Modeling Action Sequences with word2vec and CNN/RNN
This article describes how to model action sequences using word2vec and CNN/RNN. I verified this approach in a recent competition—it indeed showed some effectiveness, achieving 0.87 accuracy in binary classification. This article mainly introduces the specific steps of this method, illustrated with the competition and code.
The competition mentioned here is the ongoing Premium Travel Service Order Prediction. The task is to predict whether a user’s next order will be a premium service based on user personal information, behavior information, and order information. The method described in this article only uses user behavior information. The main idea is: Convert each action to an embedding representation through word2vec, then convert the action sequence to an embedding sequence and use it as input for CNN/RNN. Below, I will introduce the three parts: obtaining action embeddings through word2vec, using embeddings as CNN input, and using embeddings as RNN input.
Obtaining Action Embeddings with word2vec
word2vec is a well-known unsupervised algorithm, originally proposed in NLP. It can construct word vectors through relationships between words, and then obtain semantic information of words through word vectors, such as word similarity. Applying word2vec to action sequences was inspired by this answer on Zhihu. Since word2vec can mine relationship information between elements in a sequence, if we treat each action as a word and obtain embedding representations of each action through word2vec, these embeddings will have certain correlation degrees. Then converting the action sequence to an embedding sequence and using it as input for CNN or RNN can mine information from the entire sequence.
The method for training action embeddings is the same as training word embeddings—treat each action of each user as a word and the action sequence as an article. I used gensim for training. The training code is simple: set embedding dimension to 300, and each line in filter_texts is a user’s action sequence with actions separated by spaces.1
2
3from gensim.models import word2vec
vector_length = 300
model = word2vec.Word2Vec(filter_texts, size = vector_length, window=2, workers=4)
Since there are only 9 action types (1~9), meaning 9 different words, we can store these 9 action embeddings in a np.ndarray, then use it as initial weights for the embedding layer before CNN/RNN. Note that action 0 is also added here, because CNN requires consistent input length, so for sequences shorter than the required length, we need to pad 0 at the front (padding with other non-known actions also works). The code is as follows:1
2
3
4import numpy as np
embedding_matrix = np.zeros((10, vector_length))
for i in range(1, 10):
embedding_matrix[i] = model.wv[str(i)]
Modeling Action Sequences with CNN
The CNN model used is the classic TextCNN, with the model structure shown below: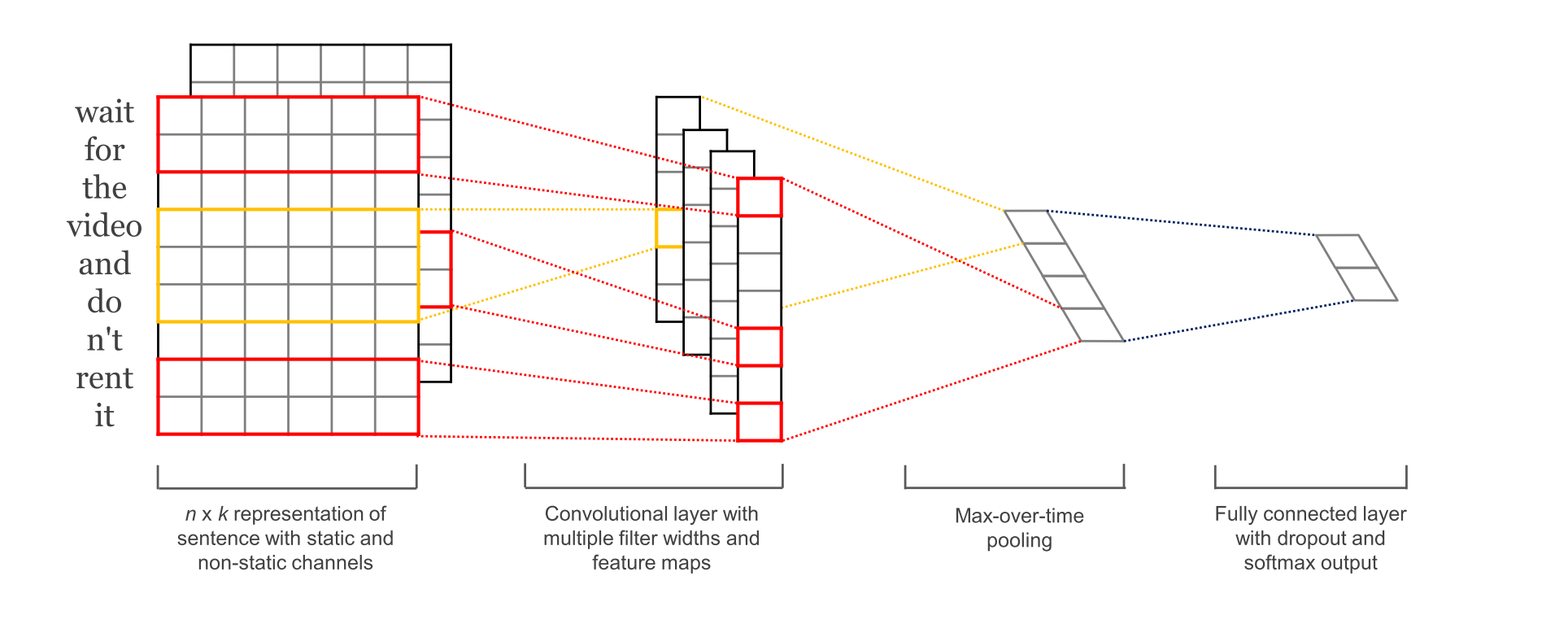
Here I implement it through Keras, with the specific code below.
First, we need to process sequences so all sequences have the same length. I chose length 50. The specific code is below; x_original is of type list[list[int]], representing all action sequences of all users. For sequences longer than max_len, take the 50 most recent actions from the end; for shorter ones, pad 0 at the front.1
2
3
4
5from keras.preprocessing import sequence
max_len = 50
x_train = sequence.pad_sequences(x_original, maxlen=max_len)
y_train = np.array(y_original)
print(x_train.shape, y_train.shape)
Then initialize the embedding layer with the previously obtained embedding_matrix:1
2
3
4
5
6
7
8
9
10from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Input, MaxPooling1D, Convolution1D, Embedding, BatchNormalization, Activation
from keras.layers.merge import Concatenate
from keras import optimizers
embedding_layer = Embedding(input_dim=embedding_matrix.shape[0],
output_dim = embedding_dim,
weights=[embedding_matrix],
input_length=max_len,
trainable=True)
Then build the model and train. Here I used four convolutional kernels with different strides: 2, 3, 5, 8. Compared to the original TextCNN, I used two convolutional layers (tested to be better than one layer on this task), and expanded the fully connected layer to three layers. The specific code is:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44NUM_EPOCHS = 100
BATCH_SIZE = 64
DROP_PORB = (0.5, 0.8)
NUM_FILTERS = (64, 32)
FILTER_SIZES = (2, 3, 5, 8)
HIDDEN_DIMS = 1024
FEATURE_DIMS = 256
ACTIVE_FUNC = 'relu'
sequence_input = Input(shape=(max_len, ), dtype='int32')
embedded_seq = embedding_layer(sequence_input)
# Convolutional block
conv_blocks = []
for size in FILTER_SIZES:
conv = Convolution1D(filters=NUM_FILTERS[0],
kernel_size=size,
padding="valid",
activation=ACTIVE_FUNC,
strides=1)(embedded_seq)
conv = Convolution1D(filters=NUM_FILTERS[1],
kernel_size=2,
padding="valid",
activation=ACTIVE_FUNC,
strides=1)(conv)
conv = Flatten()(conv)
conv_blocks.append(conv)
model_tmp = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
model_tmp = Dropout(DROP_PORB[1])(model_tmp)
model_tmp = Dense(HIDDEN_DIMS, activation=ACTIVE_FUNC)(model_tmp)
model_tmp = Dropout(DROP_PORB[0])(model_tmp)
model_tmp = Dense(FEATURE_DIMS, activation=ACTIVE_FUNC)(model_tmp)
model_tmp = Dropout(DROP_PORB[0])(model_tmp)
model_output = Dense(1, activation="sigmoid")(model_tmp)
model = Model(sequence_input, model_output)
opti = optimizers.SGD(lr = 0.01, momentum=0.8, decay=0.0001)
model.compile(loss='binary_crossentropy',
optimizer = opti,
metrics=['binary_accuracy'])
model.fit(x_tra, y_tra, batch_size = BATCH_SIZE, validation_data = (x_val, y_val))
Since the final metric required is AUC, but Keras doesn’t provide it, and there’s some gap between accuracy and AUC, we can calculate AUC through sklearn after each epoch:1
2
3
4
5
6from sklearn import metrics
for i in range(NUM_EPOCHS):
model.fit(x_tra, y_tra, batch_size = BATCH_SIZE, validation_data = (x_val, y_val))
y_pred = model.predict(x_val)
val_auc = metrics.roc_auc_score(y_val, y_pred)
print('val_auc:{0:5f}'.format(val_auc))
This method’s final accuracy is about 0.86, AUC about 0.84.
Modeling Action Sequences with RNN
Modeling with RNN is similar to CNN. The difference is that RNN can accept inputs of different lengths, but according to this explanation, padding is still needed for inputs, but RNN will automatically ignore them.
Therefore, the data preprocessing and embedding layer construction code is basically the same as CNN. Here I only give the model building code. The model is simple: first map the input through the embedding layer, then use it as input for RNN built with LSTM/GRU as basic units, and finally classify through sigmoid. The specific code is:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# RNNs are tricky. Choice of batch size is important,
# choice of loss and optimizer is critical, etc.
model = Sequential()
model.add(embedding_layer)
model.add(Bidirectional(LSTM(256, dropout=0.2, recurrent_dropout=0.2)))
# model.add(LSTM(256))
# model.add(Bidirectional(GRU(256)))
model.add(Dense(1, activation='sigmoid'))
opti = optimizers.SGD(lr = 0.01, momentum=0.8, decay=0.0001)
# try using different optimizers and different optimizer configs
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
The final result from RNN is slightly better than CNN: accuracy about 0.87, AUC about 0.85. But training is very slow, and parameters are very tricky, requiring fine tuning. I didn’t fine-tune parameters carefully here, and the model isn’t very complex—there should be room for improvement.
In summary, this article provides an approach for modeling dynamic sequences: convert action sequences through word2vec to get embedding representations of each action, then convert action sequences to embedding sequences and use as input for CNN/RNN. Hope this can serve as a starting point—if you have better ideas, welcome to discuss.