Basic Ideas and Code Implementation of Stacking
This article introduces stacking, an ensemble learning method in machine learning. First, I explain the idea behind stacking, then provide an implementation approach that can easily extend the base models in stacking.
Basic Idea of Stacking
Stacking is using the output results of a series of models (also called base models) as new features input to other models. This method implements model layering: the first layer’s model outputs serve as input to the second layer model, the second layer’s outputs serve as input to the third layer, and so on. The last layer’s output is the final result. This article uses two-layer stacking as an example.
The idea of stacking is easy to understand. Take paper review as an example: first, three reviewers review the paper separately, then return their review opinions to the editor-in-chief. The editor-in-chief combines the reviewers’ opinions and makes the final decision on whether to accept. Corresponding to stacking, the three reviewers are the first-layer models, their outputs (review opinions) serve as input to the second-layer model (editor-in-chief), which then gives the final result.
The idea of stacking is straightforward, but in implementation, we must ensure no leakage occurs—meaning for each training sample, the base model cannot use that sample for training when outputting its result. Otherwise, we’d be using the sample for both training and testing, causing overfitting in final prediction: good performance on training set validation, but poor on test set.
To solve the leakage problem, we need to output results for different sample parts through K-Fold method. Taking 5-Fold as an example:
- Divide data into 5 parts; each time use 1 part as validation set, the other 4 as training set—can train 5 models total.
- For the training set: each time a model is trained, use it to predict the validation set that wasn’t used for training. The prediction results become the second-layer input for those validation samples. After iterating 5 times, each training sample gets its output as second-layer input.
- For the test set: each time a model is trained, use it to predict the test set. Each test sample will have 5 outputs—average them as the second-layer input.
The above process is illustrated below: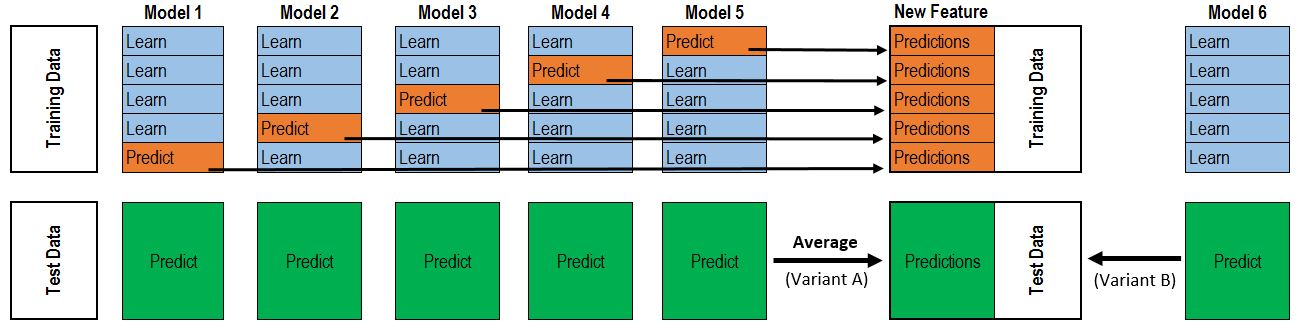
Besides this, when using stacking or ensemble methods, note two points:
- Base models should have minimal correlation to complement each other’s strengths.
- Base models shouldn’t have too large performance gap—poor models will drag down results.
Code Implementation
Since each base model in stacking needs cross-training with data splitting, writing this code for each model would be very redundant. Here I provide a simple approach for implementing stacking.
The approach: first implement a parent class with cross-training method (same for all models), then declare two methods: train and predict. Since different base models have different implementations, these need to be implemented in subclasses. Below is the Python implementation:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import numpy as np
from sklearn.model_selection import KFold
class BasicModel(object):
"""Parent class of basic models"""
def train(self, x_train, y_train, x_val, y_val):
"""return a trained model and eval metric of validation data"""
pass
def predict(self, model, x_test):
"""return the predicted result of test data"""
pass
def get_oof(self, x_train, y_train, x_test, n_folds = 5):
"""K-fold stacking"""
num_train, num_test = x_train.shape[0], x_test.shape[0]
oof_train = np.zeros((num_train,))
oof_test = np.zeros((num_test,))
oof_test_all_fold = np.zeros((num_test, n_folds))
aucs = []
KF = KFold(n_splits = n_folds, random_state=2017)
for i, (train_index, val_index) in enumerate(KF.split(x_train)):
print('{0} fold, train {1}, val {2}'.format(i,
len(train_index),
len(val_index)))
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_val, y_val = x_train[val_index], y_train[val_index]
model, auc = self.train(x_tra, y_tra, x_val, y_val)
aucs.append(auc)
oof_train[val_index] = self.predict(model, x_val)
oof_test_all_fold[:, i] = self.predict(model, x_test)
oof_test = np.mean(oof_test_all_fold, axis=1)
print('all aucs {0}, average {1}'.format(aucs, np.mean(aucs)))
return oof_train, oof_test
The most important part above is the get_oof method for K-fold training. This method returns the prediction results on training and test sets from the base model—two 1D vectors with lengths equal to the number of training and test samples.
Below is stacking with two base models: xgboost and lightgbm. Both only need to implement train and predict methods from BasicModel.
First base model:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import xgboost as xgb
class XGBClassifier(BasicModel):
def __init__(self):
"""set parameters"""
self.num_rounds=1000
self.early_stopping_rounds = 15
self.params = {
'objective': 'binary:logistic',
'eta': 0.1,
'max_depth': 8,
'eval_metric': 'auc',
'seed': 0,
'silent' : 0
}
def train(self, x_train, y_train, x_val, y_val):
print('train with xgb model')
xgbtrain = xgb.DMatrix(x_train, y_train)
xgbval = xgb.DMatrix(x_val, y_val)
watchlist = [(xgbtrain,'train'), (xgbval, 'val')]
model = xgb.train(self.params,
xgbtrain,
self.num_rounds)
watchlist,
early_stopping_rounds = self.early_stopping_rounds)
return model, float(model.eval(xgbval).split()[1].split(':')[1])
def predict(self, model, x_test):
print('test with xgb model')
xgbtest = xgb.DMatrix(x_test)
return model.predict(xgbtest)
Second base model:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import lightgbm as lgb
class LGBClassifier(BasicModel):
def __init__(self):
self.num_boost_round = 2000
self.early_stopping_rounds = 15
self.params = {
'task': 'train',
'boosting_type': 'dart',
'objective': 'binary',
'metric': {'auc', 'binary_logloss'},
'num_leaves': 80,
'learning_rate': 0.05,
# 'scale_pos_weight': 1.5,
'feature_fraction': 0.5,
'bagging_fraction': 1,
'bagging_freq': 5,
'max_bin': 300,
'is_unbalance': True,
'lambda_l2': 5.0,
'verbose' : -1
}
def train(self, x_train, y_train, x_val, y_val):
print('train with lgb model')
lgbtrain = lgb.Dataset(x_train, y_train)
lgbval = lgb.Dataset(x_val, y_val)
model = lgb.train(self.params,
lgbtrain,
valid_sets = lgbval,
verbose_eval = self.num_boost_round,
num_boost_round = self.num_boost_round)
early_stopping_rounds = self.early_stopping_rounds)
return model, model.best_score['valid_0']['auc']
def predict(self, model, x_test):
print('test with lgb model')
return model.predict(x_test, num_iteration=model.best_iteration)
The next step is using these two base models’ outputs as input to the second-layer model. Here I use LogisticsRegression as the second-layer model.
First, reshape and concatenate each base model’s output to proper size:1
2
3
4
5
6
7
8
9
10
11lgb_classifier = LGBClassifier()
lgb_oof_train, lgb_oof_test = lgb_classifier.get_oof(x_train, y_train, x_test)
xgb_classifier = XGBClassifier()
xgb_oof_train, xgb_oof_test = xgb_classifier.get_oof(x_train, y_train, x_test)
input_train = [xgb_oof_train, lgb_oof_train]
input_test = [xgb_oof_test, lgb_oof_test]
stacked_train = np.concatenate([f.reshape(-1, 1) for f in input_train], axis=1)
stacked_test = np.concatenate([f.reshape(-1, 1) for f in input_test], axis=1)
Then train and predict with the second-layer model:1
2
3
4
5from sklearn.linear_model import LinearRegression
final_model = LinearRegression()
final_model.fit(stacked_train, y_train)
test_prediction = final_model.predict(stacked_test)
The complete code is available at:
https://github.com/WuLC/MachineLearningAlgorithm/blob/master/python/Stacking.py
If there are any errors or omissions, feedback is welcome.
References:
Introduction to Ensembling/Stacking in Python 如何在 Kaggle 首战中进入前 10%