Long Tail Problem In Item Recommendation
长尾问题在推荐 / 广告系统是一个较为常见的问题 (这里主要针对 item 的长尾),原因可能比较多,笔者理解的主要原因是由于系统存在 feedback loop (即训练数据由模型产生,同时又会被模型用于训练) 的特性,在没有外部干预的情况下,马太效应会天然导致头部效应的现象比较严重,少部分的 item 主导了整个系统。
比如说推荐系统中,很多视频/文章并没有展示机会,在训练集中压根没出现过,高热的视频/文章在不同的用户中排序都比较靠前,进而得到多次被推荐的机会;在广告系统中,部分计划的消耗会特别高,而一些计划压根投不出去;这导致了用户或者广告主体验不佳,而这种现象往往也会被归为生态问题。
既然没有干预时,系统天然的特性导致了头部效应 (或者说二八效应) 比较严重,那强行干预系统的分布能不能改变这个问题?答案是可以的,而且目前绝大部分的方法都是在做这一类事情,常用手段往往有 2 种
(1)策略层面,根据系统和业务特性设计规则,比如说对长尾的 item 有特定的扶持,强行让这些 item 能触达到更多的用户
(2)模型层面,核心思想就是让模型能更好地学习到 long tail item 的 representation,因为这个问题的根本原因就是 long tail item 的样本过少,进而导致模型学习的不好;而具体的手段比较多,这部分会在后面详细介绍。
这篇文章主要介绍的几篇 paper 都是模型层面的,因为策略层面的往往需要根据实际业务需求来拍一些规则,模型层面的一些方法更为通用。
Dual Transfer Learning Framework
这个方法来自 google 的一篇 paper, A Model of Two Tales: Dual Transfer Learning Framework for Improved Long-tail Item Recommendation
paper 名字中提到的 dual transfer learning,分别是 model-level 和 item-level 的 transfer learning,简单来说,前者让样本少的模型 (few-shot model) 的参数尽可能往样本多的模型 (many-shot model) 的参数靠拢 (这里根据样本量分为 2 个模型来建模),后者则是让 long tail item 的 representation 与 head item 的尽可能接近,这里的 representation 其实就是上面提到的 few-shot model 和 many-shot model 吐出来的 embedding,因此 paper 提出的总体框架如下如所示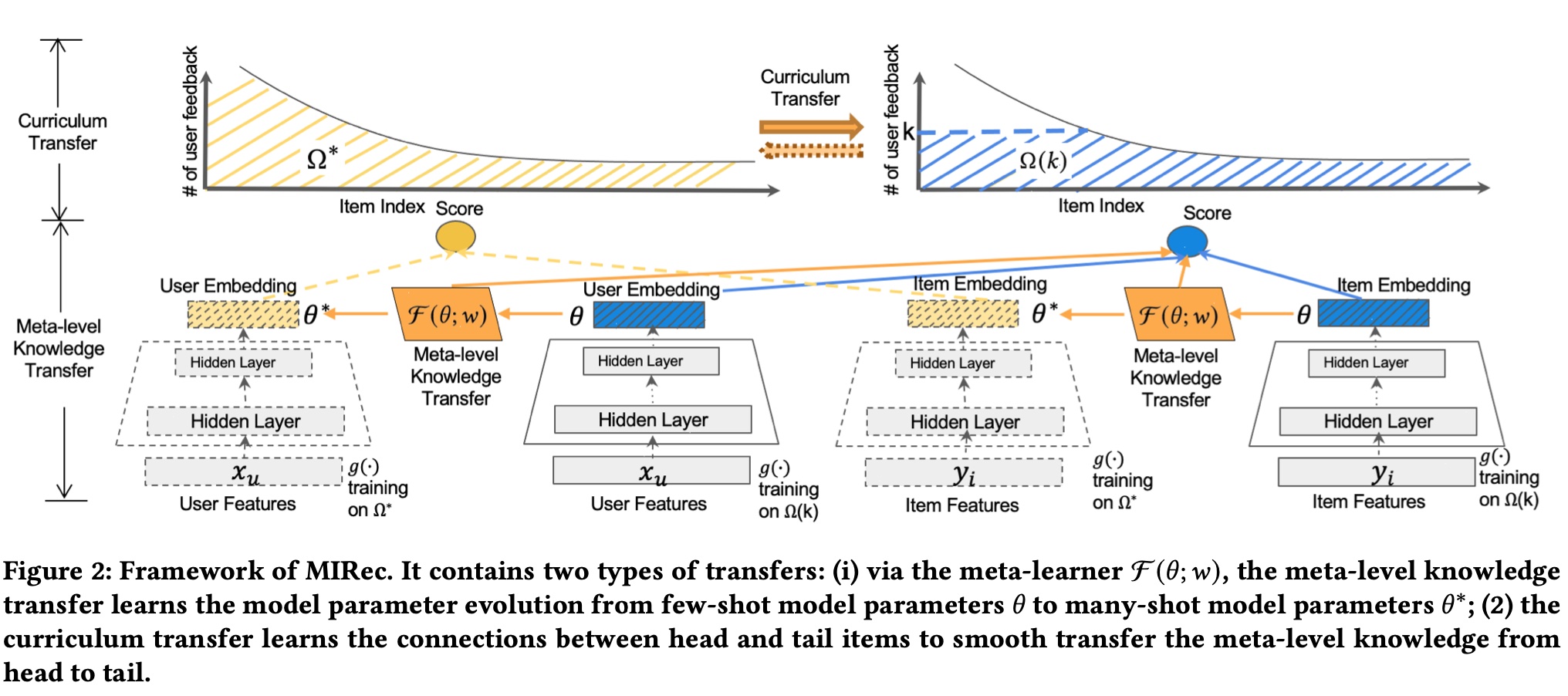
上图中的一些符号含义如下
![]()
从上图中可以看到,根据样本量分为了 many-shot model 和 few-shot model 两个模型来分别建模,核心是 meta-level knowledge transfer 和 curriculum transfer,分别对应前面的 model-level 和 item-level, 下面分别介绍
model-level
其思想比较简单,就是要学习一个 meta learner \(\mathcal{F}\), 其输入和输出都是 few-shot model 的
parameter,监督信号是输出的 parameter 要与 many-shot model 的 parameter 接近,最终作用方式是在 loss 上
base learner 的 loss 是常规的 softmax loss,\(r(u,i)\) 取值为 1 / 0 表示是否有 feedback (如 click 等)
![]()
meta learner \(\mathcal{F}\) 则是采用了 mse 的 loss,并且作为一个 regularization 项加到 few-shot model 原始的 loss 上,则最终 few-shot model 的 loss 如下公式 (5) 所示
![]()
meta learner \(\mathcal{F}\) 具体的结构有很多种,这里采用的是简单的 fully connected layer
item-level
这部分主要通过 curriculum learning 来训练模型,curriculum learning 的基本思想是在训练时组织好样本进模型的顺序,前面的综述的链接里的话是这么说的
Curriculum learning (CL) is a training strategy that trains a machine learning model from easier data to harder data, which imitates the meaningful learning order in human curricula. As an easy-to-use plug-in, the CL strategy has demonstrated its power in improving the generalization capacity and convergence rate of various models in a wide range of scenarios such as computer vision and natural language processing etc.
回到 paper 里,这部分主要做的则是构造好上面提到的两个 training dataset:\(\Omega^{*}\) 和 \(\Omega(k)\)
![]()
\(\Omega(k)\) 的构造方法如下,这部分样本包含 2 部分 item,一部分是 \(I_{h}(k)\) 中那些刚好有 k 个 sample 的 item,另一部分则是 \(I_{t}(k)\) 中的全部 sample
![]()
paper 里称这么做主要有以下 2 个原因,但是笔者觉得核心还是把 long tail item 的样本单独出来,不至于被 head item dominate
- tail items are fully trained in both the many-shot model and few-shot model to ensure the high quality of the learned item representations in both many-shot and few-shot models
(2)In the few-shot model training, the distribution of tail items relatively keeps the same as the original distribution. It can alleviate the bias among tail items that brings by the new distribution
training & serving
因此,总体的 training 流程如下图所示, 可以分为两个阶段,阶段一是通过常规的方法训练 many-shot model,阶段二则是通过 many-shot model 的 parameter 和 meta learner 来训练 few-shot model
![]()
而最终模型 serving 时,则是会对两个 model 输出的 score 做一个常规的加权
![]()
experiment
paper 里的实验用了 2 个公开的数据集,MovieLens1M 和 Bookcrossing,采用的评估指标是 Hit Ratio at top K (HR@K) 和 NDCG at top K (NDCG@K) ,这里的 HR@K 其实就是召回率
实验预期的目标是在总体效果不变差的前提下,提升 long tail item 的表现;因此上面的两个评估指标 HR@K 和 NDCG@K 分别在 all item、head item 和 tail item 上进行了评估
paper 里的实验着重回答了以下四个问题
RQ1: How well does the dual transfer learning framework MIRec perform compared to the state-of-the-art methods?
RQ2: How do different components (meta-learning and curriculum learning) of MIRec perform individually? Could they complement each other?
RQ3: How does our proposed curriculum learning strategy compare with the alternatives?
RQ4: Besides downstream task performance, are we actually learning better representations for tail items? Could we see the differences visually?
第一个问题是跟其他的 sota 方法比较,结论是 paper 提出的最好,具体数据这里就不贴了
第二个问题是做了一个消融实验,结论是单独的 meta-learning 或 curriculum learning 都是正向的,且加起来效果最好
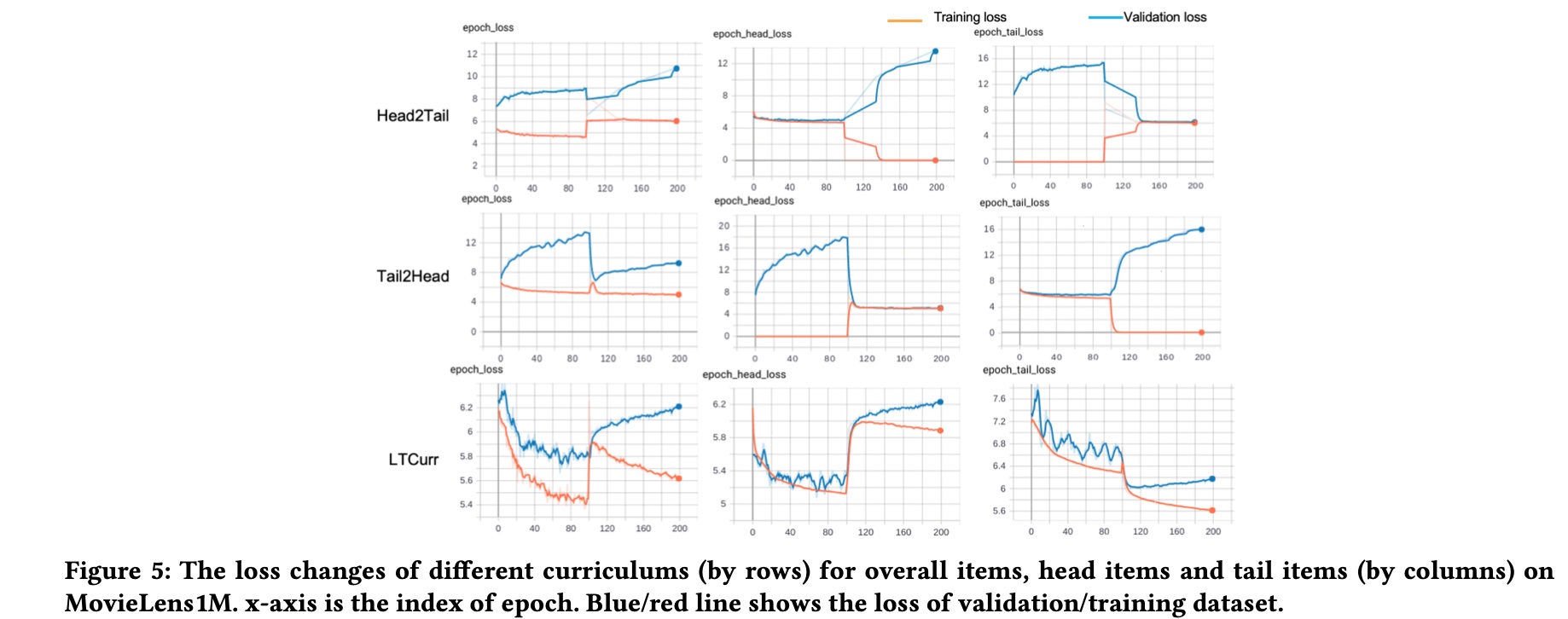
第三个问题是对比不同的 curriculum learning strategy 对 training 和 validation 时的 loss 的值的影响;主要对比了 head2tail 和 tail2head 两个策略,前者先用 head item 训练,再用 tail item 训练,后者则刚好相反,这部分效果如下图所示,也可以归纳出以下 3 点结论
- Compared to the tail item loss in different curriculums (column 3), our proposed curriculum can bring a two-stage decent for both the training and validation loss
- When the model is trained based on only head/tail items, the validation performance for the other part of items decreases. The different changes of head and tail loss indicate the large variations between head and tail items
- It is easily to get validation loss increases if the model is trained purely based on head/tail items, as shown in first column of the first two rows
第四个问题是对学习出来的 embedding 进行可视化,主要想说明通过 paper 的方法学到的方法在可视化上后区分性也比较强,不过只做了两个 case 分析,数据有限,这里就不贴出来了
Self-supervised Learning Framework
这个方法来自 google 的另一篇 paper Self-supervised Learning for Large-scale Item Recommendations, 也是在解决 item 的长尾问题,提升的点也主要在 representation learning 上,如 paper 描述所示
The framework is designed to tackle the label sparsity problem by learning better latent relationship of item features. Specifically, SSL improves item representation learning as well as serving as additional regularization to improve generalization. Furthermore, we propose a novel data augmentation method that utilizes feature correlations within the proposed framework.
SSL Framework
paper 提出的总体的 framework 如下图所示,基本符号的含义都在图片下方的注释里,
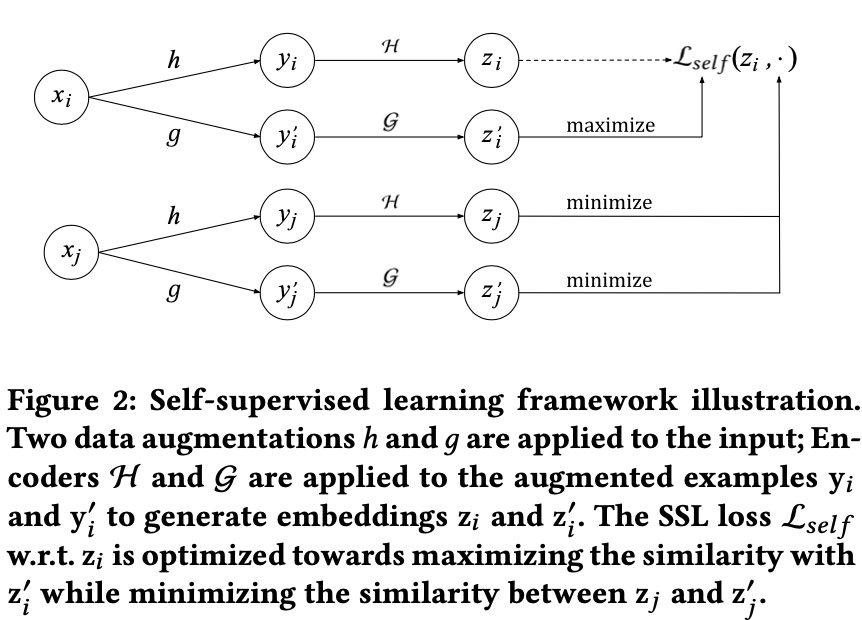
而上图中的 \(x_i\)、\(x_j\) 表示训练时一个 batch 中的两条样本 (推荐中的样本往往有三种含义,query/item/query-item pair,paper 里特指的是 item),这里的核心思想是同一条样本经过不同的变换后的 representation 应该还是相似的,不同的样本则相反
因此,通过 \(h, g, \mathcal{H}, \mathcal{G}\) 得到的 representation 中,\((z_i, z_i^{'})\) 是正例,而 \((z_i, z_j^{'})\) 是负例,因此,对于一个包含 \(N\) 条样本的 batch 中,第 \(i\) 条样本的 self supervised 的 loss 形式如下
\[\begin{align} \mathcal{L}_{self}(x_i) = -\log \frac{\exp(s(z_i, z_i^{'})/\tau)}{\sum_{j=1}^{N}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
上面公式中的 \(\tau\) 为一个超参 (softmax temperature),\(s(z_i, z_j^{'})\) 为两个 embedding 的 cosin 相似性,即 \(s(z_i, z_j^{'})=< z_i, z_j^{'}>/(||z_i|| \cdot ||z_j^{'}||)\)
总体的 batch 内的 self supervised loss 为
\[\begin{align} \mathcal{L}_{self}(\lbrace x_i \rbrace; \mathcal{H}, \mathcal{G}) = - \frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(s(z_i, z_i^{'})/\tau)}{\sum_{j=1}^{N}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
得到 embedding 的两个 emcoder: \(\mathcal{H}\) 和 \(\mathcal{G}\),在 paper 中是共享参数的 (这部分在后面讲模型结构时也会提及)
而如果两种 data augmentation 方法 \(h\) 和 \(g\) 也是相同的话,上面的 \(\mathcal{L}_{self}(\lbrace x_i \rbrace; \mathcal{H}, \mathcal{G})\) 会退化成如下形式,此时损失函数的目标是不同样本的相似性 \(s(z_i, z_j^{'})\) 尽可能小
\[\begin{align} -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(1/\tau)}{ \exp(1/\tau) + \sum_{j \ne i}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
two-stage data augmentation
这里主要讲上面框架提到的两种 data augmentation 方法: \(h\) 和 \(g\) ,paper 称这个方法的关键在于:A good transformation and data augmentation should make minimal amount of assumptions on the data such that it can be generally applicable to a large variety of tasks and models.
paper 里采用的方法则是 mask, 这里借鉴了 bert 的思想,但是这里没有 sequence 的概念,因此这里 mask 掉的是 item feature,实际使用的是一个 two-stage 的方法,即 masking + dropout, 两个方法主要操作如下
Masking. Apply a masking pattern on the set of item features. We use a default embedding in the input layer to represent the features that are masked.
Dropout.For categorical features with multiple values,we drop out each value with a certain probability. It further reduces input information and increase the hardness of SSL task.
至于具体的 mask 方法,paper 里没有采用随机 mask,而是基于特征之间的互信息 (mutual information) 来进行 mask,核心思想是 mask 掉相关性较强的特征,paper 这样做的原因是 the SSL contrastive learning task may exploit the shortcut of highly correlated features between the two augmented examples, making the SSL task too easy
具体的方法的方法是每次每次随机选择一个 feature \(f_{seed}\),通过预先计算好的互信息选择与这个 feature 最相关的 \(k/2\) 个 feature,最终 mask 掉的是这 \(k/2 + 1\) 个 feature
training & serving
前面的 self supervised loss( \(\mathcal{L}_{self}(\lbrace x_i \rbrace)\))只是一个辅助的 loss,
而主任务的 loss 是计算 query-item 的 loss,paper 这里采用的是 batch softmax loss,形式跟 self supervised loss 其实是一样的,只是计算相似性从 item-item 变为了 query-item,具体形式如下
\[\begin{align} \mathcal{L}_{main} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(s(q_i, x_i)/\tau)}{\sum_{j=1}^{N}\exp(s(q_i, x_j)/\tau)} \end{align}\]
则总体的 loss 为
\[\begin{align} \mathcal{L} = \mathcal{L}_{main} + \alpha \mathcal{L}_{self} \end{align}\]
则最终的模型如下所示,注意这里的 3 个 item twoer 的参数是共享的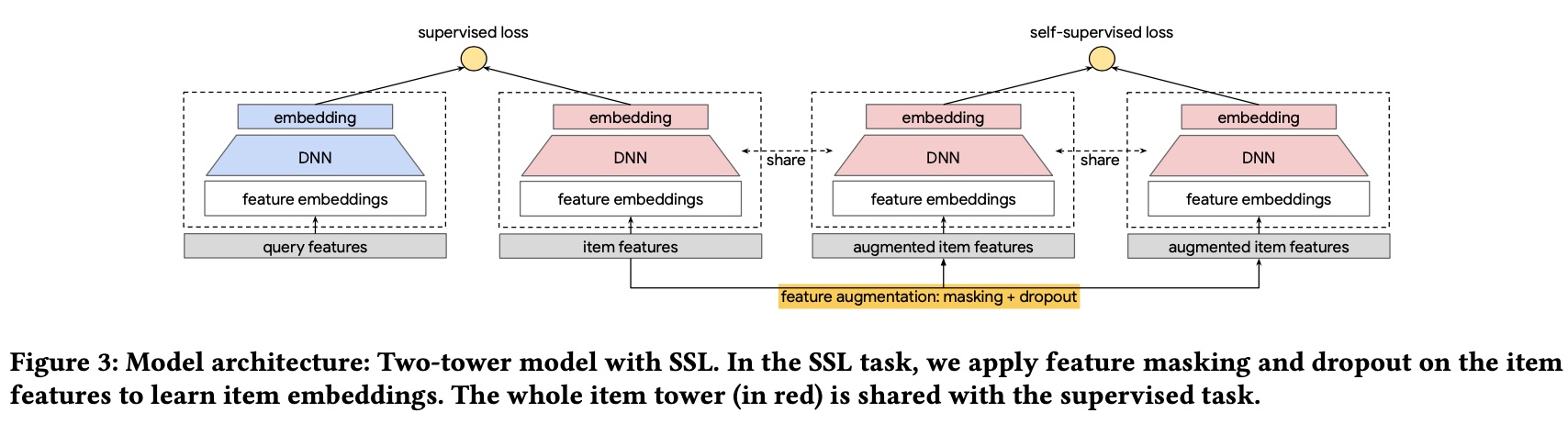
至于 serving,由于只是加了一个 auxiliary loss,所以按正常预估即可
experiment
实验主要回答了如下 4 个问题
RQ1: Does the proposed SSL Framework improve deep models for recommendations?
RQ2:SSL is designed to improve primary supervised task through introduced SSL task on unlabeled examples. What is the impact of the amount of training data on the improvement from SSL?
RQ3: How do the SSL parameters, i.e., loss multiplier \(\alpha\) and dropout rate in data augmentation, affect model quality?
RQ4: How does RFM perform compared to CFM? What is the benefit of leveraging feature correlations in data augmentation?
RQ1,通过与其他 3 个 baseline 进行了比较,采用了 2 个公开数据,评估指标是 MAP@10/50 和 Recall@10/50, 跟前一篇 paper 一样,做了总体 item、head item 和 tail item 各自的评估
RQ2 主要回答数据量对 SSL 的影响,结论是数据量越多,效果越好,感觉这个结论比较符合直觉,不知道 paper 为什么要单独拎出来说
RQ3 主要回答 \(\alpha\) 大小对效果的影响,paper 里对比 spread-out regularization loss 和 paper 提出的 self supervised loss,结论是取相同的值时均是 self supervised loss 效果更好,关于 spread-out regularization loss 可参考这篇 paper,也是一种 constrasive loss,但是没有 data augmentation
RQ4 主要回答随机 mask 的方法 (RFM) 和基于相关性 mask 的方法 (CFM) 哪种效果更好,结论是 CFM 在四项指标上效果均优于 RFM
此外,paper 还补充了在线 ab 实验,结论也是比较显著的
小结
本文主要介绍了从模型层面缓解长尾问题的两篇 paper,两篇 paper 的核心思想都是要更好地学习到长尾 item 的 representation
第一篇提出了一个 dual transfer framework (model-level + item-level), 通过 2 个模型分别建模 head item 和 tail item,在 model-level 令 tail item 的模型参数往 head item 的模型学习,而在 item-level 通过 curriculum learning 组织样本进模型的顺序,serving 阶段需要用两个模型的预估分融合
第二篇 paper 则提出了 self-supervised learning framework, 通过 in-batch 的 data augmentation 方法 (mask + dropout),增加一个 auxiliary loss,其目标是同一个 item 经过变换后的 embedding 应该是相似的,不同 item 的则相反;离线和在线的实验都验证了有效性。
笔者感觉实际业界中,第一种方法的成本要高于第二种,而第一种方法没有做在线的 ab 实验不知道具体在线效果,且第二种方法这种通过 in-batch 样本来构造新的样本对的 self-supervised learning,普适性会更好
除了推荐领域的,CV 领域也有一篇关于长尾问题的综述,Deep Long-Tailed Learning: A Survey,总体的方法论会更全,思路也涵盖了上面说的两篇 paper,但是 cv 跟 recommendation 还是有不少差异的 (比如 recommendation 的 item 数往往比 cv 的要多得多),具体在业务的应用也不确定,这里就不详细展开了。