Highlight Detection In Video
Highlight Detection,直译过来就是高光检测,一般应用在图像或视频里,本文主要关注视频场景,其任务就是从一段长视频里找到某个 “高光” 的片段。这里的 “高光” 是一个非常宽泛的定义,不像 ctr/cvr 有明确的含义,不同场景下对 “高光” 的定义不一样:比如说对于带货直播,高光片段也许是 gmv 最高的时间段;对于非带货直播,高光的片段也许是观看人数或者刷礼物最多的时间段。
Highlight Detection 在实际的应用场景较为广泛:一些视频网站 (如爱奇艺、哔哩哔哩) 里鼠标停留在视频上时会自动播放一些片段,这些片段可认为是高光片段;主流的直播平台基本都提供了直播回放工具,其中往往也会提供高光片段的候选,除了提供给用户侧,广告主 / 商家侧也会提供类似产品,如巨量千川、磁力金牛等平台的产品
Highlight Detection 在学术界也是一个研究方向,但是学界基本研究局限在几个人工标注的数据集上,一般无法直接应用到实际的生产环境中,原因就是上面说的,不同场景下对高光的定义不一样,需要的数据集也不一样。Highlight Detection 相关 paper 不少,本文主要讲 2 篇更贴近业界的 paper,可以重点关注高光的监督信号的定义,损失函数的设计以及数据集的获取
TaoHighlight
这个方法来自 TaoHighlight: Commodity-Aware Multi-Modal Video Highlight Detection in E-Commerce
这是淘宝在 2021 提出的一个方法,总体的模型结构图如下图所示,模型不复杂,左边是抽取多模态特征部分,右边则是基于抽取出来的特征和 score,通过 GCN 做 finetune,损失函数由两部分组成,即 Loss_reg 和 Loss_ag
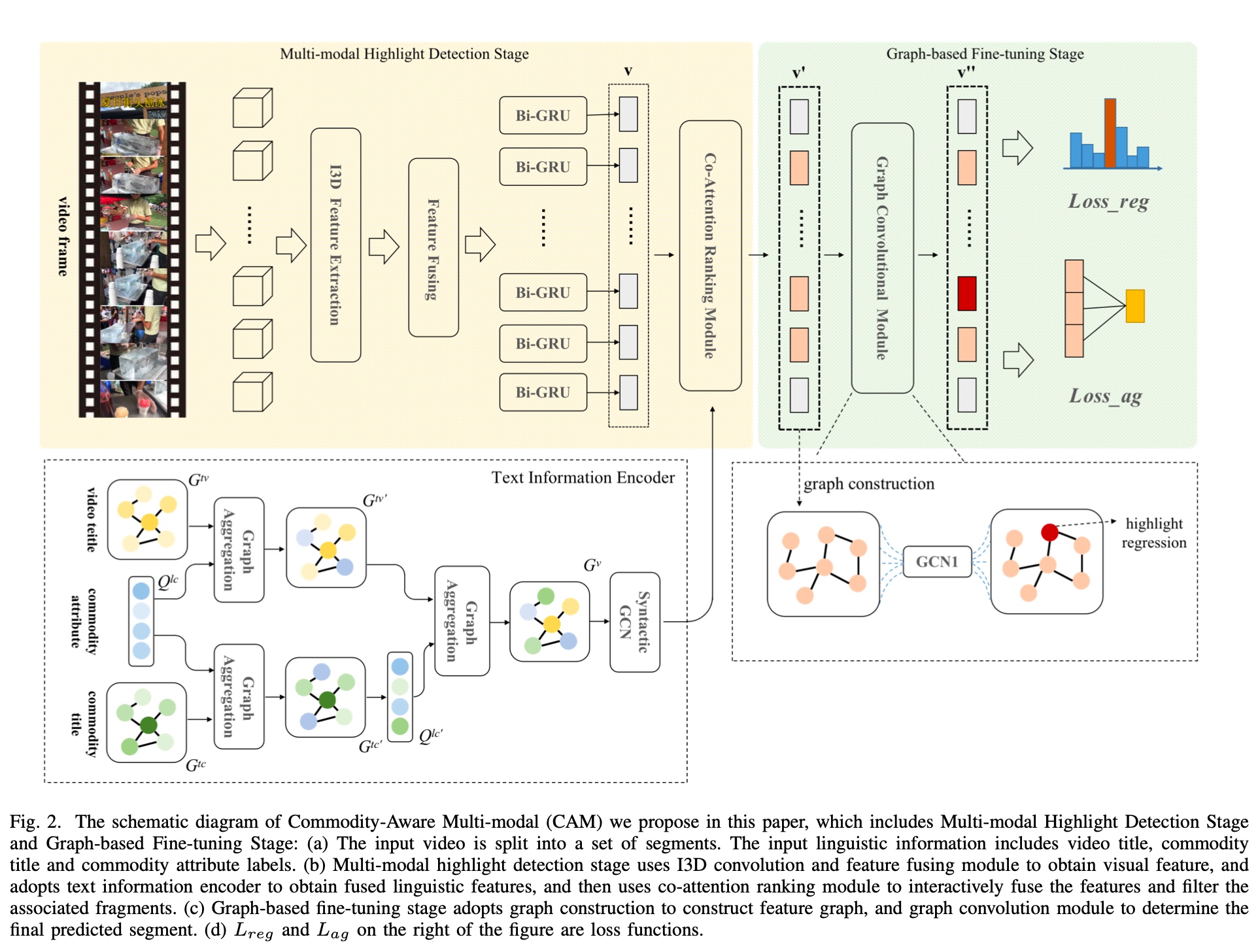
特征工程部分,visual information 通过 I3D+BiGRU 提取,比较常规;text information 提出了一个 QFGA (Query-Focus Graph Aggregation), 一个基于 graph 抽取特征的模块
Co-Attention Module,这个模块主要作用是融合多模态特征(即 visual information 和 text information),基本的原理是参考了 trasformer 的 self-attention 机制,对于下面左边的 block,\(v\) 相当于 query, \(s\) 相当于 key 和 value
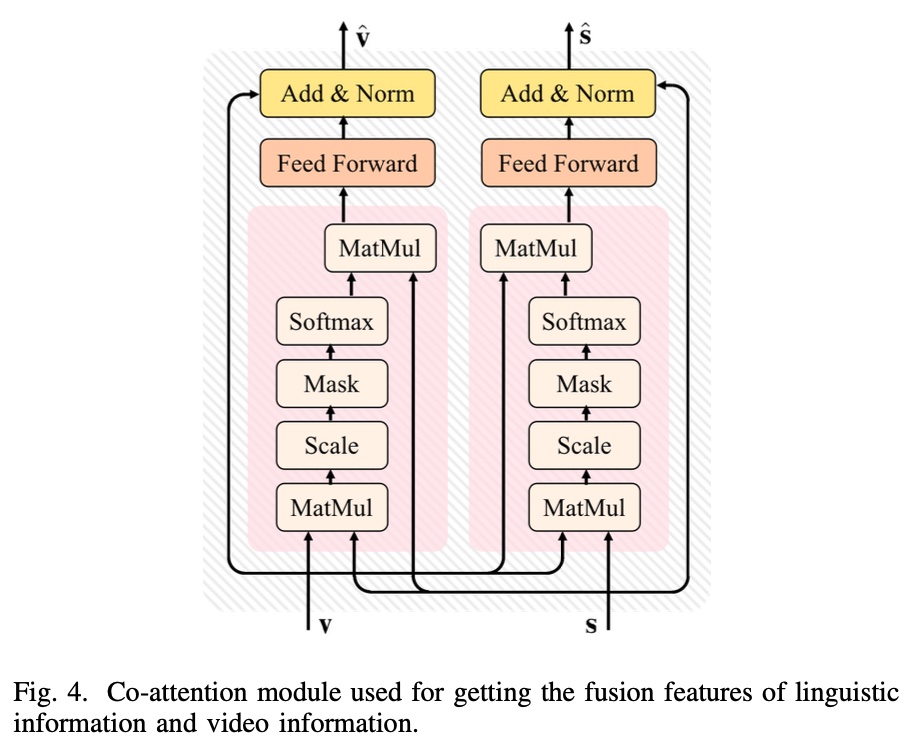
其计算逻辑如下图所示

Graph-based Fine-tuning: 这部分主要是为了减少抽取出来的特征里的 noise;paper 里是这么说的: Due to the presence of visual and text noises in multi-modal video highlight detection, we propose a graph based fine-tuning module to improve the accuracy of our model.,但是也没进一步说明原因
具体的做法就是给每帧打一个分,然后选取按 score 排序 topk 的 frame 构造一个 graph,基于 graph 做 GCN 的计算,关于 GCN 的详细解释可参考这篇文章:Understanding Convolutions on Graphs,
而最终的损失函数由 2 部分组成,\(L_{reg}\) 和 \(L_{ag}\), 两部分的含义如下
\(L_{reg}\) ,计算预估的开始 / 结束时间和真正的开始 / 结束时间的的差异,计算方式如下
\[\begin{align} L_{reg} = \frac{1}{N} \sum_{i=1}^{N}[R(\hat{s_i}, s_i) + R(\hat{e_i}, e_i)] \end{align}\]
各符号含义如下
- \(s_i\), \(e_i\): 预估的高光片段的开始和结束时间点
- \(\hat{s_i}\), \(\hat{e_i}\): 高光开始和结束时间的 ground truth
- \(R\): L1 函数
\(L_{ag}\) 计算方式如下, 主要用来计算两段视频的相关性,\(k\) 表示将每段视频切成 \(k\) 段 clips,主要由三项组成
\[\begin{align} L_{ag} = - \sum_{i=1}^{k}e(v_i, \hat{v}) \end{align}\]
\[\begin{align} e(v_i, v_j) = \theta_{r} \cdot r(v_i, v_j)+\theta_{d} \cdot d(v_i, v_j)+\theta_{s} \cdot \cos(v_i, v_j) \end{align}\]
各符号含义如下
- \(v_i\), \(\hat{v_i}\): 预估的高光片段和 ground truth
- \(r(v_i, v_j) = \frac{I(v_i, v_j)}{U(v_i, v_j)}\), 就是 IoU 指标,表示重合面积占比
- \(d(v_i, v_j) = \frac{ |c_i - c_j|}{U(v_i, v_j)}\), \(c_i\) 和 \(c_j\) 表示两个 video 的中心位置
- \(cos\): 两个片段的 cos 相似性
预估时实际是一个多分类模型 (softmax),会对最后构造的 graph 做一个预估,并选择概率最大的一帧作为起始帧,然后取其后的 128 frame 作为固定的高光片段
实验评估的效果指标就是看各种 IoU 的占比,数据集是 taobao 提供的包含 5 个大分类的数据,整个 dataset 的信息如下

paper 做了消融实验,结果如下图所示
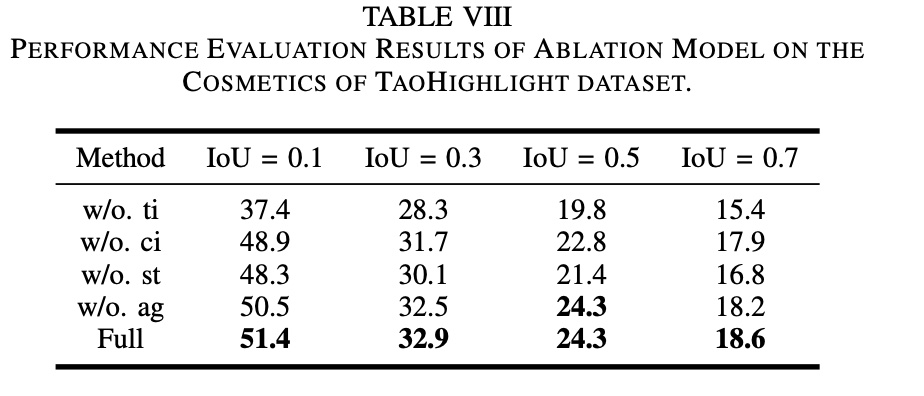
各符号含义如下,可以看到文本特征,Graph-based Fine-tuning 以及损失函数中的 \(L_{ag}\) 项作用还是不小的
- w/o.ti. 去掉文本特征
- w/o.ci. 文本特征只包含 video title(去掉了商品 titile 和商品属性)
- w/o.st. 去掉了 Graph-based Fine-tuning
- w/o.ag. 去掉了损失函数中的 \(L_{ag}\) 项
“unsupervised” solution
上面的 TaoHighlight 方法使用的是人工标注的数据集,其缺陷是比较明显的,即人工标注导致了成本较高,可维护性太差;一是高光的定义因人而异,标注时主观性会比较强,二是成本和标注的难度决定了数据更新频率不会很高,这在业界基本是无法接受的
那很自然就会想到,能否利用一些无须标注的信号来规避掉需要人工打标这个环节呢?这篇 paper 就提供了一个思路 Less is More: Learning Highlight Detection from Video Duration
peper 认为 Less is More, 即越短的视频的信息量就越高,所以切分出来的片段都可以认为是高光片段,反之越长的视频的信息量约低,切出来的都不是高光片段,因此,paper 将训练样本 \(D\) 分为分为三部分,即 \(D= \lbrace D_S, D_L, D_R \rbrace\),\(D_S\) 表示短视频的集合,\(D_L\) 表示长视频的集合,paper 将短于 15s 定义为短视频,长于 45s 的定义为长视频
每个视频都会被切成等成的 segment,记为 \(s\), \(v(s)\) 表示 segment 对应的视频
paper 采用了 pair-wise 的方法来构造样本,即从 \(D_S\) 和 \(D_L\) 切好的 segment 中分别取出一个,来构成一对 pair \((s_i, s_j)\),然后基于下面的 ranking loss 计算两部分的差异,这里的 ranking loss 其实是一类损失函数,常见的 triplet loss、magrin loss、hinge loss 其实都可以算做 ranking loss
损失函数的表达如下
\[\begin{align} L(D) = \sum_{(s_i, s_j) \in \mathcal{P}} \max(0, 1 - f(x_i) + f(x_j)) \end{align}\]
但这种认为短视频切出来的都是高光,长视频切出来都不是高光的方法显然是比较武断的,或者说存在 noise,所以需要计算每对 pair 的置信度,因此引入了一个 binary latent variable \(w_{ij}\),表示每对 pair 的置信度,因此上面的损失函数变成了如下形式
\[\begin{align} &L(D) = \sum_{(s_i, s_j) \in \mathcal{P}} w_{ij} \max(0, 1 - f(x_i) + f(x_j)) \\\ &\begin{array} \\\ s.t.& \sum_{(s_i, s_j) \in \mathcal{P}} w_{ij} = p|\mathcal{P}|, w_{ij} \in [0,1] \\\ &w_{ij} = h(x_i, x_j) \end{array} \end{align}\]
上面的 \(p\) 表示训练样本里有效的 pair 的比例,\(h\) 则是计算 \(w_{ij}\) 这个 variable 的网络,在训练时会跟原来的网络做 joint training,实际实现时,会通过分 batch + softmax 生效
虽然这里通过 \(w_{ij}\) 做到了在统计意义上只有部分样本有效,但是未必就能把 noise 完全干掉,因为缺少人工先验的信息,可能最终训练出来,在真正有效的 pair 上,\(w_{ij}\) 可能会更小
总体的模型和流程如下图所示,\(\mathcal{P_1}\) 到 \(\mathcal{P_t}\) 可认为是 \(t\) 个 batch,每个 batch 有 n 个 pair
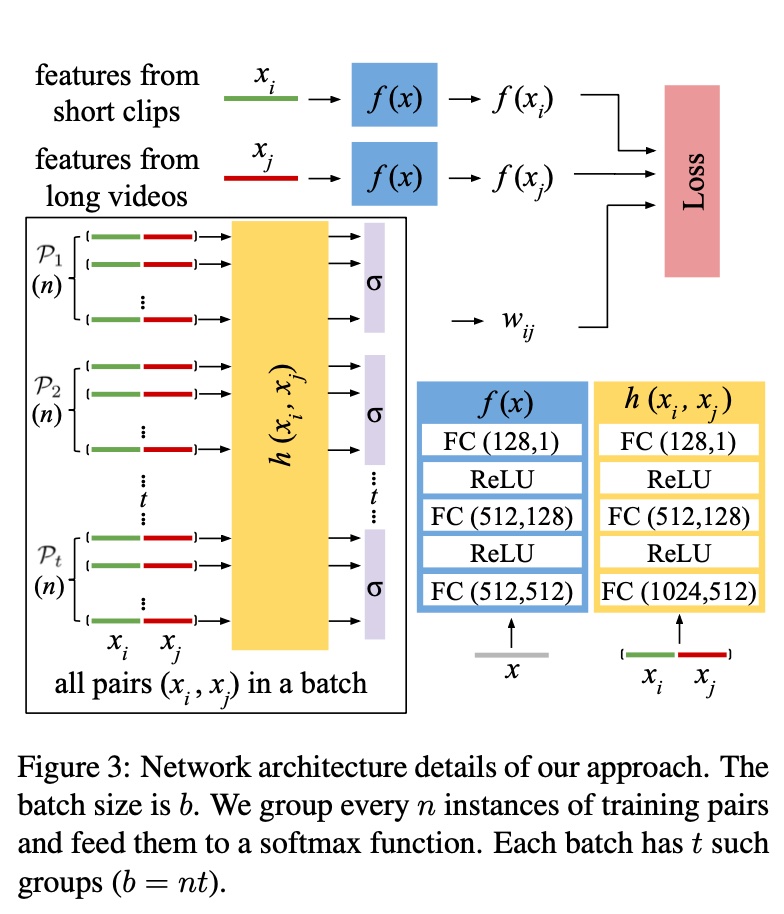
上面也提到,\(w_{ij}\) 实际的生效是通过分 batch + softmax,即上面的损失函数最终会改成如下形式,\(\sigma\) 是个 softmax 函数,生效在 \(\mathcal{P_g}\) 中,相当于 \(p=\frac{1}{n}\)
\[\begin{align} &L(D) = \sum_{g=1}^{m} \sum_{(s_i, s_j) \in \mathcal{P_g}} w_{ij} \max(0, 1 - f(x_i) + f(x_j)) \\\ &\begin{array}\\\ s.t.& \sum_{(s_i, s_j) \in \mathcal{P_g}} w_{ij} = \sum_{(s_i, s_j) \in \mathcal{P_g}} \sigma(h(x_i, x_j)) = 1 \\\ &w_{ij} \in [0,1] \end{array} \end{align}\]
实验采用的指标是 mAP (mean average precision),在 object detection 中比较常见的指标,可以简单理解为多个类别物体检测中,每一个类别都可以根据 recall 和 precision 绘制一条曲线,AP 就是该曲线下的面积,mAP 是多个类别 AP 的平均值
mAP 的定义跟 AUC 有点像,只是这里采用了 PR 曲线,AUC 采用的是 ROC 曲线,两者的区别可参考 ROC 曲线与 PR 曲线
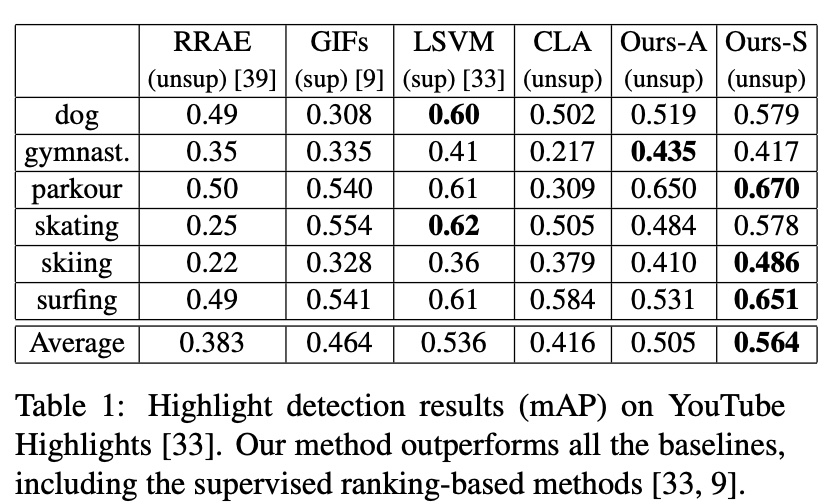
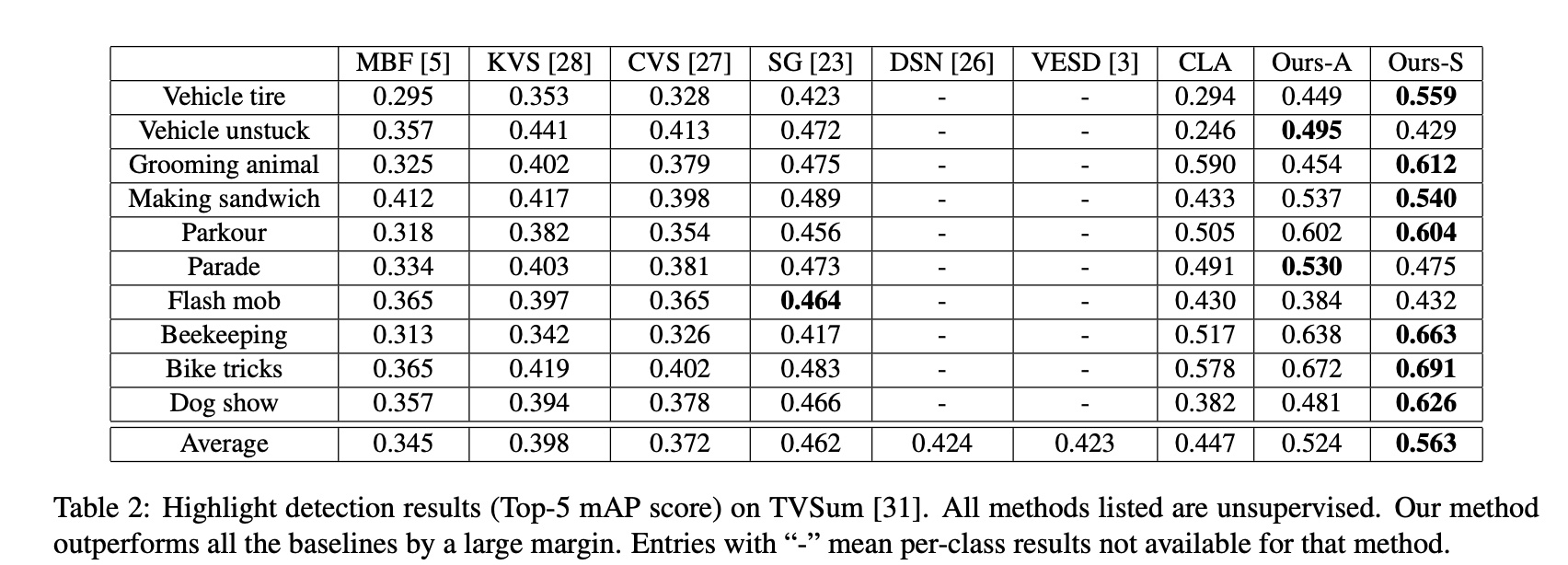
实验主要在两个公开数据集上做,数据集为 YouTube Highlights 和 TVSum,数据集里对视频做了分类 (domain),因此也尝试了总体建模(下图的 Ours-A)和分 domain 建模(下图的 Ours-S),效果还是挺不错的,也超过了一些 supervised 的方法
文章也做了消融实验,主要是 2 部分
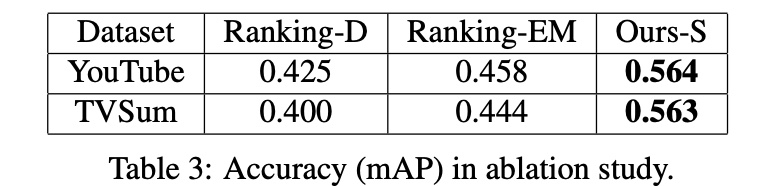
(1)针对上面的 binary latent variable \(w_{ij}\),对比了去掉 \(w_{ij}\) (下图中的 Ranking-D)和通过 EM 来更新 \(w_{ij}\) (下图中的 Ranking-EM)的效果,效果是 joint training > EM > 去掉 \(w_{ij}\)
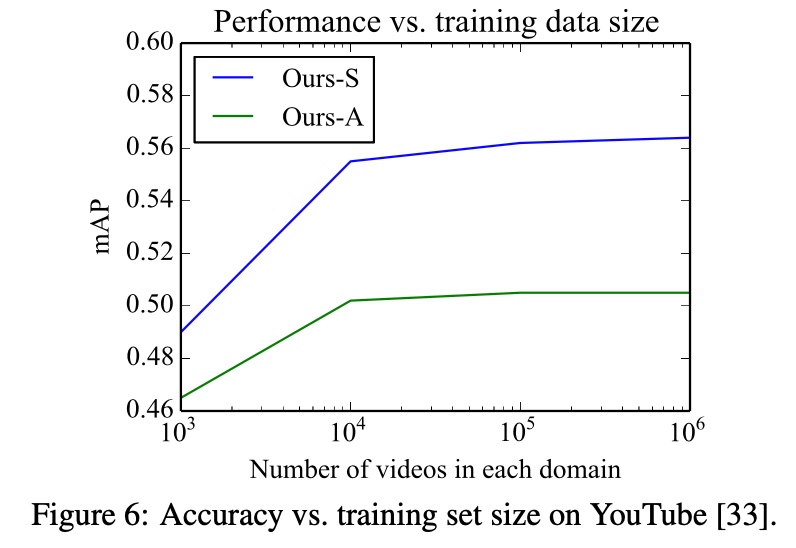
(2)对比了数据集大小的影响,随着数据集增大,准确率逐渐上升并减缓,比较常规的结论
小结
关于 highlight detection 的 paper 不少,这里主要挑选了两篇有针对性的,两篇 paper 的一些核心点如下
第一篇 paper,TaoHighlight: Commodity-Aware Multi-Modal Video Highlight Detection in E-Commerce
- 特征工程: video 和 text 特征的提取,通过 co-attention 机制融合这两部分特征
- 损失函数的设计,\(L_{reg}\) + \(L_{ag}\)
- 减少 noise: graph-based fine-tunning 模块,对一些 topk 的候选做 fine-tuning
第二篇 paper,Less is More: Learning Highlight Detection from Video Duration
- 数据集,根据 video 的长短来判断视频的是否属于高光,无需人工打标
- 损失函数的设计,pair-wise 的 ranking loss
- 减少 noise: 通过一个可训练的 binary latent variable 来标识样本的置信度
第二篇的 paper 的模式感觉是更适合实际的生产环境的,主要是人工标注的可维护性和持续性都不好,而在第二篇基础上,真正落地时可能还有几个问题需要思考
- video duration 是一个比较粗糙的信号,实际的业务中,会有很多的指标 (比如说 ctr、cvr、roi 等),这些指标作为高光的定义也许是一个更好的选择,同时需要权衡选择的信号的深度和数据稀疏的 trade-off
- 除了以上的 ranking loss,LTR (pair-wise, list-wise) 建模也是一个不错的选择,实际业务中需要考虑 pair 或 list 怎么构建
- 如果是直播的场景下,需要实时做高光的检测,无法拿到整个视频,需要考虑一种流式的检测方法