个性化排序公式:从个性化精排到个性化混排再到全局重排
“个性化排序公式” 是推荐系统里老生常谈的话题,但很多时候,这个词其实指代不清,因为我们经常把三层不同的问题混在一起说。
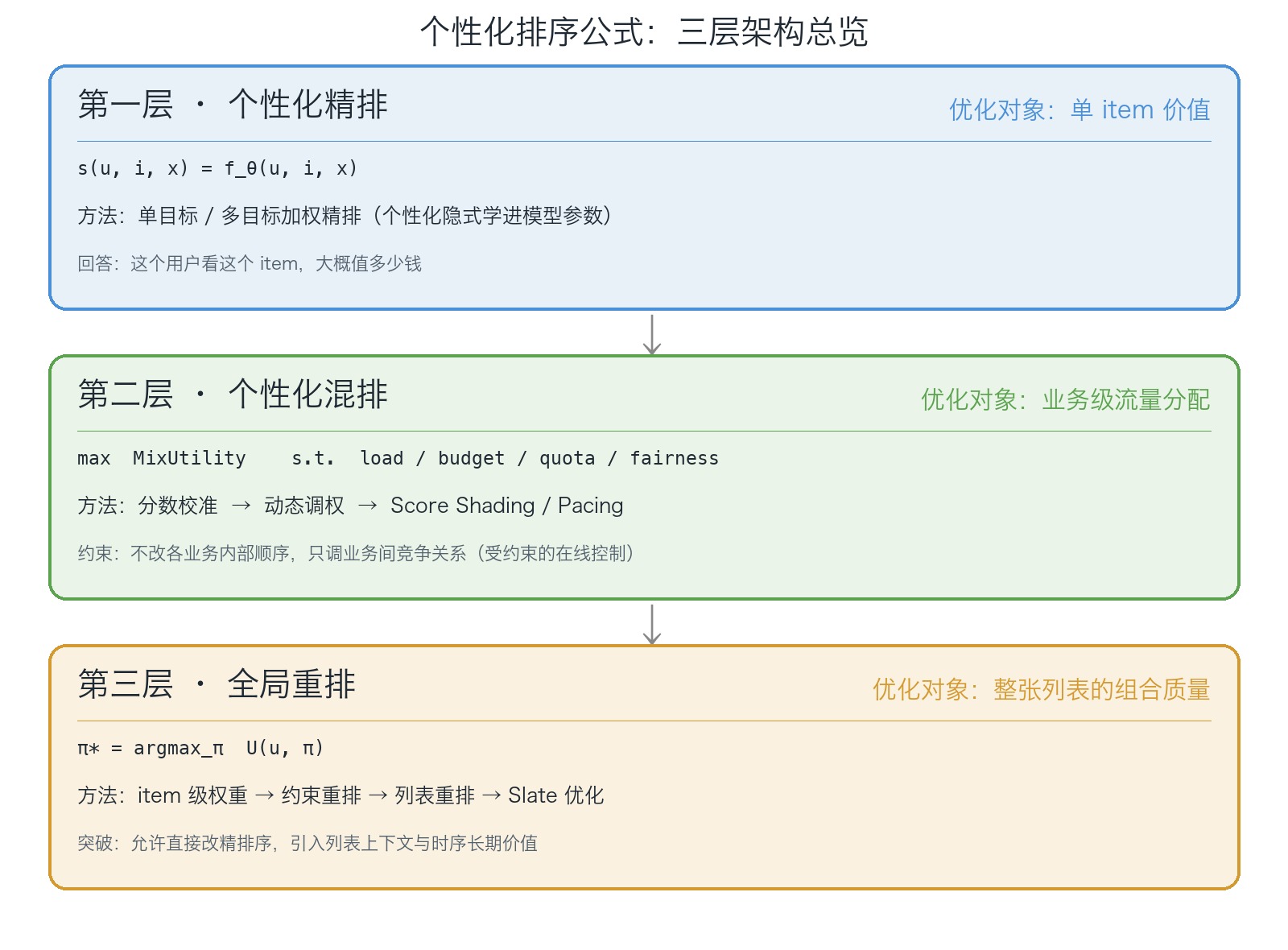
更准确地讲,推荐系统里的个性化排序,通常至少包含三层:
- 第一层:个性化精排,回答的是 “这个用户看到这个 item,大概价值是多少”
- 第二层:个性化混排,回答的是 “在多个业务同时竞争流量时,这次曝光机会应该先给谁”
- 第三层:全局重排,回答的是 “用户最终看到的是一整张列表,这张列表该怎么拼才最好”
很多推荐系统做到今天,第一层其实已经足够强了。
User embedding、item embedding、多任务学习、cross feature,这些东西的目标都很明确:让模型尽可能准确地回答一个问题: 这个用户看到这个内容,大概价值是多少。从这个意义上说,很多系统的排序公式早就已经是个性化的了,只不过这种个性化不是显式写成 “每个用户一组权重”,而是被模型隐式学进了参数里。
但真实系统往往会出现一个看起来有点矛盾的现象:第一层已经很强了,线上仍然还在做第二层混排、控量、保量,以及第三层重排,甚至还要单独做 score calibration、pacing、shading、listwise rerank。
如果只是从直觉上理解,很容易把这件事解释成一句话:第一层还不够准,所以第二层和第三层是在打补丁。这个解释不能说错,但它只解释了一半。
因为更本质的问题在于:第一层、第二层、第三层,优化的根本不是同一个对象。
- 第一层优化的是单个 item 的价值预估
- 第二层优化的是多业务之间、带约束的流量分配
- 第三层优化的是整张列表的组合质量
也正因为如此,“个性化排序公式” 真正值得讨论的,并不只是 “不同用户的权重为什么不同”,而是:当第一层已经能够较好学习用户对单个 item 的偏好之后,平台为什么还必须引入第二层个性化混排和第三层全局重排?它们分别在弥补什么,又分别在优化什么?
本文想讨论的,正是这个三层问题。
为了避免后面分层细节淹没主线,先给一张全景图把三层的优化对象、关键方法和边界放在一起:
第一层解决了什么
从数学形式上看,第一层精排通常学到的是一个函数:
\[ s(u,i,x) = f_\theta(u,i,x) \]
其中,\(s(u,i,x)\) 是第一层精排给出的分数 / 预估价值,\(f_\theta\) 表示参数为 \(\theta\) 的打分函数;\(u\) 是用户,\(i\) 是 item,\(x\) 是上下文,\(\theta\) 是模型参数。这个分数本质上在回答:
在当前上下文下,把这个 item 展示给这个用户,预期能产生多大价值?
这个价值可以是单目标,比如 CTR;也可以是多个目标的组合,比如:
\[ s(u,i,x) = w_1 \cdot CTR + w_2 \cdot CVR + w_3 \cdot WatchTime + w_4 \cdot GMV \]
这里,\(w_1, w_2, w_3, w_4\) 表示不同目标的组合权重;CTR、CVR、WatchTime、GMV 分别表示点击率、转化率、观看时长和成交金额等目标信号。
如果模型足够强,它当然可以学到很深的个性化差异:
- 有的用户更偏停留时长
- 有的用户更容易被电商内容转化
- 有的用户对广告非常敏感
- 有的新用户更需要稳定体验,有的老用户更能接受更强的个性化分发
所以,从 “用户和内容是否匹配” 这件事本身来说,第一层已经能做得很深入。它真正擅长的是一句话:
这个用户看这个 item,大概值多少钱。
问题在于,推荐系统要解决的,从来不只是这一件事。
单 item 打分为何不够
如果只靠第一层精排就想做完全部决策,至少要同时满足下面四个条件(假设)。
这四个条件其实分两组:
(1)单项可加 和 分数同量纲 决定的是 pointwise「加和 - 排序」这种范式在数学上能否成立,是第三层(列表组合优化)出现的根本原因
(2)没有额外全局约束 和 环境是静态的 决定的是问题本身是否还带有资源约束与时间维度,是第二层(流量分配与在线控制)出现的根本原因
单项可加
也就是说,最终列表的整体效用必须满足:
\[ U(\pi) = \sum_{k=1}^{K} v(u, i_{\pi_k}, k) \]
这里,\(U(\pi)\) 表示排列 \(\pi\) 的总 utility / 总价值;为了简化记号,这里省略了它对用户和上下文的依赖。\(K\) 表示列表长度,\(i_{\pi_k}\) 表示排在第 \(k\) 位的 item,\(v(u, i_{\pi_k}, k)\) 表示该 item 在位置 \(k\) 上给用户 \(u\) 带来的单项价值。这个公式其实已经隐含了一个很强的假设:每个 item 的价值只取决于用户、item 本身和位置,而不依赖于列表里的其他 item。
但真实系统里,这个假设经常不成立。更常见的情况是:
\[ U(\pi) = \sum_{k=1}^{K} v(u, i_{\pi_k}, k) + \sum_{k<l} g(i_{\pi_k}, i_{\pi_l}, u) \]
其中,第二项里的 \(g(i_{\pi_k}, i_{\pi_l}, u)\) 表示两个 item 在同一张列表里共同出现时,对用户 \(u\) 产生的额外相互作用,比如互补、替代、疲劳或多样性收益。比如:
- 两条高度相似的视频连着出现,第二条往往就没那么想看了
- 同一类内容连续刷太多,用户会更容易疲劳
- 图文、短视频、直播如果穿插着来,用户通常会比一直看同一种内容更不容易腻
- 不同位置适合的内容也不一样,比如前面的位置更适合抓眼球的内容,后面的位置更适合承接兴趣的内容
- 用户看一整页时,感受到的不只是单条内容好不好,还包括这一页够不够丰富、够不够新、是不是更贴近自己当下的场景
一旦这个项存在,pointwise 的单 item 打分就不足以推出最终列表最优。
分数同量纲
这个条件在现实里也几乎不会成立。
因为不同业务、不同模型、不同目标的分数,往往天然不是一个量纲:
- 图文精排的 0.4
- 直播精排的 0.2
- 广告的 eCPM
- 电商的 GMV 预估
这些分数背后的训练目标、样本分布、噪声水平和业务含义都不一样。即使它们都 “看起来像一个分数”,也不代表它们能直接比较。
所以,第一层很难做到完全估准,多目标之间也很难做到真正同量纲,这确实是后面需要第二层和第三层的重要原因之一。
但这还不是全部。
没有额外全局约束
如果系统只需要最大化某个统一效用,那第一层确实更容易一把梭。
但真实推荐系统通常还会带着很多作用在 “整体结果” 上的约束:
- 营销业务(如广告、电商、直播)的 load 约束(本质是 LT,但可能会以 load 作为外显)
- 营销感打散(即不能同时出多个营销型 item)
- 多样性
- 作者 / 商家公平
- 平台生态平衡
- ….
这类约束不是作用在某个单 item 上,而是作用在整张列表、整段时间窗口、甚至整个流量池上。因此,单个 item 分数再准,也不等于系统能自动满足这些约束。
环境是静态的
如果流量环境是静态的,排序问题会简单很多。
但真实系统面对的是持续变化的动态环境:
- 某个业务这小时是不是已经出太多
- 用户是不是已经看腻
- 当前是不是该保留探索流量
- 某类供给是不是突然变少了
到了这里,问题已经不只是 “排序”,而是带有明显控制色彩的动态决策问题。
所以,现实中的推荐系统并不是在解一道 “给每个 item 打分然后排序” 的静态题,而是在解一道 “在约束下分流量、拼列表、保稳定” 的动态系统题。
这就是为什么第一层已经很强了,第二层和第三层仍然不可省略。
第二层的职责:在多业务之间分流量
很多推荐系统里,参与竞争的并不是单一内容源,而是多个业务共同争夺曝光机会,比如:
- 图文
- 短视频
- 直播
- 电商卡片
- 广告
- 本地生活内容
每个业务内部通常都已经有自己的召回、粗排、精排链路,也都能比较好地回答 “自己家候选谁更好”。但平台真正要回答的问题不是 “这个业务内部谁更值得出 “,而是 “这一次曝光机会,到底应该给哪个业务?“
这已经不是单 item 预估问题,而是一个典型的跨业务资源分配问题。
而且这个问题通常还天然带着一堆平台约束:
- 某业务有渗透目标
- 某业务的 load 不能掉太多
- 广告不能超量
- 平台不希望某一类内容长期把其他体裁挤穿
- 某些业务当前体验已经紧张
- 某些业务在当前时段服务器或供给容量有限
- 某些业务的精排分不适合直接和别的业务硬比
这时,平台真正面对的更像是下面这种问题。其中,\(\text{MixUtility}\) 表示混排层希望最大化的整体收益;\(\text{Load}, \text{Budget}, \text{Quota}, \text{Risk}, \text{Fairness}\) 则分别表示流量占比、预算、配额、风险、公平性等平台约束:
\[ \begin{aligned} \max \quad & \text{MixUtility} \\ \text{s.t.} \quad & \text{Load},\text{Budget},\text{Quota},\text{Risk},\text{Fairness} \end{aligned} \]
到了这里,第一层即使把每个 item 的价值预估得再准,也不能自动回答 “流量应该怎么分”。
平台仍然需要一个额外的决策层,去处理:
- 不同业务之间如何校准
- 当前预算和目标下,哪个业务更值得拿这次流量
- 某个业务是该提价、降价、保量还是控量
- 如何在局部收益和整体稳定性之间做平衡
这就是第二层混排存在的原因。
这里有一个例子:
假设某个用户明显喜欢直播,不太喜欢图文。那么最直接的想法是:在混排里把直播整体权重抬高。
这件事在很多时候是有效的,因为它解决的是:这次流量更应该从直播队列拿,还是从图文队列拿?
但这里有一个边界也必须明确:第二层只能决定 “流量给谁”,不能决定 “这个业务内部哪条最该出”。
如果直播业务内部 top1 恰好是一条强卖货直播,而这个用户真正喜欢的是 “讲知识点的轻直播”,那么混排层即使不断提高直播权重,也只是更频繁地把 “不适合的直播” 推给用户。因此,第二层虽然必要,但它有天然上限:它更像一个业务级的调度器,而不是 item 级的最优选择器。
如果把每个业务都看成一个已经排好序的队列,那么第二层做的事情可以非常直观地理解成:
- 不动各业务内部顺序
- 每次决定 “下一张卡从哪个业务拿”
也就是说,第二层优化的并不是单个 item,而是业务级 / source 级的流量调度策略。
这里有一个很容易产生的误解是:第二层是不是本质上就是各参与方不断调整自己的权重项,尽量把彼此的价值量纲对齐?
这个理解只说对了一半。
因为第二层确实包含 “让不同业务的分数尽量变得可比” 这件事,但这只是第二层的起点,而不是它的全部。更完整地说,第二层实际上在做两步:
1)先把不同参与方的局部价值映射到一个大致可竞争的空间里
2)再在这个空间上,结合平台侧的约束、预算状态和流量目标,做带约束的动态流量分配
所以,量纲对齐更像是第二层的 “入场券”,而受约束的资源分配才是第二层真正的主体问题。
从这个角度看,下面这些方法本质上都属于第二层:
- score calibration
- personalized multiplier
- quota / pacing
- score shading / bid shading 风格的动态调分
- 各种带约束的保序混排
因此,第二层并不只是对 “不够准的精排分” 做修补,它更像是给平台增加了一层新的能力:
在不改动各业务内部排序的前提下,做一层受约束的、动态的、个性化的流量控制。
第二层的方法:不改变精排序的个性化混排
上面讲的是为什么第二层一定会存在。接下来再看,这一层具体有哪些主流方法。
分数校准
这是最容易被忽略、但在工程上最关键的一步。
因为不同业务的精排分,往往天然不是一个量纲:
- 图文精排的 0.4
- 直播精排的 0.2
- 广告 eCPM 的 15
- 电商 GMV 预估的某个归一化值
这些分数如果直接拿来 PK,通常没有意义。因为它们对应的模型目标、样本分布、训练方式和业务含义都不一样。
所以,在真正进入个性化混排之前,平台往往要先做一层 calibration,包括:
- 分桶校准
- 分位数归一化
- Platt Scaling / Isotonic Regression
- 按 user segment / 场景做条件校准
或者就是最简单的根据不同业务过去一段时间的 avg 的量纲的差距,直接拍一个一段时间内固定的系数用来做量纲的对齐。这一步的本质是:先解决 “能不能比” 的问题,再去解决 “怎么分” 的问题。
如果没有 calibration,后面的 personalized multiplier、pacing、shading 都会失真。
动态调权
当不同业务的分数已经大致可比较后,最直观的一种做法就是对业务级得分做动态加权:
\[ \text{MixScore}_{u,b} = \alpha_{u,b}(x) \cdot \text{CalibScore}_b \]
其中:
- \(\text{MixScore}_{u,b}\) 表示用户 \(u\) 在当前请求下,对业务 \(b\) 的混排分
- \(\text{CalibScore}_b\) 表示业务 \(b\) 在经过量纲对齐后的可比基础分
- \(b\) 表示业务 / source
- \(\alpha_{u,b}(x)\) 表示用户 \(u\) 在上下文 \(x\) 下对业务 \(b\) 的偏好权重
例如:
- 某些用户更偏直播,就提高直播 source 的 multiplier
- 某些用户更偏图文,就提高图文的权重
- 某些场景更适合短视频,某些场景更适合电商卡片
这种方法的优点是简单、直观、可解释,而且非常适合已有多业务体系的线上系统。它本质上还是 “保序混排”—— 只调业务间的相对竞争力,不改业务内部顺序。
但它的上限也很明确:它只能回答 “这次流量给谁”,不能回答 “这个业务内部哪条最该出”。
Score Shading / Pacing:把混排看成受约束的动态出价问题
再往前一步,平台会发现:光有用户偏好权重还不够,因为很多问题本质上不是 “喜不喜欢”,而是 “在当前约束下,这次流量值不值得拿”。
这时,一个很自然的视角是把混排中的业务分看成 “隐式出价”。
如果广告中的 bid shading 解决的是:
在一价拍卖里,如何在保持获量能力的前提下,降低成本、提升 ROI?
那么混排中的 score shading 解决的就是:
在不改业务内部排序的前提下,如何动态调节业务的 PK 分,在渗透、成本、稳定性之间找到更优平衡?
例如,对于某个业务,可以把问题写成:
\[ \begin{aligned} \max_{s_i} \quad & \sum_i V_i F(s_i) \\ \text{s.t.} \quad & \frac{1}{n}\sum_i s_i F(s_i)\le C \end{aligned} \]
其中:
- \(V_i\):第 \(i\) 次机会下,该业务胜出后的价值
- \(s_i\):当前业务在这次机会中的混排 score / PK 分
- \(F(s_i)\):在分数 \(s_i\) 下的竞胜率
- \(n\):统计窗口内的机会数 / 样本数
- \(C\):成本或量纲约束
通过拉格朗日对偶,可以把它转成单次请求下的决策问题:
\[ s_i^\star = \arg\max_{s_i} F(s_i) \left( V_i - \lambda s_i \right) \]
这里的 \(\lambda\) 严格说是成本约束的拉格朗日乘子(也就是影子价格),工程上通常用 pacing 控制器(PID / EMA 等)在线估计它,使得长期平均成本贴近约束 \(C\);\(s_i^\star\) 表示在第 \(i\) 次机会下的最优混排 score / 最优 PK 分。
这个公式非常有代表性,因为它体现了一件事:第二层不是在 “修一个不准的分数”,而是在做一个受约束的在线控制问题。
这个方法最关键的一步其实不是公式本身,而是如何建模 \(F(s)\),也就是竞胜率模型。这里的 \(F(s)\) 可以理解为 “给定一个待评估的 score \(s\),当前业务赢下竞争的概率”。
直观地说,可以有两种思路:
- 点估计:直接建模 \(P(\text{win}=1|s,\text{context})\),其中 \(P(\text{win}=1|s,\text{context})\) 表示在给定分数 \(s\) 和当前上下文 \(\text{context}\) 时,本业务赢下这次竞争的概率
- 分布估计:不直接建模胜率,而是建模 “对手最高分的分布”,再由分布推导胜率
前者更直观,后者更完整。
一个非常有代表性的工作是 Deep Landscape Forecasting for Real-time Bidding Advertising。它不直接学习某个 bid 下的赢面,而是学习竞争景观(landscape)的分布参数,从而可以解析地得到任意出价下的 win rate。这种思路迁移到混排里同样成立:如果你真正想做 score shading,很多时候需要的不是 “某个分值下会不会赢” 的点判断,而是 “当前竞争环境长什么样” 的整体刻画。
虽然 Score shading 看起来能更好地提升效率,但这个方法如果没有约束,很容易从局部优化变成全局风险。
具体来说,如果平台放任各业务都自己做 shading,会很容易出现两个问题:
(1)分值通缩
所有业务都在想办法 “用更低的分赢到量”,久而久之,整个系统的绝对 score 会左移,最后可能击穿很多依赖绝对值门槛的策略逻辑。
(2)控制震荡
当多个业务都用自己的 PID / pacing 控制器去调分时,它们会在同一流量池里相互影响,形成耦合震荡。最常见的现象就是:上一分钟直播拿太多,下一分钟短视频暴力反补,整个平台呈现高频抖动。
所以,score shading 真正要落地,往往不仅是一个模型问题,更是一个平台机制问题。通常至少要引入下面两种治理思路中的一种:
- 全局锚点(anchor):给系统固定一个相对稳定的 “价值基准”
- 统一记账机制:让各业务的竞争不只是看 “谁报得高”,而是看 “谁真正带来了更高的全局价值”
关于 Score Shading 这个方法的更多细节,可以参考这篇文章:《从 Bid Shading 到 Score Shading:混排优化的建模、控制与博弈》
第三层的职责:把整张列表组合得更好
如果说第二层主要在解决 “流量怎么分”,那第三层解决的则是另一个更本质的问题:用户最终消费的不是单个 item,而是一整张列表。
在第二层里,系统主要回答的是:这次流量先给哪个业务、哪个 source。 它面对的核心对象,仍然是业务级竞争和流量分配;即使里面有 quota、pacing、load 之类的约束,很多时候解决的也是业务级、时间窗口级、资源份额级的问题。
但到了第三层,问题变了。系统真正要回答的是:最终给用户看的这张列表,到底该怎么拼。
这也是第三层和第二层最根本的区别:第二层更像在决定 “量先给谁”,第三层则是在决定 “这张列表本身长什么样”。前者主要管 source 之间的竞争关系,后者直接面对 top-k 的排列、位置、上下文和组合质量。
这句话看起来平常,但它意味着一件非常重要的事:单 item 最优,不等于列表最优。
第一层默认的逻辑通常是:谁分高谁排前面。这个逻辑隐含了一个很强的假设:列表总价值可以拆成每个 item 价值的简单加和。
但现实里,这个假设经常被打破。
最直观的例子就是内容疲劳。假设某个用户的 top-4 候选分数分别是:
- 视频 A:0.90
- 视频 B:0.88
- 视频 C:0.87
- 图文 D:0.80
如果直接按分数排,前三条可能全是高度相似的视频。单看每条内容都没问题,但组合起来,用户体验未必最好。也许把第三条换成图文 D,整页满意度反而更高。
这说明:即使第一层已经把每个 item 的单点评分做得很准,按 pointwise 分数贪心排序,也未必等于最终 top-k 列表的全局最优。
这就是第三层存在的根本原因。
它解决的已经不是 “这个 item 值多少钱”,而是:这张列表怎么拼,才能让整体效果最好?
第三层的方法:允许直接改精排序的全局重排
到了第三层,优化对象不再只是 “哪个业务赢这次曝光”,而是整个排列:
\[ \pi^\star=\arg\max_{\pi} U(u,\pi) \]
其中,\(U(u,\pi)\) 表示用户 \(u\) 在看到排列 \(\pi\) 时,这整张列表带来的总 utility / 总价值;\(\pi\) 表示最终列表,\(\pi^\star\) 则表示使该目标最大的最优列表。
系统真正关心的是:
- top-k 的整体体验
- item-item 的替代与互补
- 多样性
- 位置偏置
- 公平性
- 长期价值
因此,这一层的方法会比第二层复杂得多。在展开具体方法之前,先建立一张总览。第三层里至少有两步:
- 先把单个 item 的 utility 定义得更合理。item 级个性化权重属于这一步,它解决的是 “这条内容本身值多少钱”
- 再把最终列表优化得更合理。约束重排、列表重排、Slate 优化属于这一步,它们解决的是 “这些 item 放在一起之后,整张列表该怎么组”
如果打个比方,item 级个性化权重更像是在定义 “每块砖值多少钱”;而后面三类方法,则是在决定 “这些砖该怎么砌成一堵墙”。
沿着这个角度继续往下拆,第二步里又可以分成三类,从「硬规则」到「软质量」再到「时序长期价值」逐步抬高:
- 约束重排:先回答 “哪些列表不能出”
- 列表重排:再回答 “在能出的列表里,哪一张更好”
- Slate 优化:进一步回答 “这张列表不仅影响当前,还会沿着用户消费过程持续影响后续行为”
下面分别展开。
item 级别的个性化权重
需要先做一个边界说明:item 级个性化权重严格说位于第一层和第三层的边界上,本文把它放在第三层讨论,是因为只有当它作为「精排之后额外的一层 utility 调整」存在时,它才属于第三层;如果直接做在精排模型内部,它本质上仍是第一层。下面的讨论默认前者。
这一步最常见、也是工业上最容易落地的一类方法,是直接对 item 级 utility 建模:
\[ U(u,i,x) = \sum_k w_k(u, x)\,\phi_k(i, x) \]
其中:
- \(U(u,i,x)\) 表示用户 \(u\) 在上下文 \(x\) 下看到 item \(i\) 时,这个 item 带来的 utility / 价值
- \(\phi_k(i,x)\) 表示 item \(i\) 在上下文 \(x\) 下第 \(k\) 个目标上的信号或预估值,比如 CTR、CVR、GMV、时长、留存、商业价值等
- \(w_k(u,x)\) 是与用户和上下文相关的动态权重
- \(k\) 表示不同目标的索引
和第二层的 business multiplier 相比,两者形式上都是「权重 × 分数」,但作用对象完全不同:第二层的乘子作用在 source / 业务级 上,调的是「这次流量给哪个业务」,业务内部顺序不变;这里的权重作用在 item 级 上,调的是「这条内容本身的 utility 是多少」,因此会直接改变 item 之间的相对顺序。
这类方法的本质,其实更准确地说是:当多目标之间的 trade-off 会随用户和场景变化时,系统可以选择把这种差异隐式学进统一打分函数,也可以显式写成 item 级动态权重。因为只要模型表达能力足够强,特征也覆盖了用户状态和上下文,同一套共享参数同样可以学出 “白天通勤” 和 “晚上休息” 的不同偏好。
如果直接用统一的黑盒模型去学,那么也可以写成 \(U(u,i,x)=f_\theta(u,i,x)\);此时个性化的多目标 trade-off 被隐含在这个 black-box utility function 里。如果写成 \(U(u,i,x)=\sum_k w_k(u,x)\phi_k(i,x)\) 这种形式,那么系统就是把 “当前更看重 CTR、GMV、时长还是留存” 这件事,直接拿到台面上来建模。
通俗一点说,就是:不是 “同一套参数行不行” 的问题,而是 “不同的人、不同的时候,心里那把尺子要不要始终固定不变” 的问题。比如:
- 对高消费用户来说,一条带货内容里的 GMV、CVR 可能更重要;但对轻娱乐用户来说,更重要的可能是时长、完播和消费负担更低的娱乐体验
- 对新用户来说,系统可能更看重留存、稳定体验和低打扰;对老用户来说,则可能更强调点击、转化或者更强的个性化探索
- 即使是同一个用户,白天通勤、晚上休息、周末闲逛,也可能对应三套不同的价值权重:有时更看效率,有时更看放松,有时更看消费决策
因此,显式动态权重的价值,很多时候不在于 “黑盒模型做不到”,而在于它提供了更强的可控性、可解释性和工程上的可分解性。
这个权重学习的方法有很多,工业界常见有三类方案:supervised 端到端融合、contextual bandit、actor-critic。它们看似都在学同一个权重函数 \(w_k(u, x)\),但回答的是三个不同的问题:
| 方法 | 它在回答什么问题 | 反馈结构 | 是否建模” 动作影响未来” | 优化目标 |
|---|---|---|---|---|
| Supervised 端到端融合 | 从历史日志看,什么 \(w_k\) 让最终列表指标最高? | (context, label) 静态对 | 否 | 离线 loss(最终指标的代理) |
| Contextual Bandit | 这一次曝光,选什么 \(w_k\) 使单步 reward 最高?怎么探索新组合? | (context, action, reward) 单步 | 否 | 单步即时 reward |
| Actor-Critic | 这次动作会改变用户后续状态,怎么选 \(w_k\) 使长期累积 reward 最高? | \((s, a, r, s')\) 序列 | 是 | \(\sum_t \gamma^t r_t\) |
通俗一点:
- Supervised 端到端像考完试看答案:拿历史日志当训练集,让模型直接逼近” 最终指标”。简单稳定,但只能在已有数据分布里内插 —— 日志里没出现过的 \(w_k\) 组合就是黑洞
- Contextual Bandit 像每次掷骰子前先估一下哪个骰子更好、掷完立刻调整。和 supervised 的核心差别是它会主动探索;和 RL 的核心差别是它假设每次决策独立,不考虑” 当前动作怎么影响下一刷的用户状态”
- Actor-Critic 把推荐看成 MDP:当前选择会改变下一步用户行为,Critic 估” 从当前状态出发未来还能拿多少 reward”,反传给 Actor 学权重。本质增量是承认动作会改变未来,代价是要稳定的 dense reward 信号、要解决高方差和分布漂移
在实际中,三者并不是替代关系,实际链路里经常叠加使用:主线用 supervised 学一个保底的 \(w_k\);contextual bandit 在小流量做在线探索;actor-critic 用来优化更长期、更累积的目标(如 LTV、session 留存),而不是替换 supervised 学的即时目标。
下面专门展开 actor-critic 在工业里的实际落地情况 —— 它是三类方法里争议最大、也最容易讲偏的一种。
一种比较常见的做法是用 Actor-Critic / DDPG 直接学 \(w_k(u, x)\):Actor 在给定 \((u, x)\) 下输出多目标权重,Critic 评估当前曝光 / 列表的整体 utility,reward 设为 观看时长、完播率、互动信号 等。
在短视频、直播这类反馈密集、即时性强的业务里,这套链路是真正能 work 的:每次曝光都能拿到 dense reward,回流也快,Critic 学得动,Actor 也就有了稳定的梯度信号。 快手、字节、阿里等内容 / 电商平台在多目标融合权重上都有这类实践。但 RL 在这一步要落地,至少要满足两个前提:
- Reward 足够稠密、及时:watch time、完播、停留这类信号每次曝光都有,归因明确;如果换成转化、留存、复购这类稀疏延迟信号,off-policy 评估、归因稳定性都会迅速变差
- Critic 真的能学到列表 / 曝光的整体 utility:否则 Actor 学到的权重很容易只优化某个单点目标(比如时长被放大、互动被牺牲),反而破坏多目标平衡
如果业务的主反馈本身就是稀疏或延迟的(电商点击 - 转化、长留存等),那么 supervised 端到端融合 或 规则 + 分群权重 仍然是性价比更高的选择;contextual bandit 介于两者之间,适合做在线探索补充。
接下来三节进入第二步 ——「这些 item 放在一起怎么组」。
约束重排
在很多业务里,平台并不是 “希望” 满足某些条件,而是 “必须” 满足某些条件,比如:
- 广告 load 上限
- 某类作者最低曝光
- 某些风险内容上限
- 某业务配额
- 类目覆盖要求
这一层之所以必要,恰恰是因为第二层虽然已经在业务级上处理了一部分约束,但还没有真正解决 “这一屏最终能不能这么出” 的问题。
举个例子,如果平台要求 top-10 里广告不能超过 2 条、同作者内容不能连出、某类内容至少保留 1 个坑位,那么:
- 第一层可能会把 3 条广告都打得很高
- 第二层也许已经把广告业务的整体流量控制在合理区间
- 但落到某一次具体请求、某一个具体 top-k 上,系统仍然可能违反规则
所以,这一层之所以能改掉前面的排序,并不是因为它拿到了某个神秘的新特征,而是因为它把前面只在业务级、时间窗口级上粗粒度处理过的约束,推进到了单次请求、最终列表级去显式求解。
也就是说,约束重排真正拿到的增量信息,不是 “这条 item 又多了一个特征”,而是 “这张列表当前已经放了什么、还剩几个坑位、哪些约束已经快撞线了”。这些信息只有在最终 list 组装阶段才是完整的。
这时候,简单的 penalty 或 multiplier 往往不够,因为它只能 “倾向性地” 推动结果,而不能稳定保证约束成立。权重调轻了,约束可能失效;权重调重了,又可能把整体 relevance 打掉。更麻烦的是,很多约束本身还是离散的、位置相关的、相互耦合的,天然就不是单个分数能顺滑表达的。
更自然的做法是把问题写成:
\[ \begin{aligned} \max_{\pi} \quad & U(\pi) \\ \text{s.t.} \quad & C_j(\pi) \le 0 \end{aligned} \]
这里,\(C_j(\pi)\) 表示排列 \(\pi\) 在第 \(j\) 个约束上的违反程度;当 \(C_j(\pi) \le 0\) 时,说明该约束被满足。
这类 constrained re-ranking 的核心不是 “把分再调一调”,而是明确承认:最终排序不是一个纯 relevance 最优化问题,而是一个带硬约束的组合优化问题。
工业上常见的做法,可能是带规则的 greedy / swap,也可能是拉格朗日松弛、最小费用流、ILP 这类更显式的约束优化。形式可以不同,但本质都一样。
因此,约束重排真正补上的,是前面没有解决的 “最后一公里”:不是哪个 item 值更高,也不是哪个业务更该拿量,而是最终给用户的这张列表,能不能既尽量好看,又稳定满足平台必须守住的边界。
列表重排
但即使所有硬约束都满足了,问题也还没有结束。因为一张列表 “合法”,并不等于它就是 “一张好列表”。
这正是列表重排存在的原因:约束重排回答的是 “哪些列表不能出”,而列表重排回答的是 “在所有能出的列表里,哪一张最好”。
如果沿着前面的逻辑继续推,这一层之所以能改掉精排顺序,也一定是因为它拿到了前面没有被充分编码进去的增量信息。只不过这里的增量信息,不再主要是 “硬约束是否满足”,而是 item 和 item 放在一起之后会发生什么。
前面几层没有真正解决的问题,是 item 和 item 之间的相互作用,以及整张列表的整体质量。第一层和 item 级动态权重,本质上仍然是在给单个 item 打分;第二层解决的是业务之间怎么分流量;约束重排解决的是最终结果能不能满足规则。但即使这些都做对了,系统仍然可能产出一张 “每条都不差、放在一起却不太对” 的列表。
比如:
- 五条内容都相关、也都合规,但它们可能高度相似,连在一起就让人疲劳
- 两条内容单看都不错,但前一条已经满足了用户需求,后一条的边际价值会骤降
- 同样一组 item,排在前两位和排在第五、第六位,对用户体验的影响可能完全不同
- 有些组合虽然没有违反任何硬规则,但在节奏、丰富度、探索感上明显更差
这些现象的关键在于:某个 item 的真实价值,已经不再是 “独立于别的 item 而存在” 的了。也就是说,列表重排拿到的增量信息,往往是 “前后文关系”“相邻替代与互补”“位置对满意度的影响”“当前列表已经有多单一或多丰富” 等列表级上下文。它未必是精排完全看不到的原始特征,但往往是精排阶段没有显式建模、也没有显式求解的结构信息。
这类问题也很难被完整写成若干条硬规则,因为 “什么叫一张更好的列表” 往往是一个更软、更整体、也更依赖上下文的问题。
传统 pointwise / pairwise 学习排序,更关注单 item 或 item pair 的相对顺序;而 listwise 方法直接把整张列表当成优化对象。
从学习排序的发展脉络看,From RankNet to LambdaRank to LambdaMART: An Overview 已经系统梳理了 pointwise、pairwise、listwise 之间的差异。真正到了推荐系统的重排阶段,这个思想会更进一步:
既然用户消费的是最终列表,那训练目标就应该尽量贴近最终列表质量,而不是只优化某个单点 surrogate loss。
一个代表性的工作是 Personalized Re-ranking for Recommendation。它在已有候选列表上,用更强的序列建模 / 自注意力结构去建模 item-item 的全局关系,从而实现个性化的列表级重排。
不过严格来说,“listwise 方法” 在工业实现上其实分两种形态,输入都是一张列表,但输出形式完全不同:
| 类型 | 输入 | 输出 | 典型用法 |
|---|---|---|---|
| Listwise scorer/context model | 候选列表 | 每个位置的新分数(再 argsort 出最终序) | PRM 等 contextual re-scoring |
| Listwise evaluator | 一个完整排列 \(\pi\) | 一个标量 \(V_\phi(\pi)\),代表整张列表的整体效用 | Generator-Evaluator 范式 |
前者隐含一个假设:好的列表 ≈ 每个位置都放上下文打分最高的 item,所以它最终输出的仍是 per-item score。后者不做这个假设,它直接对整个排列打总分,因而能捕捉到「整体效用不可分解为各位置之和」的情形。
后者引出了一种更接近 Slate 思想的工业范式 ——Generator-Evaluator:
- Generator:用 beam search、autoregressive 生成、或者轻量 RL policy,产出若干条候选排列
- Evaluator:用一个 listwise utility 模型对每条候选整体打分
- 最终选 \(V_\phi(\pi)\) 最高的那一条作为输出
形式上可以写成:
\[ \pi^\star \approx \arg\max_{\pi \in \text{Gen}(\mathcal{C})} V_\phi(\pi) \]
其中 \(\text{Gen}(\mathcal{C})\) 是 generator 在候选集 \(\mathcal{C}\) 上展开出的有限候选排列集合。本质上,这是在用「有限搜索 + 整体评估」去近似那个本来组合爆炸、不可枚举的 \(\arg\max_\pi U(u,\pi)\)。
这套范式刚好位于 listwise scorer 和 Slate 优化之间:比纯 scorer 强(能直接优化整张列表的效用,而不只是逐位置的 contextual 分数);比 Slate / RL 轻(仍以「一次性产出最终列表」为目标,不需要建模长期反馈与时序动作空间,工程落地难度低很多)。
从方法论上看,无论是 scorer 还是 evaluator,这一类方法的共同关键词都是:显式建模列表上下文,并直接优化整张列表的整体质量。 如果说约束重排更像是 rule-aware optimization,那么列表重排更像是 objective-aware optimization:前者更关心 “别犯错”,后者更关心 “怎样才更好”。
因此,这类方法的必要性就在这里:它解决的不是 “某条内容该不该出”,而是为什么这几条内容放在一起,会比另一种拼法更值得给用户看。
Slate 优化
比 listwise 再往前一步,是把最终列表当成一个 slate 来优化。
这一层之所以还要单独拿出来讲,是因为即使做了列表重排,很多方法本质上仍然是在回答:在已有候选里,哪几条放在一起更好?但 Slate 优化想进一步回答的是:这个列表本身就是一个整体动作,它的价值不只是各位置效果的加总,而是会沿着用户消费过程逐步展开。
一个典型形式是:
\[ U(\pi) = \sum_{t=1}^{K} g_t(u, i_{\pi_t}, \pi_{<t}) \]
这里,\(g_t(u, i_{\pi_t}, \pi_{<t})\) 表示在第 \(t\) 个位置上,把 item \(i_{\pi_t}\) 接在前缀列表 \(\pi_{<t}\) 后面时,对用户 \(u\) 产生的边际价值;\(\pi_{<t}\) 表示位置 \(t\) 之前已经确定的前缀列表。
也就是说,第 \(t\) 个位置的价值,不只取决于当前 item,还取决于前面已经放了什么。
这听起来和前面讲的 listwise 很像,但两者的关注点还是有差别:listwise 更强调 “把整张列表作为训练和优化对象”,而 slate optimization 更强调 “列表是一个有顺序、有反馈、会逐步影响后续行为的决策过程”。
它真正要补上的,是前面还没有彻底解决的两类问题:
第一类,是前序曝光会改变后续 item 的真实价值。比如一条强刺激短视频先出了,后面一条风格相近的视频价值就会被明显稀释;但如果前面先放的是解释型内容,后面再接交易型内容,转化反而可能更高。
第二类,是系统开始关心的不只是这一页当下好不好,而是这页看完之后,用户接下来会怎么走。这时,当前点击已经不再是唯一目标,session 深度、后续停留、后续转化,甚至用户下一次回访,都可能成为 slate 的一部分价值。
所以,这类方法特别适合处理:
- 相似内容连出带来的疲劳
- 内容之间的互补与替代
- 不同位置的展示差异
- 整页体验与 session 级目标
举个更直观的例子:如果前两条内容已经把用户情绪拉得很高,第三条继续上同类强刺激内容,未必最优;这时插入一条承接型、解释型或者轻量商业化内容,整页体验反而可能更好。这个决策的关键,不再只是 “第三条自己值不值钱”,而是 “它接在前两条后面,整张 slate 会变成什么样”。
从这个角度看,Slate 优化的必要性在于:它不只是在做 “列表级排序”,而是在做路径级、过程级的排序决策。
Seq2Slate: Re-ranking and Slate Optimization with RNNs 是这一方向很有代表性的工作。它不再把列表看成若干个独立点,而是把 “生成一个好列表” 本身看成一个序列决策问题。
如果再往长期价值走,问题会进一步演化成 reinforcement learning 版本。一个很有代表性的工作是 SlateQ: A Tractable Decomposition for Reinforcement Learning with Slates。它试图回答的是:
这一次怎么排,不只是影响当前点击,还会影响用户下一步、下下步的行为,那么列表该怎么优化?
从方法论上看,这一类方法的关键词是:把列表看成一个按顺序展开的决策过程,而不只是一个静态结果。
一个常见问题:改序之后,context 变了,要不要重新评估?
到了第三层,一个很自然的问题是:如果重排把序改了,context 也就跟着变了,那是不是又要重新打分、重新排一遍?如果继续重排,context 又会再变一次,这件事会不会掉进死循环?
这个问题是真问题,而且在很多 context model 里确实会出现。比如某个 item 的打分里显式用了 “前面已经出现了多少个同类内容”“前一条是不是同作者”“当前列表丰富度如何” 这类特征,那么只要顺序一改,这些特征就会跟着改。
但工程上通常不会真的让它无限循环下去,因为第三层并不是在求一个 “不断重排直到世界稳定” 的抽象过程,而是在定义一个有限步、可执行的优化协议。常见做法大概有三类:
- 一次性重排:先基于初始候选序构造 context 特征,只 rerank 一次。它不追求严格全局最优,但实现简单、稳定性好,是很多工业系统的常见做法
- 顺序生成:按位置从前到后构造列表。每次确定下一个 item 时,prefix 已经固定,因此 context 也是确定的。这其实就是 greedy / beam search / autoregressive slate generation 的典型范式
- 有限次迭代:先出一版列表,再基于新列表更新 context 特征,然后再 rerank 1~2 轮就停。它本质上是在做近似 fixed-point 求解,但必须人为限制轮数,否则收益未必增加,震荡却很容易增加
所以,严格地说,如果 context 依赖当前顺序,那么 “改序会改变 context” 这件事当然成立;但这并不意味着系统一定会陷入死循环。真正的关键不在于 “要不要一直重排到完全收敛”,而在于:你到底把第三层定义成一个什么样的优化问题,以及愿意为它付出多大的计算和稳定性成本。
很多时候,工业系统并不追求一个数学上完全自洽的全局最优解,而是追求一个足够好的近似解:一次重排能带来多少收益,有限次迭代会不会更稳,顺序生成的计算成本是否可接受。这些,往往比 “理论上是否存在完美收敛点” 更重要。
当然,这也解释了为什么第三层的方法会越来越复杂:约束重排通常最稳定,因为它更多是在可行域内做有限搜索;列表重排次之,因为它开始显式依赖列表上下文;Slate 优化最复杂,因为它不仅让当前列表依赖 prefix,还让目标函数本身依赖后续行为和长期反馈。
延伸方向:让排序本身可微
需要先说明:可微排序并不是和前面三类(约束重排 / 列表重排 / Slate 优化)并列的另一类重排方法,而是一类训练侧工具 —— 它让前面这些重排方法(尤其是 listwise 和 slate)可以更直接地端到端优化” 最终列表质量”。
传统排序算子本身是离散的、不可导的,这会让很多” 真正贴近最终目标” 的优化难以直接做端到端训练。
于是就有了可微排序这一类工作,比如:
- SoftSort: A Continuous Relaxation for the argsort Operator
- Differentiable Ranks and Sorting using Optimal Transport
这类方法的核心目标是:
不再只是优化一个和排序相关的 surrogate loss,而是尽量让训练目标更直接贴近” 最终排序结果本身”。
它们目前更多偏研究和高阶工程场景,但非常有启发意义,因为它说明了一件事:排序这件事本身,也可以成为优化对象,而不只是模型输出之后的固定后处理。
如何判断当前应该优化的层级
这其实是这篇文章最想给出的一个判断框架。
先想第二层
- 各业务内部精排已经相对稳定,但彼此竞争关系混乱
- 某业务总觉得自己 “该出的没出”
- 广告、直播、电商、内容之间总在抢流量
- load、预算、保量、成本约束越来越重
- 线上经常需要控量、提量、保穿透、保营收
这类问题的核心,不是 item 选错了,而是流量没有在多业务之间分好。这时更应该优先思考 calibration、multiplier、pacing、score shading 等第二层方法。
先想第三层
- top-k 里单条内容都不差,但整页体验很差
- 同质化严重,用户容易疲劳
- 多样性、公平性、生态目标越来越重要
- 位置、相邻关系、模板结构明显影响效果
- 需要优化长期行为,而不是只看当前点击
这类问题的核心,不是 “流量给错了业务”,而是最终列表没有拼好。这时更应该优先考虑 constrained re-ranking、listwise / slate optimization 等第三层方法。
直白总结
- 第一层解决:这个东西值多少钱?
- 第二层解决:在约束下,这次流量给谁?
- 第三层解决:整张列表怎么拼才最好?
这三层并不是彼此替代关系,而是一个逐层抬高优化对象的过程。
工程如何演进
很多系统的演进路径,往往不是一开始就把三层全部做到位,而是逐层往上长。
先做好第一层
如果单 item 的价值预估本身就不稳定,那么后面很多复杂机制都会建立在沙地上。这个阶段的重点是把:
- 特征体系
- 标签定义
- 多目标建模
- 个性化能力
先打稳。
再引入第二层
这是很多 feed、内容平台、广告混排系统最自然的一步。因为当系统开始出现:
- 多 source 共存
- 业务保量
- 营收和体验冲突
- 不同业务分数不可直接比较
- 预算和 pacing 需求
第二层几乎就是必需的。
这个阶段里,最先落地、最有性价比的,通常是:
- score calibration
- business-level personalized multiplier
- pacing / score shading
- 平台级治理机制(锚点、统一记账、全局约束)
最后引入第三层
当系统开始强烈感受到下面这些问题时,第三层往往就必须出现:
- top-k 虽然单条都不错,但整页很差
- 同质化严重
- 多样性、公平性、生态目标越来越重要
- 需要优化长期行为,而不是只看当前点击
- 列表内部的上下文关系越来越重要
这个阶段里,更常见的技术路径是:
- 先从 constrained re-ranking 开始(保住硬规则)
- 再往 listwise re-ranking / Generator-Evaluator 走(显式建模列表整体效用)
- 更复杂的场景再考虑 slate optimization、bandit、RL
换句话说,工程里通常不是 “一上来就全量 RL”,而是沿着约束更强、目标更复杂、优化对象更整体的方向逐步演进。
总结
这篇文章真正想回答的,不是 “为什么每个用户的排序权重不一样” 这种表面命题,而是:
当第一层已经能够较好学习用户对单个 item 的偏好之后,平台为什么还必须引入混排层和重排层?它们分别在弥补什么,又分别在优化什么?
完整答案先用一张对照表罗列:
| 层级 | 优化对象 | 主要方法 | 这一层的增量信息 | 不解决(边界) |
|---|---|---|---|---|
| 第一层 个性化精排 | 单 item 价值 \(s(u,i,x)\) | 单目标 / 多目标加权精排(个性化隐式学进参数) | 用户 - 内容匹配 | 业务间流量分配;列表内部相互作用 |
| 第二层 个性化混排 | 业务级流量分配(受约束) | 分数校准 → 动态调权 → Score Shading / Pacing | 业务量纲对齐;平台约束;pacing 状态 | 业务内部哪条更该出;列表整体组合质量 |
| 第三层 全局重排 | 整张列表组合质量 \(\pi^\star\) | item 级权重 → 约束重排 → 列表重排(含 Generator-Evaluator)→ Slate | 列表上下文;可行域;前序 - 后序依赖;长期反馈 | 上游候选质量本身 |
把这张表压缩成两句话:
- 第二层不是在 “修一个不准的分数”,而是在做受约束的资源分配与在线控制 —— 因为流量本身是稀缺的、有约束的、动态的
- 第三层也不是 “多做一步后处理”,而是在做列表级的组合优化 —— 因为用户最终消费的是整张列表,而不是若干个彼此独立的 item
这不是工程上的冗余,而是问题本身决定的。
如果后面继续展开,这篇文章真正值得深入的,也正是这两条线:
- 不改变精排序的个性化混排:如何通过 calibration、multiplier、pacing、score shading 在多业务竞争中实现可控的个性化分发
- 允许直接改精排序的全局重排:如何通过 listwise / slate optimization、约束优化和长期价值建模,把个性化从单 item 推进到整张列表
参考文献
- Deep Landscape Forecasting for Real-time Bidding Advertising
- 从 Bid Shading 到 Score Shading:混排优化的建模、控制与博弈
- Personalized Re-ranking for Recommendation
- Seq2Slate: Re-ranking and Slate Optimization with RNNs
- SlateQ: A Tractable Decomposition for Reinforcement Learning with Slates
- SoftSort: A Continuous Relaxation for the argsort Operator
- Differentiable Ranks and Sorting using Optimal Transport
- From RankNet to LambdaRank to LambdaMART: An Overview