Distributed Machine Learning (1) - A New Era
This distributed machine learning series was shared by Wang Yi, covering distributed machine learning. As the author mentioned in the sharing, distributed machine learning differs significantly from the machine learning we commonly hear about today, so many views in the sharing run counter to what we learned from textbooks. The author has rich experience in this area—although it’s a three-year-old sharing, some technologies may have changed, but some views still have reference value.
I have doubts about some views in the sharing. Here I record them according to the author’s expression—perhaps only after I start working will I have the opportunity to verify their correctness.
This article mainly introduces some important concepts in distributed machine learning: real Internet data follows a long-tail distribution, “big is more important than fast,” and not blindly applying a framework. The corresponding video is here (requires VPN).
Machine Learning vs Distributed Machine Learning
Machine learning emphasizes mathematical knowledge, while distributed machine learning focuses more on engineering techniques. General machine learning models assume data follows an exponential family distribution, but real data follows a long-tail distribution. Distributed machine learning needs to model this long-tail data—detailed later.
Long Tail Effect
According to Wikipedia, “long tail” refers to the phenomenon where products or services with small sales volume but many types, which were originally not valued, accumulate total revenue exceeding mainstream products due to their huge total quantity. In the Internet domain, the long tail effect is particularly significant. The yellow part in the figure below is the long tail—we need to pay attention to long-tail data because the volume isn’t small and contains important value.
Take Internet advertising as an example: the long tail phenomenon means there are many low-frequency search terms that most people don’t know. For instance, searching “红酒木瓜汤” (red wine papaya soup) shouldn’t show ads for red wine, papaya, or soup—this is a breast enhancement product, a long-tail search term.
Another example: the figure below shows some frequent itemsets mined from Delicious webpages. The leftmost is the frequent itemset, the rightmost shows its occurrence count across all webpages (hundreds of millions). We can see these are long-tail data, yet they all have specific meanings.
Big is More Important than Fast
Parallel computing focuses on being faster, while distributed machine learning focuses on being bigger. Since data is long-tail, to cover long-tail data, the priority is handling large amounts of data first.
Before proceeding, let’s clarify some concepts. Message Passing and MapReduce are two famous parallel programming paradigms—meaning there are specifications for how to write parallel programs. You just need to insert some code into pre-provided frameworks to get your own parallel program. A framework for the Message Passing paradigm is called MPI. The framework for the MapReduce paradigm is also called MapReduce. MPICH2 and Apache Hadoop are implementations of MPI and MapReduce frameworks respectively.
For frameworks, an important point is supporting Fault Recovery—simply put, supporting rollback of failed tasks. MPI cannot implement Fault Recovery because MPI allows processes to communicate with each other at any time. If a process crashes, we can ask the distributed operating system to restart it. But to let this “reborn” process obtain its “past life’s” state, we need it to start from initial state and receive all messages its past life received. This requires all processes that sent messages to the past life to be restarted. And these processes need to receive all messages their past lives received. This data dependency means: all processes must restart, so the job must start over.
Although it’s hard to make MPI framework support fault recovery, can we make MPI-based application systems support it? In principle yes—the simplest approach is checkpoint—periodically writing all messages received by all processes to a distributed file system (like HDFS). Or more directly: writing process state and job state to HDFS.
Opposite to MPI is MapReduce. MPI allows inter-process communication at any time, while MapReduce only allows communication during shuffle between Map and Reduce. MPI can parallelize almost all machine learning algorithms, while some complex algorithms cannot be implemented via MapReduce.
Some Pitfalls
Here are some pitfalls the author thinks we should avoid. I’ll elaborate on a few.
De-noise Data
“Noise data” here refers to low-frequency data. Removing such data is like cutting off the long tail, losing most useful data.
Why can’t we cut off the long tail? The author explains in Mathematical Models Describing Long Tail Data:
The diverse data types covered by that long tail represent all aspects of life on the Internet. Understanding these aspects is important. For example, why do Baidu and Google make so much money? Because of Internet advertising revenue. In traditional advertising, only wealthy big enterprises can contact advertising agencies—a bunch of high-rollers in suits discuss and compete for TV or print media advertising opportunities. In Internet advertising, anyone can log into a website to place ads, even with daily budgets of just tens of RMB. This way, small business owners like Liu Bei weaving mats and selling shoes can promote their own products. And search engine users have diverse interests—from universally beloved celebrities to niche demands like “红酒木瓜汤” (a breast enhancement formula, should show breast enhancement ads) or “苹果大尺度” (searching for the movie “Apple” starring Fan Bingbing). Intelligently matching various demands with various ads creates the revolutionary power of Internet advertising. Understanding various niche demands and long-tail intentions is crucial.
Parallelize Models in Papers and Textbooks
Models in textbooks or papers cannot be applied to big data environments because textbook models assume data follows exponential family distribution (Exponential family), while real data follows long-tail distribution (Long tail).
What happens when using exponential family distribution models to fit long-tail distributed data? The long tail gets cut off. For example, with pLSA and LDA topic models, if you remove low-frequency words from training corpus, you’ll find the trained semantics are similar to using full data. In other words, pLSA and LDA training algorithms don’t care about low-frequency data.
Currently, most mathematical models assume exponential family distribution: LDA and PLSA in topic models have exponential family prior and posterior distributions; SVD and similar matrix factorization methods assume Gaussian distribution; Linear Regression and similar methods also tend to optimize abundant samples.
Since this is the case, why do these models assume exponential family distribution? The author explains in Mathematical Models Describing Long Tail Data:
This is really 不得已 (unavoidable). Exponential family distributions are mathematically very convenient elements. Take LDA—it uses the conjugacy of Dirichlet and multinomial distributions, allowing model parameters to be integrated out during computation. This is why ad-hoc parallel algorithms like AD - LDA—methods that don’t work well on other models—work well on LDA. In other words, for computational convenience, we cover our ears and steal the bell by assuming exponential family distribution.
Therefore, to model long tails, the author mentions Dirichlet process and Pitman-Yor process as possible new directions.
Use Existing Frameworks
MPI and MapReduce are two extremes. Between them are frameworks like Pregel (Google) and Spark, whose main idea is doing checkpoint on disk to enable flexible communication and effective recovery.
Algorithms like PageRank work on these frameworks, but for algorithms with heavy communication like LDA, checkpointing requires disk writes, causing buffer overflow and out of memory. Therefore, no single general computing framework can solve all problems.
Here are some widely used open-source frameworks. Note that when designing machine learning systems, you need to weigh effectiveness vs. cost and choose or even develop appropriate frameworks:
- MPI
- MapReduce
- Pregel
- GraphLab
- Spark
Another issue to note: don’t mix computing frameworks with distributed operating systems. Hadoop 1.0’s design mixed cluster management system with distributed computing framework, which was very messy. Hence in 2.0, Yarn emerged as a distributed operating system specifically for task scheduling.
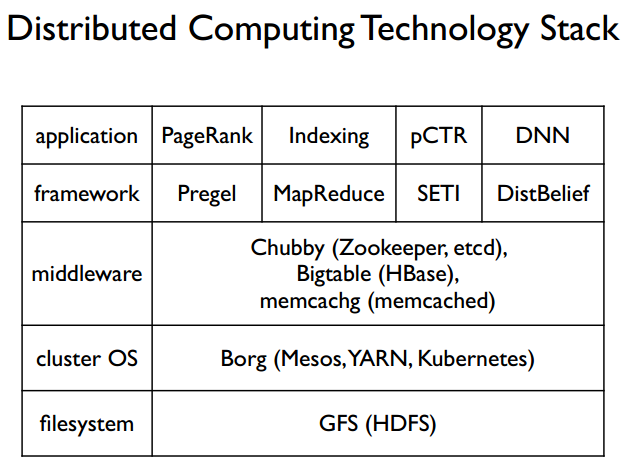
Distributed Machine Learning Tech Stack
The final figure shows the distributed tech stack, from bottom to top: distributed file system, distributed operating system, middleware, distributed computing frameworks, and applications built on this distributed system. Since this is from a 2015 video, technologies have changed—at least for DNN frameworks, TensorFlow, PyTorch, Caffe, MXNet are now mainstream.
References
Distributed Machine Learning Series - 00 A New Era Stories of Distributed Machine Learning: Evaluation Criteria Stories of Distributed Machine Learning: pLSA and MPI Mathematical Models Describing Long Tail Data