A Survey of Multi-Domain
在实际的业务中,数据往往由多个 domain 组成,以广告为例,往往会存在多个转化目标,在 ctr、cvr 的预估时也要考虑不同转化目标的影响,因为在不同转化目标下,ctr、cvr 的分布 (如均值、方差) 往往是不一致的
解决这个问题最直观的思路是加 domain 相关特征或根据 domain 拆模型,前者属于隐式的方法,需要特征的区分性足够强、能被模型学到,但这个足够强没有一个量化的标准,基本只能看实验效果;后者则存在维护成本过高的问题,比如说有 n 个 domain 就要拆成 n 个模型
本文着重讲如何通过一个模型 serve 多个 domain 的方法,主要是在业界验证有收益且公开发表的工作,基本上可以分为 3 类
- multi-head 结构
- LHUC 机制
- GRL 机制
MMOE
在一个模型中根据多个 domain 拆成多个 head(每个 head 代表一个 domain),通过每个 head 的参数学习特定 domain 的分布,是一种比较直观和常见的做法
这类方法的代表是 MMOE: Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
下图直观展示了拆 head 的集中常见做法
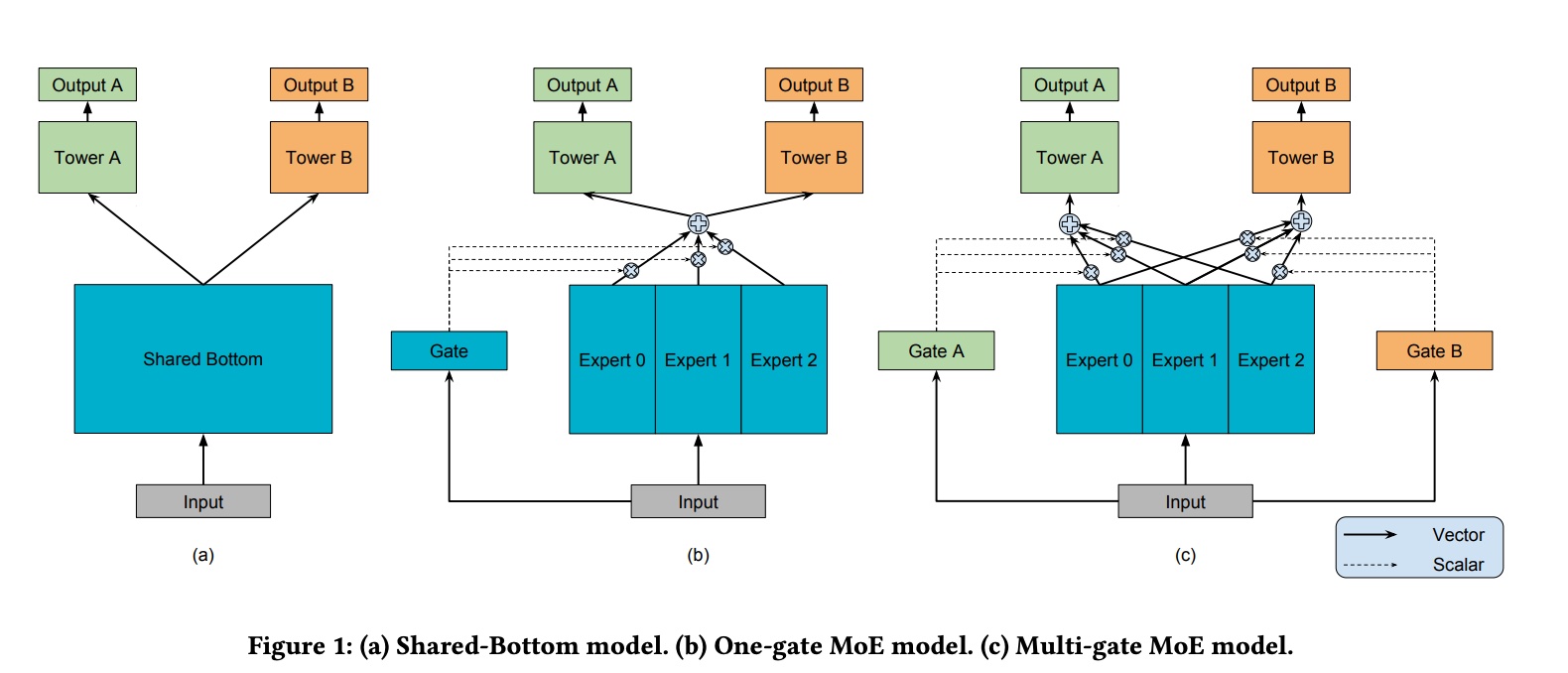
MMOE 中的两个 M,第一个代表 multi-gate,第二个代表 multi-expert;multi-expert 比较好理解,从 ensemble 的角度来看,就是在做 bagging,而 gate 就是在控制每个 expert 的 weight,multi-gate 则是为每个 expert 分配一个 gate,本质上就是做到 domain-wise 的优化
而 gate 的具体实现,也是一个 mlp, 最终通过 softmax 得到每个 expert 的 weight,对于第 \(k\) 个 task,计算过程如下图所示

STAR
这是阿里的一篇 paper,应用场景就是比较典型的 CTR 业务,One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
在模型结构上,也是为每个 domain 分配一部分自己的参数,从而达到在一个模型中 serve 多个 domain 的目的,这一点跟 MMOE 原理上是一样的,文章是这么说的
Essentially, the network of each domain consists of two factorized networks: one centered network shared by all domains and the domain-specific network tailored for each domain
STAR 基本结构如下图 (b) 所示,直观来看,有一个公共的 head,同时为每个 domain 分配了一个 head,最终每个 head 的参数是公共 head 参数与 domain head 参数的 element-wise 结果
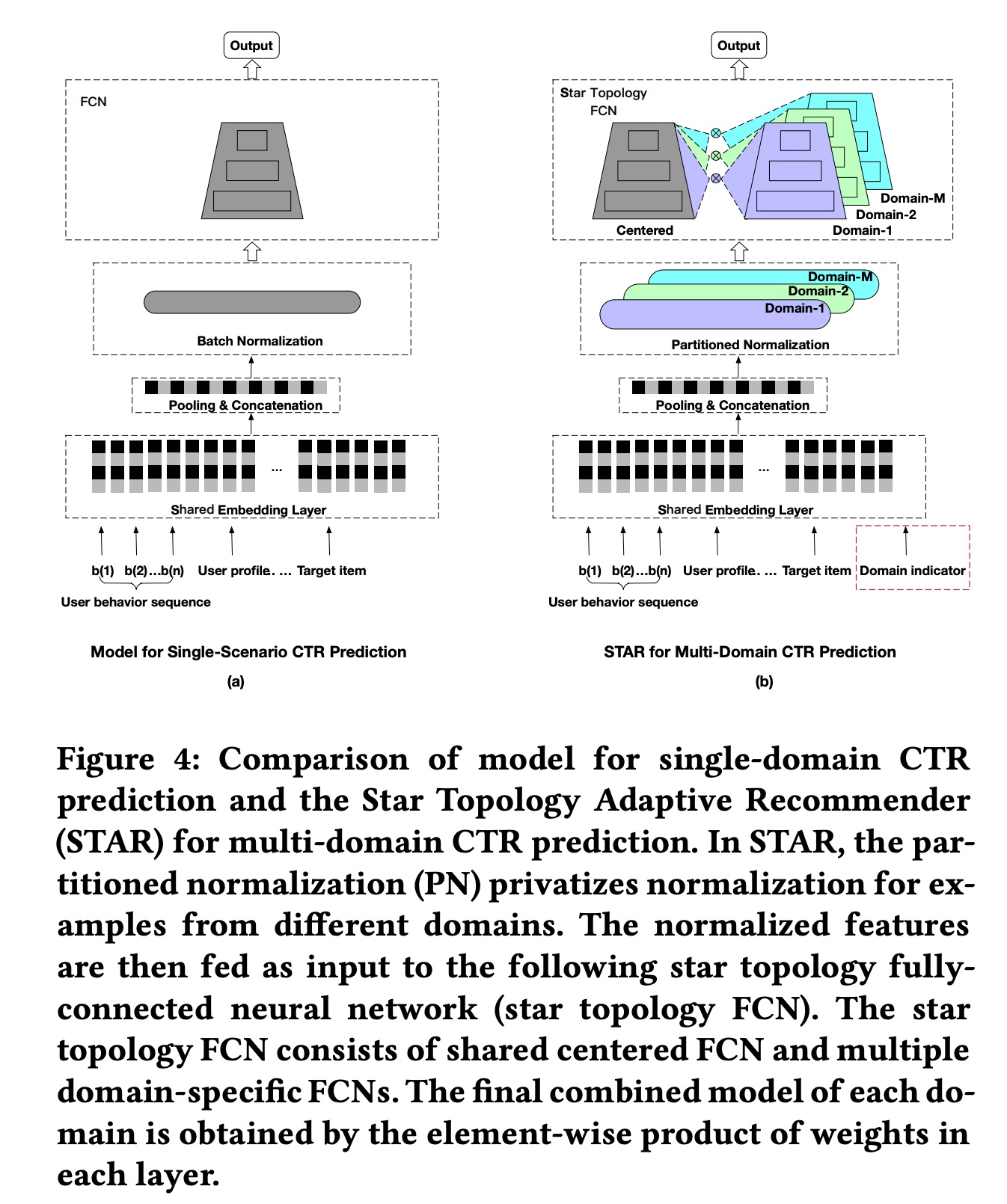
- Partitioned Normalization(PN)
在上面的结构中,有一个 Partitioned Normalization (PN) 的部分,目标是解决统一 batch normalization 在这 multi-domain 中不适用的问题
常规的 batch normalization 会计算 batch 内所有的样本的 mean 和 variance,然后做归一化,如下图所示;这里有个假设就是这批样本是独立同分布 (i.i.d.) 的,但 multi-domain 本身的要解决的问题就是不同 domain 的分布不一样,因此不能直接用原始的 batch normalization;关于 BN 为何有效,可参考这篇文章:Rethinking “Batch” in BatchNorm

而 PN 的做法是为原始 BN 中的参数 \(\gamma\) 和 \(\beta\) 生成额外的 domain-specify 参数,如下图所示

- Auxiliary Network
这是个小网络,输入是 domain indicator (表示这个样本来自哪个 domain),输出是一个预估值,最终输出的预估值会与上面的 STAR 的模型加和做最终预估; 作用等价于为每个 domain 增加了一个 bias 项

实验结果这里不展开,paper 效果显示比一些已有的 multi-domain 任务要好(参数量是否打平没提到);也对 PN 的效果做了消融,结果显示 PN 的效果比直接用 BN 要好
LHUC
前面的两篇文章基本思路都是为不同的 domain 分配多一个 head 的参数,然后通过不同 head 来描述不同 domain 的差异
提出 LHUC 这篇文章则没有显式地分 head ,而是通过在 hidden layer 上乘上一个 domain-aware embedding,来达到这样的效果:Learning Hidden Unit Contributions for Unsupervised Acoustic Model Adaptation
这篇 paper 最早是在 speech 领域提出的一个方法,基本的思路是为每个 speaker 单独调整 nn 中全连接层里部分的参数,从而达到每个 speaker 的个性化预估;总体思路比较直观,也很容易把方法迁移至推荐上
快手的提出的 PEPNet (Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information) 也是借鉴了 LHUC 的这个思想
整个模型结构如下图所示,LHUC 部分是最右边的 PPNet 部分,每个 GateNU 相当于为每个 hidden layer 生成一个 domain-aware 的 embedding,左边的 EPNet 则是相当于为 embedding 不用分生成类似的 embedding
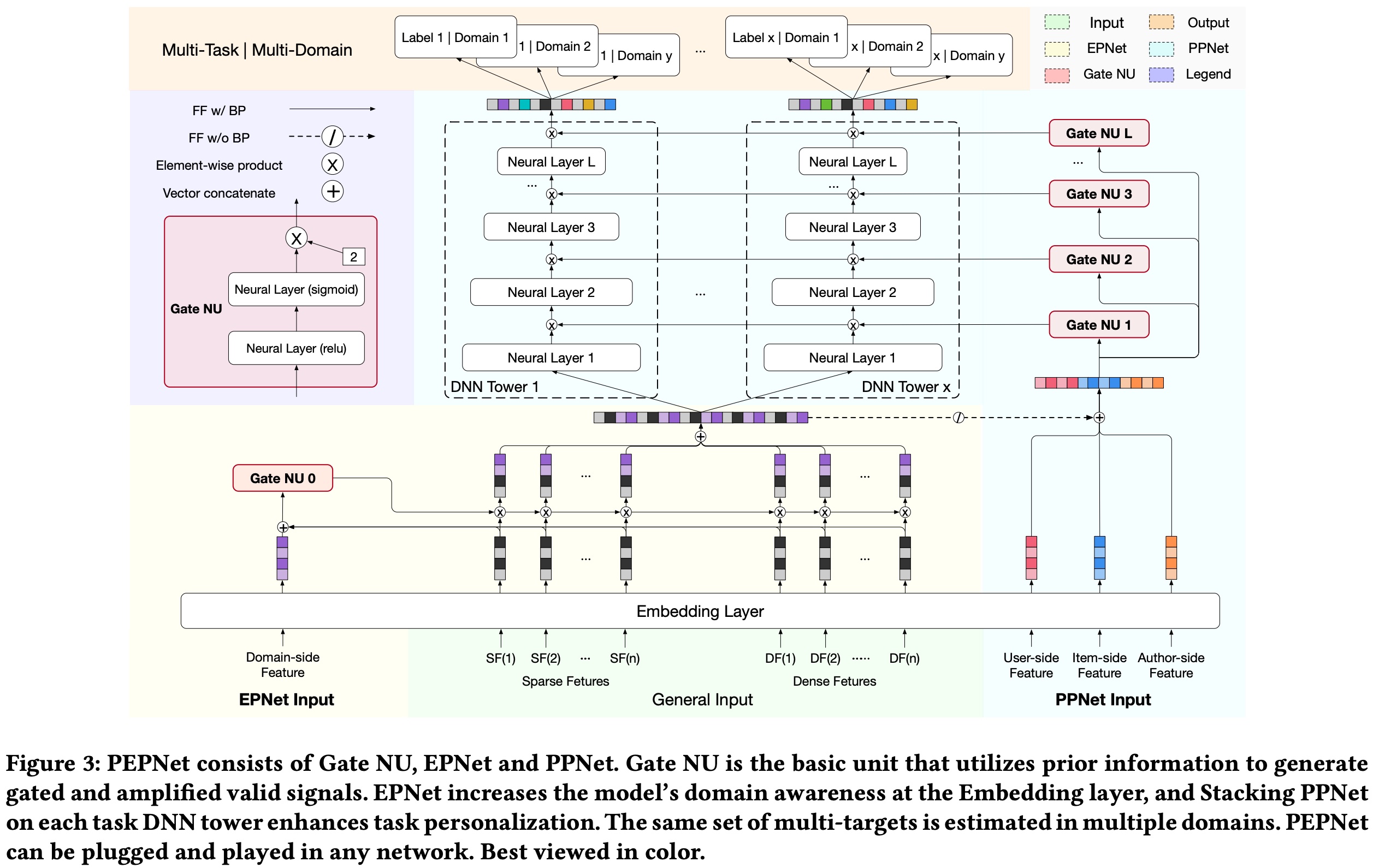
Gate NU 可以理解为一个简单两层的 nn 网络,输入是依靠先验知识挑选的能够区分不同 domain 的特征,输出则是一个 tensor(维度大小与 hidden layer 一样)


除了结构上的改进,这篇 paper 还做了较多的工程上的有优化,这里不详细展开
GRL
这里主要想介绍 GRL(Gradient Reversal Layer)这个机制,这个机制出自论文 Unsupervised Domain Adaptation by Backpropagation
论文主要想解决的问题是 domain adaption,即在 source domain 有较多数据,target domain 较少数据,怎么能够较好地同时解决两个 domain 的问题,paper 里提到的方案是从特征层面去解决这个问题
the approach promotes the emergence of “deep” features that are (i) discriminative for the main learning task on the source domain and (ii) invariant with respect to the shift between the domains.
为了达到这个目标,论文提出的 GRL 机制如下图所示
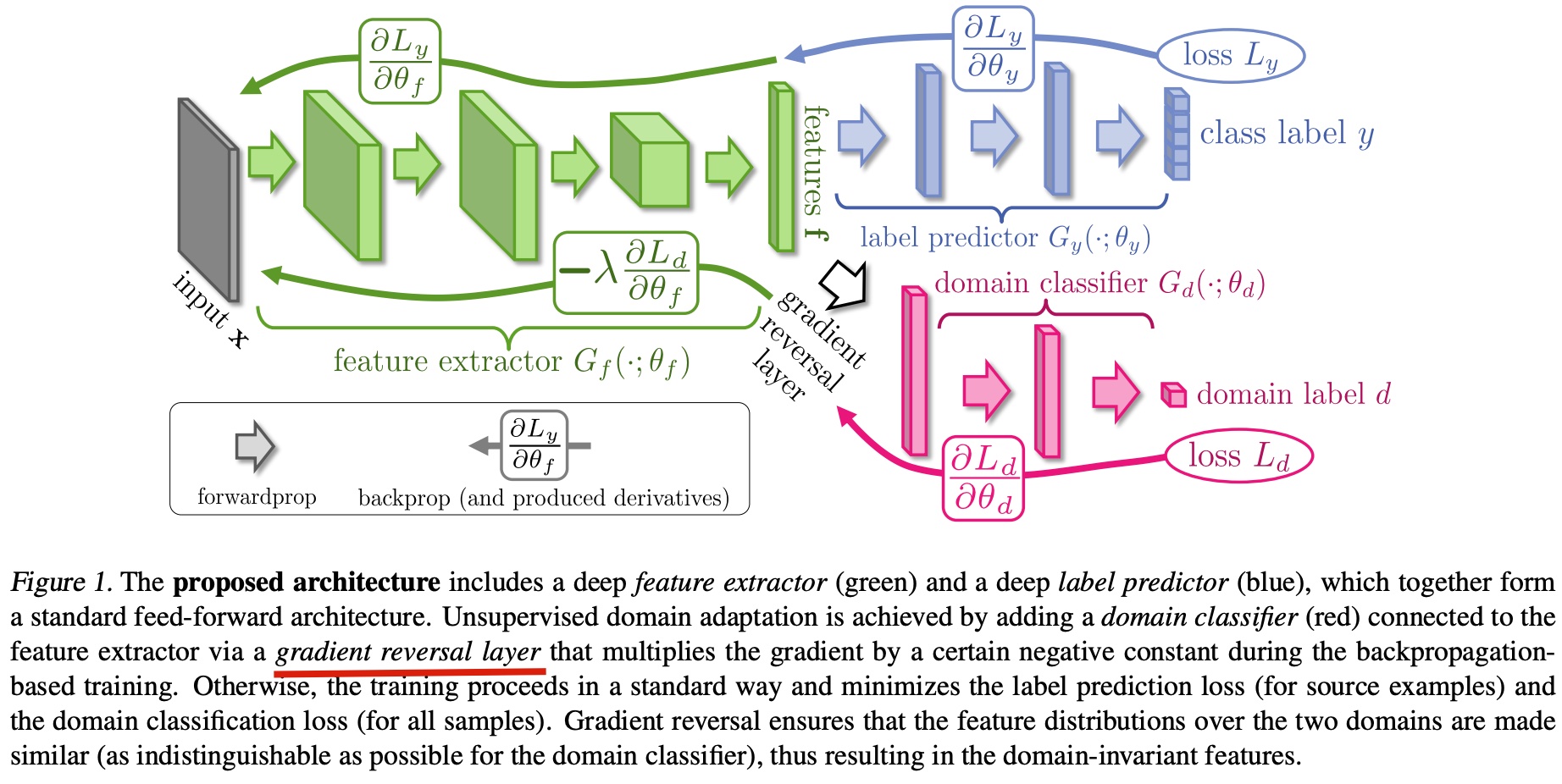
从结构上来看,这也是个 multi-head 的结构,但蓝色的 head 是 source domain 的原始 task,红色的 head(后面简称为 discriminator) 则是一个 domain classifier,即是用来区分样本是属于哪一个 domain 的
两个 task 在做 bp 时,蓝色的 head 正常回传梯度,discriminator 则在梯度回传到 feature extractor 即图中色绿色部分时,乘上一个 negative constant,这就是 GRL 的机制
那为什么要这么做呢?paper 给出的解释是这样的,
we want to make the features \(f\) domain-invariant. That is, we want to make the distributions \(S(f) = \lbrace G_f(x;\theta_f)|x∼S(x) \rbrace\) and \(T(f) = \lbrace G_f(x;\theta_f)|x∼T(x) \rbrace\) to be similar. Under the covariate shift assumption, this would make the label prediction accuracy on the target domain to be the same as on the source domain (Shimodaira, 2000).
即希望 feature extractor 抽取出来的特征是 domain-invariant、对 domain 不敏感的,或者说基于抽取出来的特征,discriminator 不能很好地区分样本来自哪个 domain
而如果不加 GRL,正常的 bp 是会 discriminator 能够区分样本来自哪个 domain 的,加了 GRL 后,则能够达到上面提到的 “discriminator 不能很好地区分样本来自哪个 domain”
那另一个问题来了,即为什么要在 feature extractor 这一层做,而不是在 \(L_d\) 上就加一个负号?
因为如果直接在 \(L_d\) 上加负号,相当于让 discriminator 把它分到错误的那个 domain,但一个好的 feature 应该是让 discriminator 分辨不出它来自哪个 domain,而不是把它分到错误的那个 domain
因此,GRL 机制某种程度上也是一类 feature engineering,用于提取出适用于多个 domain 的 feature
小结
综上,本文主要介绍了三种解决 multi-domain 的思路,分别是 multi-head 结构,LHUC 机制和 GRL 机制;据笔者的了解,目前这几种方案在业界都有落地的案例,值得在相应业务中进行尝试~
multi-head 机制比较直观,为每个 domain 分配一个 head,分别学习不同 domain 的分布,MMOE 和 STAR 这一类模型属于这种;LHUC 机制则是根据先验选择一批有区分度的特征,通过一个小的 nn 学习一个隐变量作用到 hidden-layer 上(其实也能作用到 embedding 上,PEPNet 中没有介绍的 EPNet 就是这部分,原理基本一致);GRL 则是通过训练方式使得模型抽取出来的 feature 是 domain-invariant 的,训练的思想跟 GAN 的对抗训练比较类似