释
- 保留行号和文件名标识,以便编译时编译器产生调试用的行号信息
- 保留所有
#pragma指定的编译指令 (编译器需要使用)
下面是一个预编译例子, 其实就是把头文件嵌入到源文件中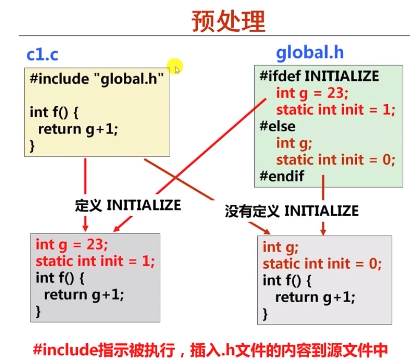
编译
对预处理后的文件进行词法分析、语法分析、语义分析并优化,生成汇编代码文件;这个步骤通过编译程序 (就是编译器)完成的
input: 预处理后的代码文件(文本文件,.i 文件)
output:汇编代码文件(文本文件,.s 文件)
这部分详细内容就不展开了,详细可参考这一系列的文章 LLVM 概述 —— 基础架构
汇编
对编译后的文件通过查表操作(因为机器指令和汇编指令是一一对应的)生成机器指令序列;这个步骤通过汇编程序 (就是汇编器)完成的
input:汇编代码文件(文本文件,.s 文件)
output:目标文件 / 可重定位文件(二进制文件,.o 文件)
链接
input: 多个可重定位文件
output: 可执行文件
后面会详细介绍链接的主要内容
链接的由来与本质
链接的由来
程序往往会被分成多个模块,在进行模块间会进行引用 (reference) 操作,因此在运行时需要确定被引用的符号的地址,而链接可以认为是在生成可执行文件时确定程序中引用的符号的地址
如下是通过两个目标文件生成一个可执行文件的简单例子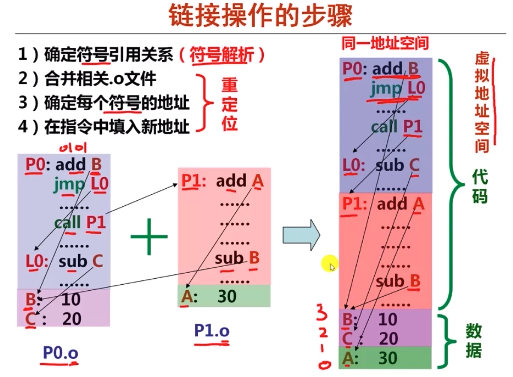
上图中的四个步骤从概念上又可分为符号解析和重定位两大步骤,符号解析是就是在合并之前先确定引用和定义之间的关系。 重定位则是代码和代码 合并、数据和数据合并,合并以后它就在一个地址空间里面, 这个地址空间实际上我们称为虚拟地址空间。
虚拟地址可以认为是从 0 开始连续增长的,在虚拟地址空间中,能得到各个符号的地址。 再把这个地址填到引用的地方,那么就得到了每一条指令真实的 01 序列。每个进程都有自己独立的虚拟地址空间,那最终虚拟地址空间怎么跟物理内存挂钩呢,实际上这个是由操作系统进行内存管理与分配时确定的, 详细可参考 Linux 虚拟内存和物理内存的理解
链接的好处是
1. 模块化编程:程序可分为多个源程序文件多人协助开发、可构建共享函数库等
2. 效率高:重新编译时只需要编译那些被修改过的源代码
链接的本质
链接的本质实际上就是在合并不同目标文件中相同的节,这部分跟之前写的《链接、装载与库》 阅读笔记 (1)- 基本概念与静态链接 内容比较相似,这里不再赘述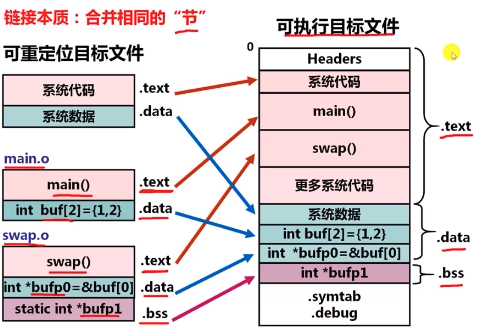
存储在磁盘中的可执行文件中有一个比较重要的组成部分:程序头表,该部分存储着各个节到虚拟地址空间的映射关系, 这部分后面会详细描述
目标文件
目标文件可分为三大类:可重定位目标文件、可执行目标文件 和 共享的目标文件,这三类文件的特点如下
- 可重定位目标文件(
.o文件)- 其代码和数据可和其他重定位文件合并成可执行文件
- 每个 .o 文件由对应的 .c 文件组成
- 每个 .o 文件的代码和数据地址都从 0 开始
- 其代码和数据可和其他重定位文件合并成可执行文件
- 可执行目标文件(Linux 的
.out文件,Windows 下的.exe文件)- 包含的代码和数据可直接被复制到内存并被执行
- 代码和数据的地址为虚拟地址空间中的地址
- 包含的代码和数据可直接被复制到内存并被执行
- 共享的目标文件 (Linux 下的
.so文件,Windows 下的.dll文件)- 用于动态链接
- 在装入和运行时 (前面的都是在链接阶段就用到了目标文件) 被转入到内存并自动被链接
- 用于动态链接
在 Linux 下最常见的目标文件格式就是 ELF 格式,其实就是将代码和数据放到不同的节 (section) 中,如下 ELF 文件的基本格式和一个简单的例子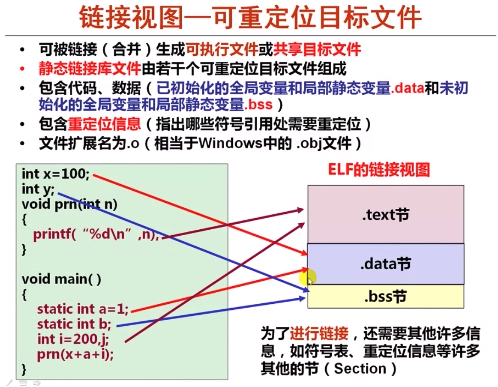
值得注意的是,目标文件与可执行文件的格式非常相似,基本都是 ELF 文件格式,因此可以从两种视角来看 ELF 文件,即链接视角和执行视角,两者的简单对比如下, 后面会详细分析这两种视角下的 ELF 文件的异同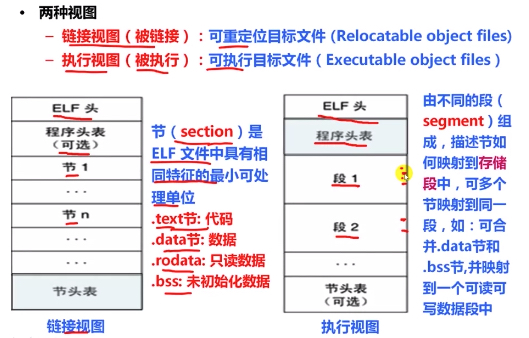
可重定位文件
可重定位文件主要由 ELF 头、各种类型的节和节头表 (Section header table) 组成,各部分的含义如下如所示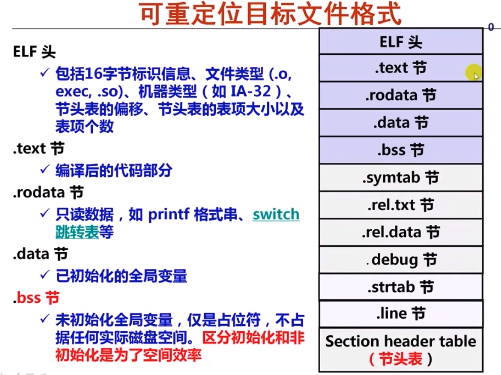
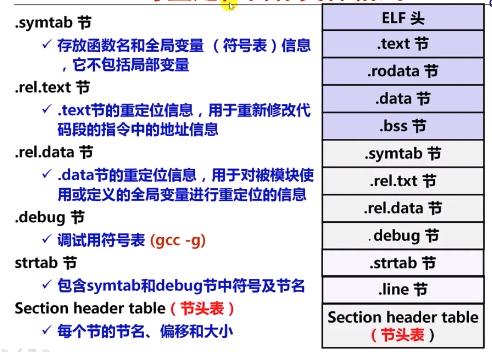
为什么要将未初始化的变量 (.bss节) 与已初始化的变量 (.data节) 分开? 主要是为了节省磁盘空间,因为.data节中存放的是具体的初始值,需要占磁盘空间;而 .bss 节中无需存放初始值,只要说明 .bss 中的每个变量将来在执行时占用几个字节即可(通过节头表来说明应该为 .bss 节预留多大的空间)
除了上面提到的各个节,ELF 头和节头表也是 ELF 文件的两个重要组成部分
ELF 头位于一个 ELF 文件的最开始的地方,里面包含了一些文件结构的说明信息,如 ELF 魔数、版本、小端 / 大端、操作系统平台、目标文件的类型、机器结构类型、程序执行的入口地址、节头表的起始地址和长度等;且根据操作系统主要分两种结构,一种是 32 位系统对应的结构,一种是 64 位系统对应的结构
如下是通过 readelf 读取 ELF 头信息的一个例子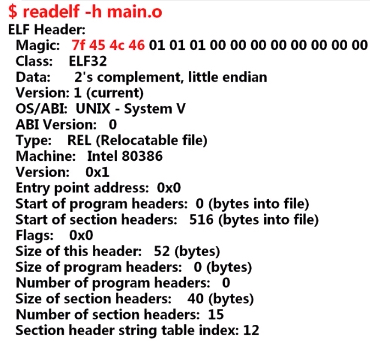
除了 ELF 头,节头表是 ELF 可重定位目标文件中最终要的部分,节头表主要描述了各个节的节名及其在文件中的偏移、大小、访问属性、对齐方式等,如下是一个简单的例子
从上面的 Off 和 Size 可知,有四个节会分配存储空间:.text、.data、.bss、.rodata
可执行目标文件
可执行目标文件与可重定位目标文件很像,两者的不同点在于
(1)在 ELF 头里面,有一个字段 e_entry,表示程序的执行入口,e_entry 在可 重定位文件当中是 0,因为可重定位文件只是用来链接的;而在可执行目标文件当中,这个字段给出这个程序执行的时候第一条指令的地址
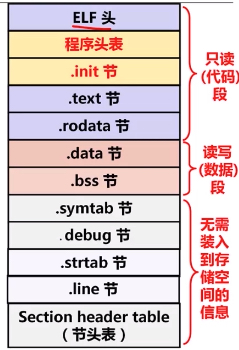
(2)可执行目标文件多了一个程序头表,也称为段头表(segment header table); 类似可重定位目标文件中的节头表,描述的是各个段的一些信息,而可执行目标文件中的一个段 (segment) 是由可重定位目标文件中的多个有相同访问属性的节 (section) 组成的; 如下图是可执行文件中的各个段及组成其的各个节
(3)多了一个 .init 节, 用于定义 _init 函数,该函数用来进行可执行目标文件开始执行是的初始化工作
程序头表 / 段头表主要是用来说明可执行目标文件中各个段的一些属性,如各个段在可执行文件中的位移、大小、在虚拟地址空间中的位置、对齐方式、访问属性等,如下是其定义和一个例子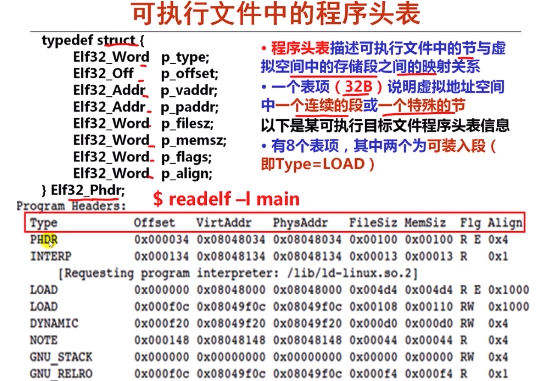
符号解析
前面提到,链接主要分为符号解析和重定位两大步骤,符号解析的目的是把符号的引用和符号的定义关联起来;每个定义符号在代码段和数据段都分配了存储空间,而在引用符号和定义符号建立关联以后,重定位时就可以把引用符号的地址重定位成相关联的定义符号的地址 (虚拟地址空间中的地址)
每个可重定位目标模块的符号存都放在各自的符号表 (在 .symtab 节),这些符号可分为三种
- 全局符号 (Global symbols):由当前模块定义且能被其他模块引用的符号 (不带 static)
- 外部符号 (External symbols):由其他模块定义且被当前模块应用的
- 局部符号 (Local symbols):仅有当前模块定义和引用的本地符号
值得注意的是,这里的局部符号 (Local symbol) 不是指程序当中的局部变量,局部变量是分配在栈中 的临时性的变量,链接器是不关心这种局部变量的, 而局部符号则是分配在静态 数据区,且在整个模块里面都可以使用的。 如下是一个例子:局部变量 temp 分配在栈中,不会在外部过程被调用,因此不是符号定义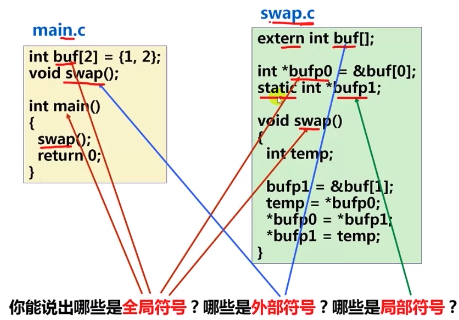
符号强弱性
当一个符号在多个地方有定义的时候,最终解析的时候只能有一个确定的定义;因此有如下规则:
- 强符号不能多次定义
- 若一个符号被定义为一次强符号和多次弱符号,则以强符号为准 (即对弱符号的引用被解析为其强定义符号)
- 若有多个弱符号的定义,则任选其中一个 (gcc -fno-common 链接时会有 warning)
那强符号和弱符号的定义又是什么呢?全局符号又可分为强符号和弱符号,区分两者特点如下
- 所有的函数名和已初始化的全局变量名都是强符号
- 未初始化的全局变量名是弱符号
如下是一些例子
下面的例子中由于 x 被重定义了多次,因此链接时会报错
静态库文件
静态库文件实际上是把若干可重定位文件打包好的一个文件,如 C 自带的标准库 libc.a 就是一个静态库文件,下面是一个例子,描述了如何定义与使用静态库文件
符号解析过程描述如下所示
此外,值得注意的是,上面的链接中如果调换了 mylib.a 和 main.o 的位置会报错,原因是先扫描 mylib.a 时,由于找不到 mylib.a 中定义的函数被调用的地方,因此 mylib.a 中的所有 .o 文件都会被丢弃, 然后扫描 main.o 文件时,myfunc1 无法解析。
因此,使用静态库时链接器对外部引用的符号的解析算法如下
小结
这一周主要讲了从源文件生成可执行文件的步骤,并详细描述了其中的链接这一步骤的过程,包括使用链接的优点,链接如何将可重定位目标文件组合成可执行目标文件,以及这两类文件的差别,两类文件都是 ELF 格式,但是可执行目标文件中多包含了一些程序执行的入口信息和初始化信息(因为可重定位目标文件是无法执行了),且两类文件中都有一个表头用来描述 section / segment 的一些属性,在可重定位目标文件中是节头表,而在可执行目标文件中是段头表。