大模型技术报告解读
今年的春节,deepseek 把大模型的讨论热度推向了高潮,即使是在十八线小城的年味里,也藏着些意料之外的科技褶皱。表妹用方言对着手机喊 “给俺写段拜年词”,小侄子在忙着跟豆包里的声音温柔、善解人意的 “校花” 聊天,连巷口的春联摊主都学会了用生成式设计定制烫金纹样 —— 这些烟火气里的数字涟漪,像一场无声的启蒙运动,将 “大模型” 三个字编织进了这座十八线小城的毛细血管
两年前的 AI 还像一座青铜巨像,吞吐数据时浑身震颤着算力的轰鸣,只能在北上广深的数据中心里吞吐星辰;而今的大模型已化作游走的溪流,沿着 5G 基站浸润到县城修车铺的扫码系统、揉进快手主播的方言脚本,甚至蛰伏在老人机的语音助手里咳嗽一声提醒吃药。从 “暴力美学” 的千亿参数军备竞赛,到 MoE 架构轻巧切开算力蛋糕的刀锋,从耗资数千万美元的实验室贵族,到 DeepSeek-R1 用 600 万美元训练成本撕开的平民入场券 —— 这场进化不仅是技术的跃迁,更是科技叙事从 “神坛独白” 转向 “人间对话” 的隐喻:当大模型学会在显卡残骸上跳成本最优化的芭蕾,技术的毛细血管终于触到了烟火人间的心跳
上面这段话是 deepseek 生成的,不用多复杂的 prompt,也不用反复调试,deepseek 就那么 “毫不费力” 地生成了一段诗意与写实的文字;而更恐怖的是,这还不是 deepseek-R1 的卖点:低成本但足以媲美 openAI-o1 的推理能力
这段时间试用下来,相较于两年前,大模型的确有了很大的使用体验的改进,不再是一个生硬的文字排列组合机器;除了众所周知的数据 + 算力的 “力大砖飞” 的技巧,技术上有了什么样的进步和革新?最近听的这期播客《89. 逐句讲解 DeepSeek-R1、Kimi K1.5、OpenAI o1 技术报告 ——“最优美的算法最干净”》,就介绍了三个比较有代表性的大模型报告,本文是学习后的文字版,祝开卷有益~
OpenAI-o1
报告是 24 年 9 月 12 日发布的,Learning to reason with LLMs;主要是详细介绍了在各个 benchmarks 上,o1 效果非常好(比 GPT-4o 要好很多)
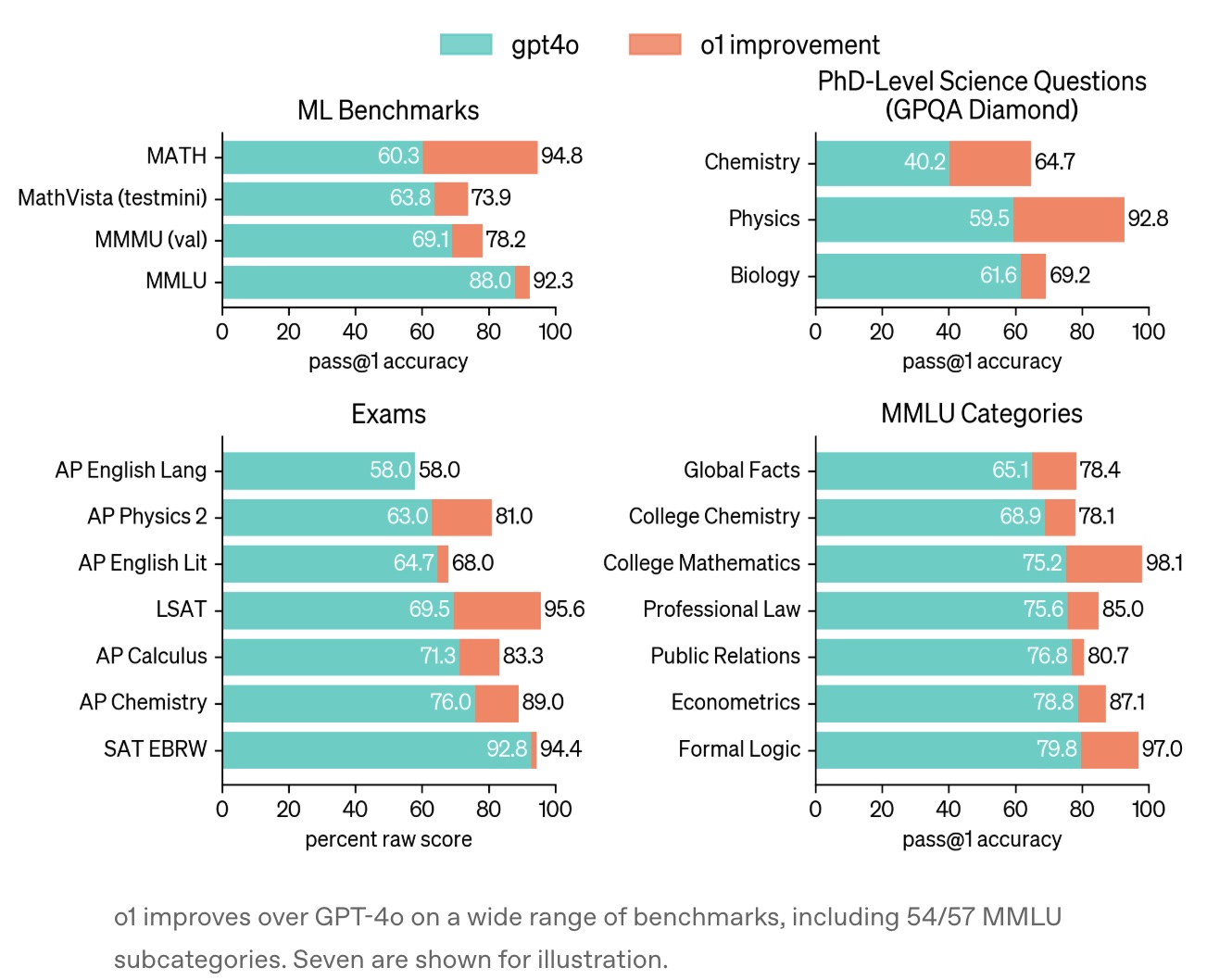
其中,思维链(Chain of Thought)应该是推理模型相较于前 2 年前改进最大的地方之一了;简单来说就是在生成答案前会进行长时间的内部思考,通过多步骤推理、错误修正和策略调整优化答案质量,这种机制类似于人类 “系统 2” 的慢思考模式,显著提高了逻辑严谨性
报告称 “This process dramatically improves the model’s ability to reason”
It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working.
思维链的底层技术就是强化学习了,报告显示这种思维链的能力随着训练时算力和推理时思考时间的增加而持续提升(如下图所示),呈现出类似 AlphaGo 的 “推理扩展定律”(Inference Scaling Law),也有点类似 LLM 在 pretrain 阶段的随着数据量增加而效果变好的 scaling law
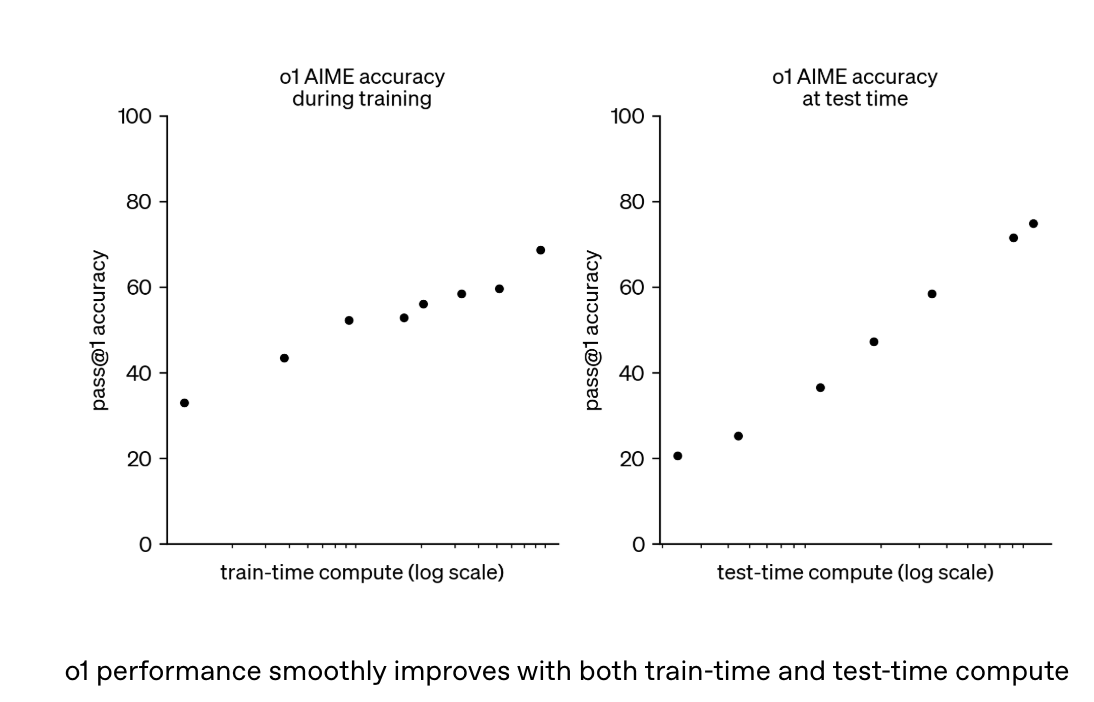
报告做了很多性能表现与基准测试,显示思维链的优势,但 o1 的思考过程对外不可见,仅展示摘要,OpenAI 认为这有助于监控模型的安全性(如防止用户操控)
至于具体实现算法细节,openAI 报告里没怎么公开;外界的当时不少猜测是基于过程奖励模型(PRM),对推理过程中的每一步进行细粒度监督,而非仅评估最终结果(ORM),PRM 这类方法最早在 openAI 的论文 Let's Verify Step by Step有所提及,简单来说 ORM 仅对最终结果提供反馈,PRM 则对每个推理步骤提供反馈。报告显示在训练模型解决 MATH 数据集中的问题时,显著优于结果监督
但在下面要重点介绍的 DeepSeek 的报告中,显示了 PRM 在实际中的落地的难点,是一个不太成功的尝试
openAI 的报告很短,没有太多的有效信息(毕竟已经是 closeAI 了。。)
DeepSeek
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning中,介绍了 DeepSeek-R1-Zero 与 DeepSeek-R1 两个模型
DeepSeek-R1-Zero 是直接在基础模型上应用大规模 RL 训练,而不需要 SFT (Supervised Fine-Tuning),这个此前在 LLM、甚至可追溯到 16 年刚刚兴起的深度学习领域中,被认为是 common sense 的技巧:在通用预训练模型的基础上,使用特定任务的有标签数据对模型参数进行微调,从而优化模型在该任务上的表现
而这也是公开的研究报告中,第一次展示了 LLM 的推理能力通过纯 RL 也能够取得非常不错的效果,这里更重要的意义,也许是为各个团队在攻克 o1 给世界的谜题,给出了一个更清晰的解题思路;正如 paper 里所说的 “it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area“
在讨论报告里提到的强化学习算法之前,先看下此前被广为流传的 RLHF (Reinforcement Learning from Human Feedback) 算法的流程,再深入了解 DeepSeek 在此基础上的相关改进
RLHF
RLHF 分为 3 个阶段:SFT,RM 和 RL,如下图所示(图片来自什么是 RLHF?)
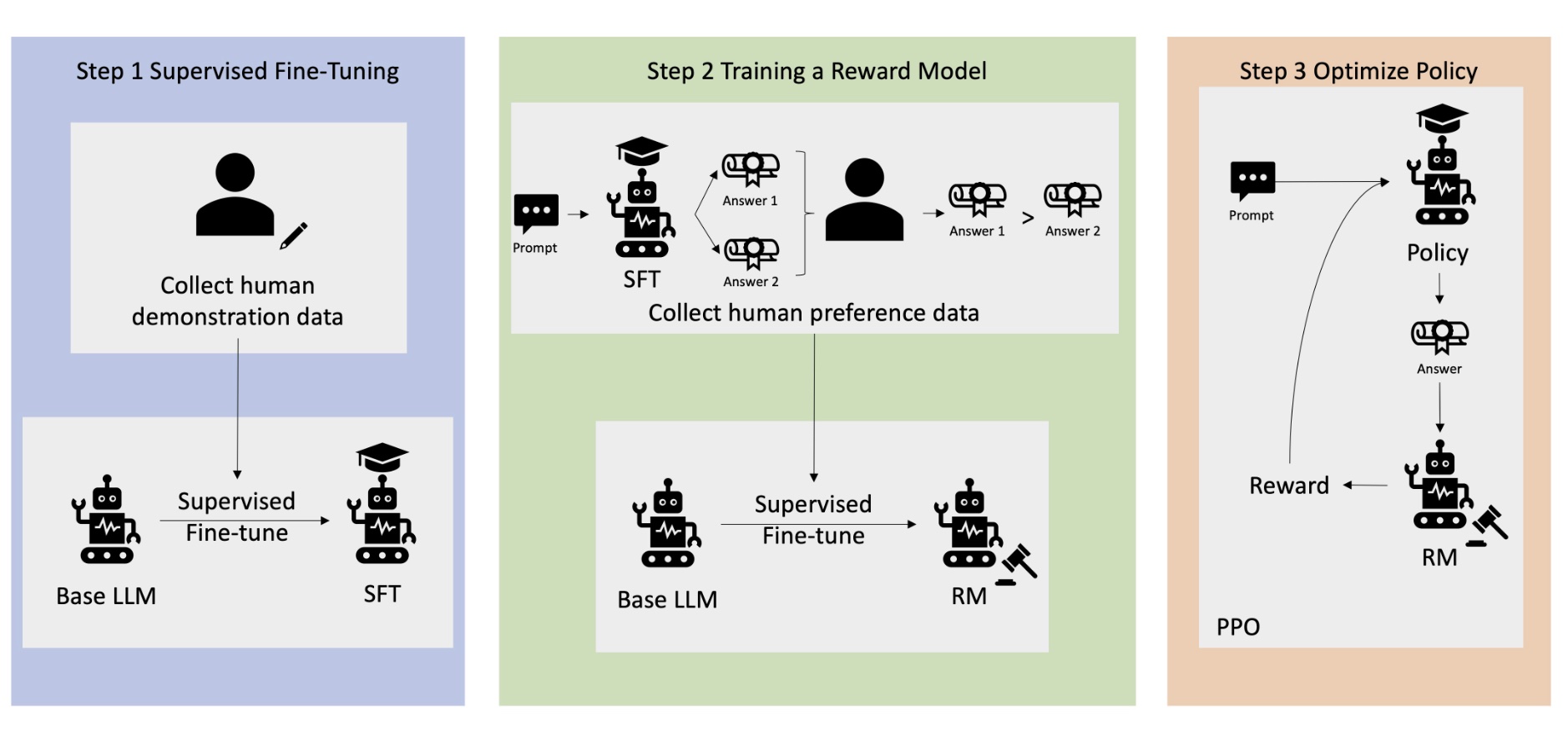
(1)监督微调(SFT) 阶段
就是上面提到的 SFT 过程,基于标注数据调整预训练模型,使其初步适应特定任务(如对话、指令遵循)
具体的做法就是使用高质量的人工标注数据(如人工编写的问答范例)对预训练模型进行微调;训练方式与预训练类似,采用自回归的下一词预测目标(如交叉熵损失)
(2)奖励模型(RM)阶段
这个阶段是构建一个能模拟人类偏好的打分模型,量化生成内容的质量
具体的做法是通过 SFT 模型生成同一指令的多个回答,由人工对回答进行排序或打分(如偏好排序);这个流程往往也是提升模型的安全性(避免有害内容)和价值观对齐(符合伦理偏好)所依赖的环节,即需要引入人工的的纠偏和勘误
然后在原始的基座模型技术上,修改输出和损失函数(eg,对比损失, pairwise ranking loss),训练一个回归模型(RM),输入指令和回答,输出标量的奖励值
(3)强化学习(RL)阶段
最后的阶段就是利用 RM 的奖励信号优化 SFT 模型,使其生成更高奖励的响应,通过强化学习算法(如 DPO、GRPO、PPO)调整模型参数,最大化预期奖励值
以 PPO (Proximal Policy Optimization) 算法为例,RL 阶段的主要流程就是下图的 Step3
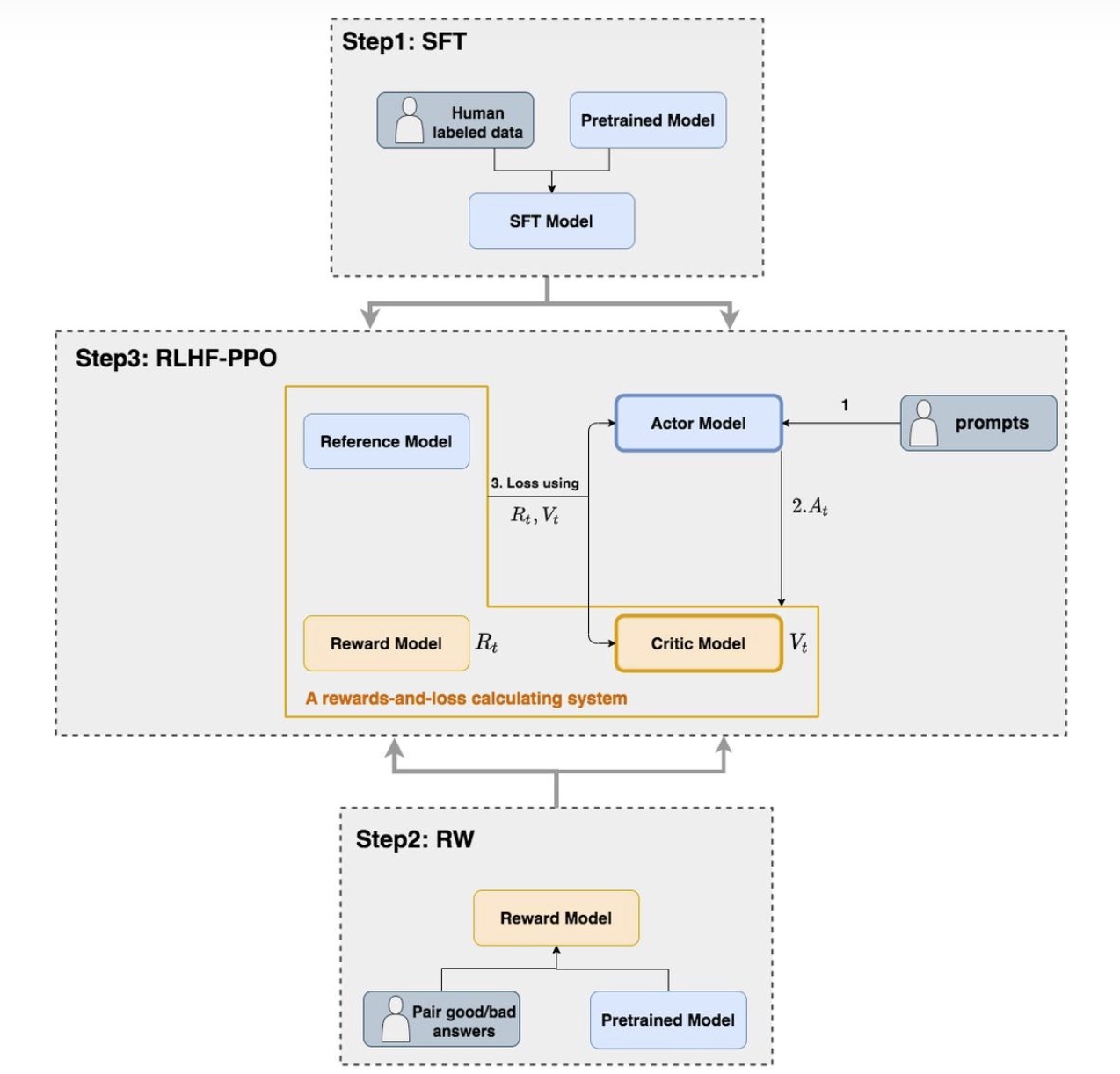
下面着重讲一下原始的 PPO (Proximal Policy Optimization) 算法,PPO 属于 policy-based 算法,这里也简单介绍一下强化学习的两种大的技术范式:policy-based 和 value-based
value-based 方法侧重于学习一个精确的价值函数,用来评估在特定状态 s 下执行某个动作 a 能够带来的预期回报,而在执行 action 时,会从动作里选择出价值最大的动作。常见的方法如 Q-learning 或 DQN。Q-learning 中的 Q-table 或 DQN 中的 Q-network,都是在记录或拟合这个价值函数。前者可以理解为是一张直观的打分表,后者则通过 NN 网络来拟合这张打分表。这类方法一般都是只适用于 action 数量有限(离散)的场景,像 Q-table 往往还会限制 state 数量有限,因为表的大小存储会有限制
policy-based 方法则侧重学习一个策略函数,根据预估的动作概率分布,直接输出最终选择的 action,policy-based 的方法能同时支持离散的动作空间和连续的动作空间
对于离散动作空间,这个场景比较好理解,通过一个 softmax 函数对最终的 n 个动作归一化成概率和为 1 的概率分布,然后选择预估概率最大的动作即可(这其实也是 DQN 的做法)
对于连续的动作空间,模型输出的是概率分布的参数,最常见的一个思路是假设动作服从高斯分布,则模型会输出均值 \(\mu\) 和 标准差 \(\sigma\) 这两个参数,而智能体从 \(N(\mu, \sigma^2)\) 这个分布中随机抽取一个数值作为实际执行的动作,模型学习的目标是调整 \(\mu\)(让分布中心靠近好的动作)和 \(\sigma\)(调整探索的确定性),这种场景下一般使用 NLL (Negative Log-Likelihood) 损失函数,其本质也是 maximum-likelihood estimation 的思想,只是相较于常见的二分类的 MLE 没有绝对的 ground truth,而是基于环境反馈的具体 reward 来决定最终的 gradient 的 weight
policy-based 方法中往往会涉及到策略梯度(policy gradient)的概念,其实跟机器学习中 bp 的 gradient 基本是相同的概念,可以理解为是 weighted gradient,比如说以离散空间为例,其实就是个多分类的任务,只是在传统的多分类任务中 bp 中回传 gradient 时,多乘一个 reward,其物理含义是对增加 reward 大的动作的出现概率,减少 reward 小的动作的出现概率
回到 PPO 算法,PPO 算法一种基于 Actor-Critic 架构实现的算法。PPO 中共有 4 个模型:Actor Model、Critic Model、Reward Model 和 Reference Model
其中,Reward Model 和 Reference Model 是在 LLM 场景下的 RLHF 流程中独有的模块,原生的 PPO 算法(用于机器人、游戏等)没有这两个模块,因为在传统的强化学习(比如玩超级玛丽)中,环境会直接给你 Reward(吃到金币 +1)。但大模型生成一段话,环境(用户)不会立刻给你打分。因此,我们需要模拟一个环境,而 reward model 这个模块就是干这个事情的,其作用是为 Actor model 提供环境的 reward;而 reference model,顾名思义,就是为了避免模型偏离原始参数太多的一个 “参考模型 “,在实际中会通过与当前 actor model 的输出的分布的差异做对比,通过 KL 散度来惩罚分布差异变化过大的情况
- Actor Model(策略模型)
这个模型的功能是生成语言模型的输出(如对话中的 response),是训练的主要目标;通常会基于上面步骤(1)的 SFT 模型初始化,然后通过策略梯度更新参数,最大化奖励信号同时避免偏离参考模型即 Reference Model
- Reference Model(参考模型)
这个模型也是通过 SFT 模型初始化的,且参数是固定不更新的,相当于 Actor 的初始版本,用于计算 KL 散度约束(当前 actor model 和 reference model 输出的分布差役,防止 Actor 在训练中过度偏离原始分布,用与缓解奖励作弊(Reward Hacking)和灾难性遗忘(Catastrophic Forgetting)
奖励作弊主要是指模型通过偏离合理策略(如生成编造虚假信息),来提高奖励分数;灾难性遗忘则是指模型在优化新任务时,丢失了预训练阶段学到的通用知识;具体的生效方式,都是通过 KL 散度来约束 Actor Model 和 Reference Model 的输出差异不会过大
- Reward Model(奖励模型)
这个模型就是上面提到的阶段(2)中训练出来的模型,其功能是对生成的 response 进行实时打分,提供即时奖励信号;训练方式通过人类标注的偏好对(good/bad response pairs)进行对比学习,跟 Reference Model 类似,参数在训练过程也是被冻结不更新的
- Critic Model(评论家模型)
Reward Model 预测的是即时收益(即当下这个动作的收益),Critic Model 预测的则是当前状态的长期收益。Critic Model 的重要作用之一是平滑梯度,因为如果我们只靠最后的 Reward 来更新,梯度的方差会非常大(因为一句话写得好可能只是运气)
Critic Model 的输出主要是用于计算优势函数(Advantage Function),指导 Actor 的优化方向。这里提到的 “优势函数” 的计算方法因具体强化学习算法而异,但其核心思想是衡量特定动作相对于策略平均表现的优劣程度,以 PPO 算法为例,优势函数的定义如下
\[A(s,a)=Q(s,a)−V(s)\]
- \(V(s)\):状态价值函数 (State-Value Function),表示在状态 s 下按当前策略执行所有动作的平均预期回报(在 PPO 中由 Critic Model 预估当前时刻的未来预期 reward 得到的)
- \(Q(s, a)\):动作价值函数 (Action-Value Function),表示在状态 s 下执行动作 a 后的预期总回报(包含未来奖励的折现),可以直观拆解为当前执行动作后的即时收益和下一时间的状态价值(在 PPO 中是 Reward Model 预估的即时 reward 和 Critic Model 预估下一时刻的未来 reward 加和得到的)

则当 \(A(s,a)>0\),说明动作 a 优于平均表现,反之差于平均
关于这个函数为什么会是这个形式,这篇文章给了一个比较通俗的例子《人人都能看懂的 RL-PPO 理论知识》(ps,这篇文章整体也非常推荐一读)

Critic Model 的角色跟 Reward Model 有点像(实际上,在后来的 GRPO 算法中也把 Critic Model 给去掉了),但 Critic Model 的参数是更新的,由于是预测价值,因此更新的方式也是基于 mse 这一类 loss 来最小化实际收益和预测收益差异;
因此, PPO 的一轮训练过程是这样
1、Actor 根据当前策略生成 response
2、Reference Model 计算 KL 散度(防止跑偏),Reward Model 给出最终的原始分数,最终 Reward = RM 分数 - KL 惩罚
3、Critic Model 观察生成过程中的每一个状态,给出上面预测的 \(V(s)\) 值
4、Actor 通过第二步计算的 “最终 Reward“和第三步计算的 \(V(s)\) 值,进而计算上面提到的优势函数 \(A(s,a)\), 通过并 PPO-Clip 机制更新 Actor 的参数
5、Critic 也会根据实际回报(Return)和预测值(Value)的误差调整自身的参数
关于 Actor Loss 和 和 Critic Loss 《图解大模型 RLHF 系列之:人人都能看懂的 PPO 原理与源码解读》,文章给出了代码示例,整篇文章也推荐一读
DeepSeek-R1-Zero: Pure RL with GRPO
虽然前面提到的 PPO 的范式中的 Actor-Critic 范式看起来似乎比较合理,但 Critic 训练的准确性,其实是没法保证的,所以当价值函数不够准确时,与其用一个错误的价值评估,还不如直接舍弃掉这个评估
Group Relative Policy Optimization(GRPO)就是这么做的,GRPO 是一种在 DeepSpeek-v2 中提出的强化学习算法,前面提到 Critic Model 的角色跟 Reward Model 有点像,而在 GRPO 算法中其实是 Critic Model 去掉了,那 GRPO 是怎么做的?简单来说就是通过多次采样同一问题的不同回答,直接利用组内奖励的统计特性(如均值、方差)计算相对优势,GRPO 的跟 PPO 的区别如下
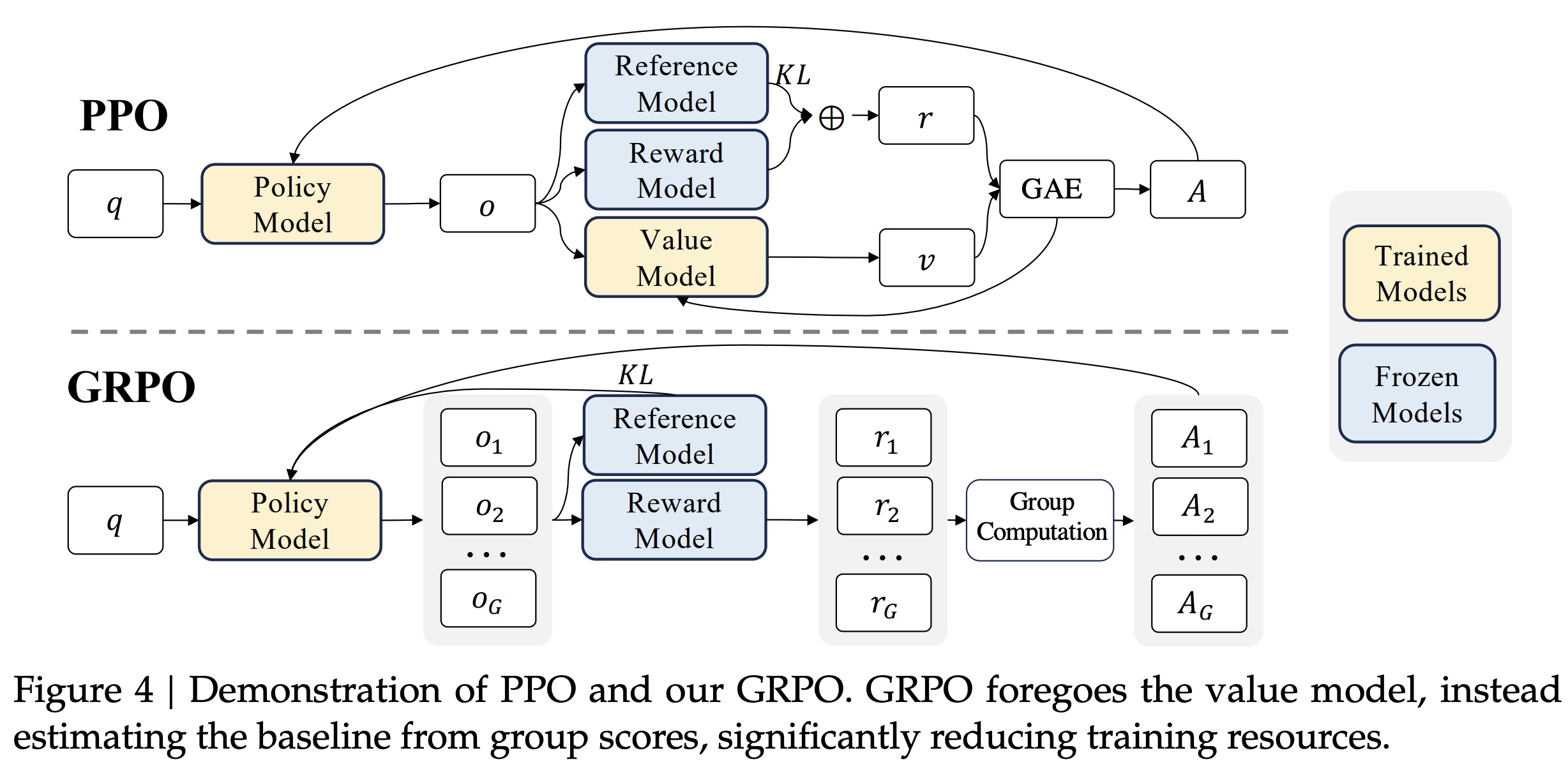
可以看到,GRPO 没有了 Value Model (也就是 Critic Model),取而代之的是每次生成 \(G\) 个 output,然后分布算出这 \(G\) 个 output 的 reward,计算方式如下所示

得到了 \(G\) 个 reward 后,通过 Group Computation 计算出各个 reward 优势函数 \(A_i\),计算方法就是基于 group 内的均值和方差来计算,paper 里分成了两种类型:Outcome Supervision RL 和 Process Supervision RL(一个关注最终结果,一个关注过程每个步骤),但计算方式都差不多

则 policy model 的损失函数可以写成下面的形式
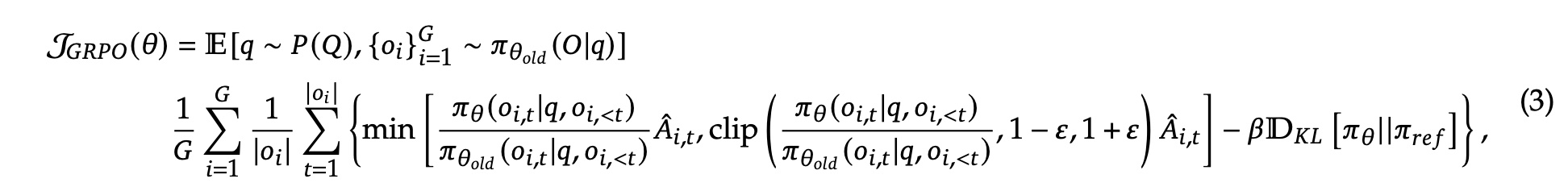
则通过 GRPO 训练的整体算法流程如下所示

Reward Modeling
虽然取消 Critic Model 保留了 Reward Model,但在 DeepSeek-R1 使用的 Reward Model 也不像前面 PPO 方法中提到的基于模型预估的,而是采用了 rule-based 的 reward modeling,paper 中采用了两种 rule-based 的 reward:accuracy reward 和 format reward;而采用 rule-based 的原因是如果还是基于预估值的 reward modeling 的方式,在这种大规模的 RL 训练中,很容易出现 reward hacking 的问题(实际上所有基于预估来获取 reward 的方式都会有这样的问题),同时也会让训练变得更加复杂

DeepSeek-R1: User-Friendly Model with Cold Start
尽管通过 GRPO 算法训练获得了推理能力的显著提升,DeepSeek-R1-Zero 在评测上效果还不错,但是在实际使用时,仍存在一些缺陷。一方面,R1-Zero 生成的推理内容可读性欠佳,语言混合的情况时有发生,这使得其推理过程难以被清晰理解。另一方面,由于直接在基础模型上进行强化学习,没有前期的引导,训练初期模型的表现不稳定,收敛速度较慢
DeepSeek-R1-Zero encounters challenges such as poor readability, and languagemixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates a small amount of cold-start data and a multi-stage training pipeline.
为了解决这些问题,DeepSeek-R1 在 R1-Zero 的基础上进行了如下 4 点改进
(1)Specifically, we begin by collecting thousands of cold-start data to fine-tune the DeepSeek-V3-Base model
(2)Following this, we perform reasoning-oriented RL like DeepSeek-R1-Zero
(3)Upon nearing convergence in the RL process, we create new SFT data through rejection sampling on the RL checkpoint, combined with supervised data from DeepSeek-V3 in domains such as writing, factual QA, and self-cognition, and then retrain the DeepSeek-V3-Base model
(4)After fine-tuning with the new data, the checkpoint undergoes an additional RL process, taking into account prompts from all scenarios.
(1)冷启动
DeepSeek-R1 收集了数千条长思维链(CoT)数据来微调 DeepSeek-V3-Base 模型,并在这之后进行上面提到的 RL 训练过程。这些数据通过多种方式获得,如少样本提示、引导模型生成带反思验证的答案等。冷启动数据提升了模型输出的可读性,并融入人类先验知识,为模型提供了更好的训练起点;在微调后再采用上面的训练 DeepSeek-R1-Zero 的方式,整体的效果是要优于纯 RL 训练得到的 DeepSeek-R1-Zero
(2)语言一致性奖励
针对 DeepSeek-R1-Zero 推理中语言混合的问题,DeepSeek-R1 在强化学习训练时引入语言一致性奖励。这个奖励是依据思维链(CoT)中目标语言单词的比例计算,比例越高奖励越高。虽然这会使模型性能稍有下降,但能有效缓解语言混合现象,让推理过程更符合人类阅读习惯
(3)拒绝采样(Rejection Sampling)与监督微调 (SFT)
前面两个步骤都把重点放在了 reasoning 上,在这一步则是搜集各种数据来提升模型的一般能力如 writing, role-playing 等(可能也侧面说明了在最终商用的模型中,SFT 这一环节还是少不了的)
具体包含了两部分数据:推理数据(Reasoning data) 和 非推理数据(Non-Reasoning data), 拒绝采样(Rejection Sampling)的含义指的是生成多个候选输出,并根据特定标准筛选出最优样本,从而提升数据的质量。例如,生成 10 条可能的推理路径后,仅保留最符合逻辑或最接近正确答案的样本
对于推理数据的搜集,一部分来自前面训练好的模型中,从中得到 reasoning trajectories,然后使用基于规则的简历来做拒绝采样(eg. 答案是否符合预设格式、最终结果是否正确);另一部分则是引入生成式奖励模型(generative reward model),即判断模型的推理逻辑是否与人类标注的参考答案(ground-truth)匹配,这部分是通过将模型生成的预测与真实答案(ground-truth)输入 DeepSeek-V3,评估逻辑一致性和语义匹配度;整体的推理数据过滤得到了大概 600k 的数据
We curate reasoning prompts and generate reasoning trajectories by performing rejection sampling from the checkpoint from the above RL training. In the previous stage, we only included data that could be evaluated using rule-based rewards. However, in this stage, we expand the dataset by incorporating additional data, some of which use a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment. Additionally, because the model output is sometimes chaotic and difficult to read, we have filtered out chain-of-thought with mixed languages, long parapraphs, and code blocks.
对于非推理数据,如写作、事实性问答等,复用 DeepSeek-V3 的部分 SFT 数据集,共收集约 200k 样本
利用这些总计约 800k 样本,对基础模型即 DeepSeek-V3-Base 进行两个 epoch 的微调,同时提升了模型的基础推理能力和通用任务上的能力(MoE 的体现之一)
(4)全场景强化学习
这一步主要是使模型与人类的偏好更一致(如无害性、实用性),在步骤(3)的模型基础上进行的额外的强化学习的训练。 为了达到无害性,需要通过关注推理过程(reasoning process)和最终的结果(summary),识别并移除任何可能的有害的内容);而实用性则主要关注最终的结果(summary)的有效性;具体做法 paper 了没提,关键点是奖励信号的设计和组合(eg. 对于无害性,需要通过检测推理过程或最终的结果中是否含有暴力、歧视性词汇,进而确定具体 label)
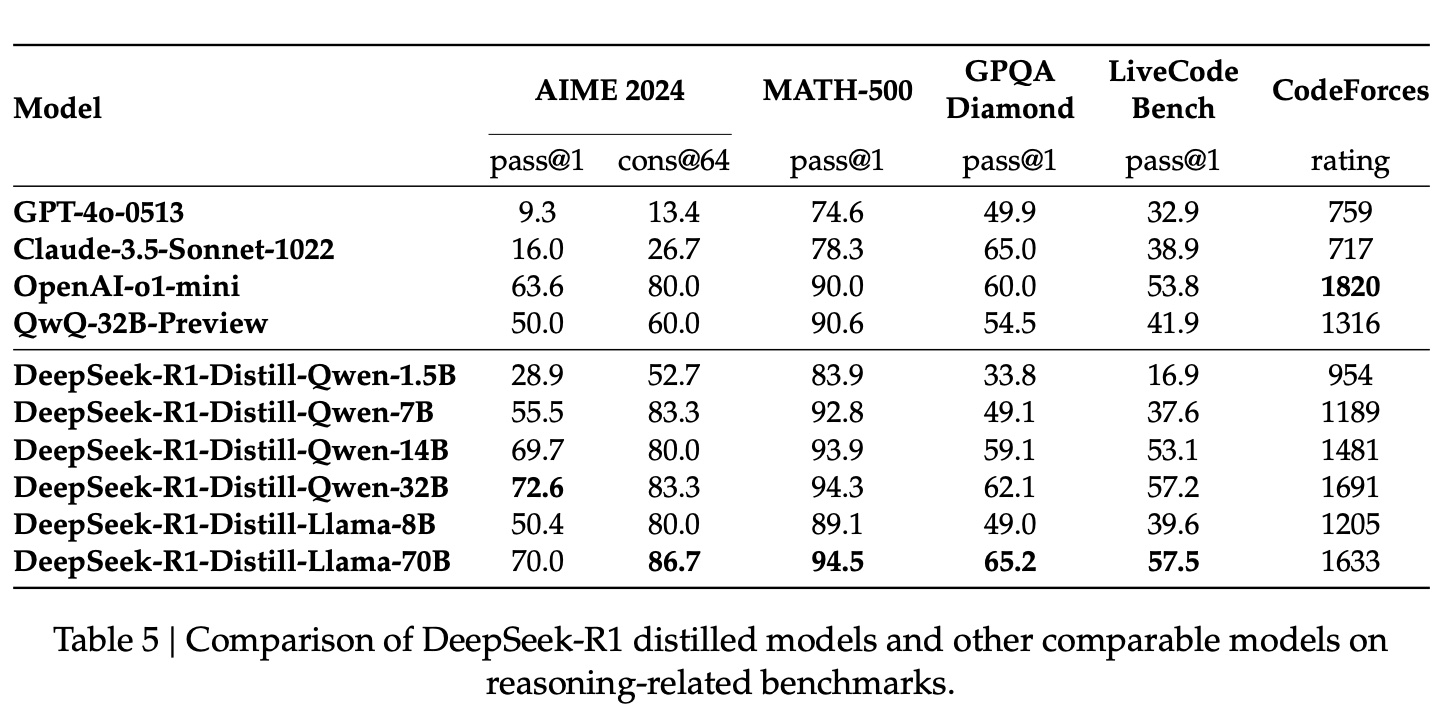
Distillation
报告也证实了一个关于蒸馏的 “常识”:即可以把 DeepSeekd 模型的推理能力蒸馏到其他模型,得到的效果会比原来的模型以以及公开的蒸馏模型要更好,如下图所示
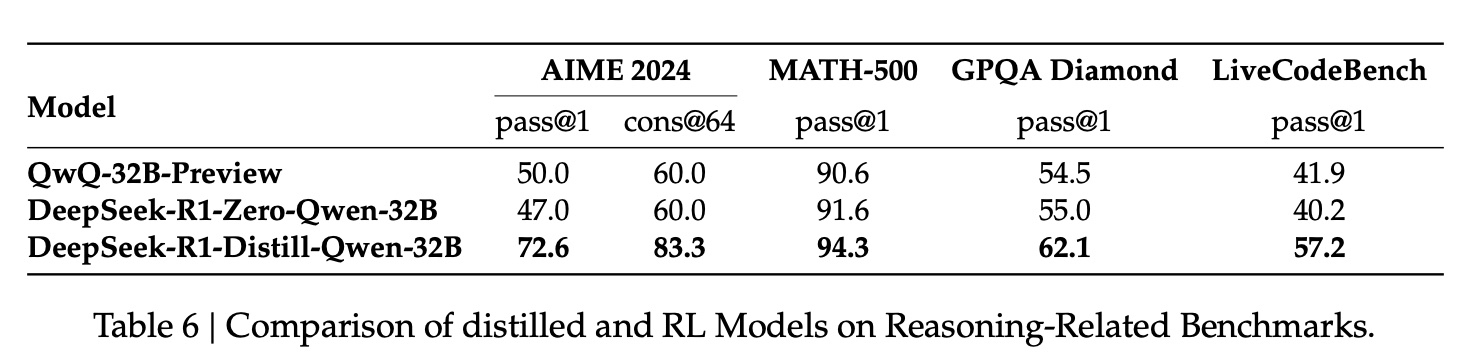
另外,在模型参数相同情况下,蒸馏出来的模型比起只在模型上使用 DeepSeek-R1-Zero 的训练流程得到的效果要更好,同时使用的算力要更小, 如下图所示,这能降低模型商用的成本的一个重要途径
distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation
Unsuccessful Attempts
这部分主要提到了两个不成功的尝试:Process Reward Model (PRM) 和 Monte Carlo Tree Search (MCTS)
Process Reward Model (PRM) :这部分主要是指过程奖励模型在实际中比较难落地,paper 提到主要有以下几点原因:一是把定义步骤会比较困难(即把推理过程拆解成各个步骤),二是为每个步骤定义一个 reward 也会比较困难(模型打分不考虑,人工标注不现实),三是如果 PRM 基于预估得到每个步骤的 reward,不可避免地会出现 reward hacking 地问题,原因跟上面提到的一样:所有基于预估来获取 reward 的方式都不可避免会有这样的问题
Monte Carlo Tree Search (MCTS) :蒙特卡洛树搜索,这个在 AlphaGo 中关键的方法,未被证明在大模型的训练中同样有效,其主要原因还是搜索空间过大和以及价值模型训练困难,paper 里是这么做的
MCTS involves breaking answers into smaller parts to allow the model to explore the solution space systematically. To facilitate this, we prompt the model to generate multiple tags that correspond to specific reasoning steps necessary for the search. For training, we first use collected prompts to find answers via MCTS guided by a pre-trained value model. Subsequently, we use the resulting question-answer pairs to train both the actor model and the value model, iteratively refining the process.
MCTS 需要对每一步生成的可能路径进行多次模拟和评估。在下棋中这个可能的路径数量是有限的,但在自然语言生成中,每个 token 的选择涉及数千甚至数万种可能性,导致搜索空间呈指数级增长。例如,一个包含 100 个 token 的句子,若每个 token 有 100 种候选词,总路径数为 100^100,远超可行计算范围;当然也可以提前做剪枝之类的,但 paper 提到了这容易导致模型学不好(getting stuck in local optima)
另外 MCTS 也需要训练一个价值模型来评估中间步骤,这个模型训练会比较困难,主要是奖励信号比较难定义(跟前面 PRM 提到的原因一样);所以一般的经验是 MCTS 更适合封闭式、目标明确的任务(如解题、代码生成),但在开放域生成(如创意写作、多轮对话)中效果有限
Kimi
Kimi 的这篇报告 KIMI K1.5:SCALING REINFORCEMENT LEARNING WITH LLMS,整体的方法跟 DeepSeek-R1 比较相似,可以说是殊途同归了
两篇报告都显示通过 RL 推动模型自主生成思维链(Chain-of-Thought, CoT),出现了如自我验证、反思等行为;同时能够显著提升模型推理能力,尤其在数学、编程等复杂任务中
同时两者均通过蒸馏技术将大模型能力迁移至小模型;Kimi 提出 Long2Short 优化(如模型合并、DPO 训练),DeepSeek-R1 直接使用大模型生成数据微调小模型
但 Kimi 的训练流程跟 DeepSeek-R1 不太一样,Kimi 整体还是采用多阶段训练(预训练→监督微调→长链 SFT→RL),不像 DeepSeek 做了纯 RL 的探索;另外,Kimi 这篇报告中提到了非常多的训练细节,这也是 DeepSeek 和 OpenAI 中没有提及的,这部分对其他团队复现也提供了非常多有用的信息
报告提到通过 “Long context scaling” + “Improved policy optimization”,就能取得不错的效果,而不用依赖一些比较复杂的技术,如上面提到的无效的探索蒙特卡洛树搜索(Monte Carlo tree search) 和 过程奖励模型(process reward models),在 Kimi 中也并没有被采用
Long context scaling
这里的 Long,指的是将 RL 上下文窗口扩展至 128k tokens,支持生成更长的思维链(Chain-of-Thought, CoT),提升复杂推理能力
报告里提到一个概念:RL prompt set,这是一组经过精心筛选的问题(如数学题、编程题、逻辑推理题等),用于引导模型在强化学习过程中生成长链推理(CoT),也是重要的训练数据来源;这部分数据需要满足以下约束
- 多样性覆盖:覆盖 STEM、编程、通用推理等多领域,确保模型适应不同任务
- 可评估性:答案可通过规则(如数学公式验证)或测试用例(如编程题)客观验证,排除易被猜测的问题(如选择题)
- 平衡的难度:包含简单、中等、困难的问题,促进模型逐步学习复杂推理
具体的构建方法如下
(1)自动筛选;通过模型自评估(如 SFT 模型生成多次答案,计算通过率)确定问题难度;通过过滤易被 Reward Hacking 的问题,例如排除答案格式简单或可通过随机猜测解决的问题
(2)标签系统;使用领域标签(如数学、编程)和难度标签(易 / 中 / 难)分类问题,确保训练数据的均衡分布。如数学竞赛题标记为 “高难度”,小学数学题标记为 “低难度”
(3)验证与排除;若模型无需推理即可在多次尝试中猜中答案(如 8 次尝试内成功),则该问题被排除;避免包含需要主观判断的问题(如证明题),以保持评估的客观性
长链 SFT(Long-CoT Supervised Fine-Tuning)的训练数据,就是基于 RL prompt set 中的问题,通过人工或自动生成高质量的 CoT 标注(例如通过拒绝采样或人工精修)得到的,这部分跟 DeepSeek-R1 中的冷启动部分数据作用基本一致
Improved policy optimization.
Policy Optimization
报告提出基于 Online Policy Mirror Descent 的一个变种算法,其做法跟上面提到的 GRPO 也比较相似,同样去掉了 Critic model,其中 \(r\) 是 reward model,\(\pi\) 是 actor model (报告里也成为 policy model) 和 reference model

上面公式(3)显示的最终的函数跟 GRPO 也比较相似,用作 loss 加权的 reward 是由当前 \(k\) 个 采样的 response 的 reward 取均值得到,通过有一个 KL 散度约束 actor model 和 critical model 的输出的 diff
Length Penalty
kimi 1.5 引入长度惩罚(Length Penalty),这是在前面 openAI 和 deppSeek 中都没提及的技术,简单来说,就是随着回答长度的增加,边际 roi 在逐步下降(模型效果 / 训练成本)。因此,训练的过程引入了一个 length reward 来约束回答的长度,在 \(k\) 个采样的 response 中计算最大长度和最短长度,然后通过下面的方式对回答长度短的回答增加一个额外的 reward
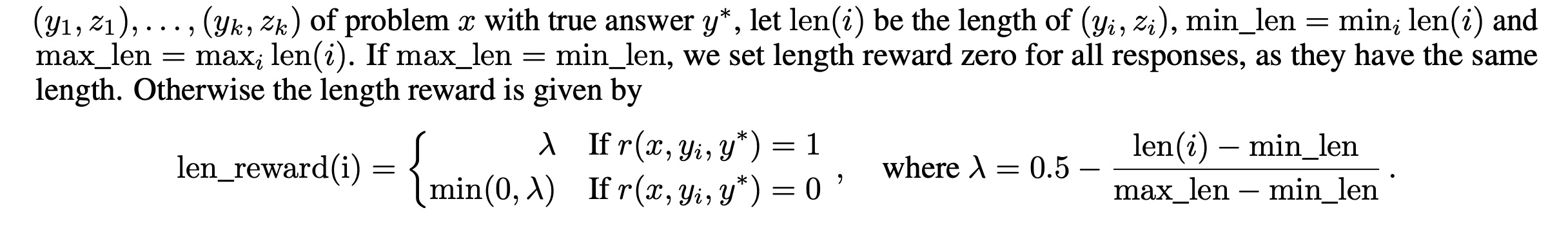
Sampling Strategies
除了 RL 本身的采样策略,paper 也提了两种额外的采样策略:Curriculum Sampling 和 Prioritized Sampling
Curriculum Sampling 指的是先训练简单任务,再训练困难任务(基于 RL prompt set 区分问题的难度);其原因是 RL 模型再最开始的效果不好,如果把同等的训练资源分配到困难任务上,获得的效果不佳,导致训练效率低下
Prioritized Sampling 可理解为会增加对困难任务的采样概率,即如果一个问题的成功率是 \(s_i\),则采样概率是 \(1 − s_i\)
Long2short
这部分的作用跟蒸馏比较类似,都是把一个大模型的能力迁移到小的模型上,这里的 long 和 short 分别指 long-CoT models 和 short-CoT models
为了达到这个目标,报告中主要采用了 4 种方法: model merging, shortest rejection sampling, DPO 和 long2short RL
- model merging:对两个模型的参数做平均
- shortest rejection sampling:对同一个问题采样 n 次(n = 8),然后选择最短的回答做 SFT
- DPO:同样对一个问题采样 n 次,然后选择最短且正确的回答作为 positive sample,长的回答(短回答长度的 1.5 倍及以上)作为 negative sample(无论是否 correct)
- long2short RL:基于训练好的一个模型,采用上面提到的 length penalty 再进行一轮 RL 的训练
小结
当强化学习的梯度在 Transformer 架构中奔涌,一场关于推理能力的静默革命正在重塑大模型的进化轨迹。从 OpenAI-o1 在思维链中构建的 "系统 2" 慢思考范式,到 DeepSeek-R1 用纯强化学习突破 SFT 依赖的惊险一跃;从过程奖励模型 (PRM) 对推理步骤的原子化监督,到 GRPO 算法抹除价值函数后展现的群体相对优势 —— 这些技术突破不仅解构了 "暴力美学" 时代的千亿参数迷信,更在算力与算法的二重奏中谱写出新的可能性。当 DeepSeek 用规则化奖励模型破解强化学习的奖励欺骗困局,当模型蒸馏将推理能力压缩进更轻量的架构,这场技术进化正在证明:大模型的核心竞争力,或许不在于吞噬多少星辰般的数据,而在于如何用更优雅的算法,在显卡残骸上搭建起通向量产智慧的阶梯
上面这段文字,也是让 deepseek 基于这篇文章内容生成了一段总结;看完后还是不禁感慨大模型的能力令人惊艳。而无论拒绝或接受,这场大模型革命正以比蒸汽机更温柔的轰鸣重塑文明肌理;当 18 世纪的纺织工人惊恐地看着珍妮纺纱机,他们不会想到机械臂终将托起整个工业文明;而今面对语言模型中涌现的推理能力,我们比先辈更幸运 —— 每个人都能在开源社区的算力碎片里拾取火种,每个县城开发者都能用 API 接口编织智能神经网络。与其担忧模型参数膨胀是否会吞噬工作岗位,不如成为第一批大模型的 "算法纺织工";历史从不同情被动者,当大模型的思维链已能穿透数学证明的铜墙铁壁,当 DeepSeek-R1 的推理能力正通过模型蒸馏注入老人机的芯片 —— 这场静默的认知革命,终将把迟疑者永远留在蒸汽朋克的隐喻里