Distributed Machine Learning (2) - Infrequent Pattern Mining using MapReduce
This lecture mainly introduces the classic method for mining frequent itemsets: FP-growth, and how to implement this algorithm through MapReduce. The MapReduce-implemented FP-growth is also called PFP, which can mine not only frequent itemsets but also infrequent itemsets. The original video is here (requires VPN).
Frequent Itemset Mining
Frequent Itemset Mining refers to finding itemsets that appear together frequently. A classic example is “beer and diapers.” The figure below shows some basic concepts:
- Transaction: Each row is a Transaction, representing an order
- Item & ItemSet: Each Transaction contains several Items (products in the order); any number of Items can form an ItemSet
- Support: The occurrence count of an ItemSet
There are two basic methods for mining frequent itemsets: Apriori and FP-growth. Apriori requires multiple scans of the original data, making it slow. I won’t elaborate on it here—see this article for details.
Here I describe the FP-growth algorithm, which builds a prefix tree and only needs to traverse the original data twice. First, I’ll introduce the algorithm’s process, then how to implement it with MapReduce.
FP-growth Algorithm
FP-growth first needs to build an FP-tree, which is a prefix tree. The construction method is the same as a regular prefix tree, but before construction, items in each transaction must be sorted according to a unified rule (can be by item frequency or item name—as long as it’s consistent across transactions).
Since original items are already sorted by name, we can directly build the FP-tree using the prefix tree method. The figure below shows the construction result after reading the first two records: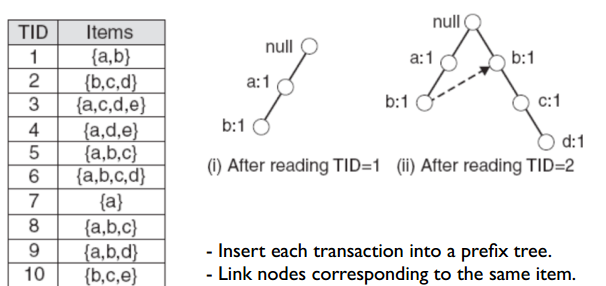
Following this method, we can build the entire FP-tree as shown below: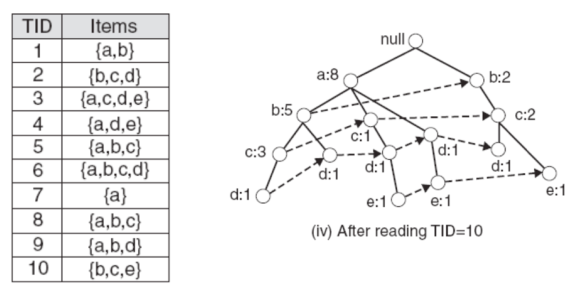
Note: The above process omits one step—before constructing the FP-tree, we need to set a min-support value. This value means an item must appear at least min-support times; if less, remove that item from all transactions, then construct the prefix tree using the above method.
The reason: (1) items with low frequency in itemsets are considered low relevance; (2) when input is large, the constructed tree will also be large, so we can remove infrequent items by setting a threshold. But from what we discussed earlier, this actually removes some long-tail data.
After constructing the FP-tree, to mine frequent itemsets, we first need to specify an item, then mine frequent itemsets related to that item. Mining frequent itemsets related to an item requires constructing a Conditional FP-tree—a FP-tree composed of all transactions related to that item. For example, to mine frequent itemsets related to item ‘e’, the Conditional FP-tree construction process is:
First, find all branches with ‘e’ as leaf node to form a tree, as shown in (a) below: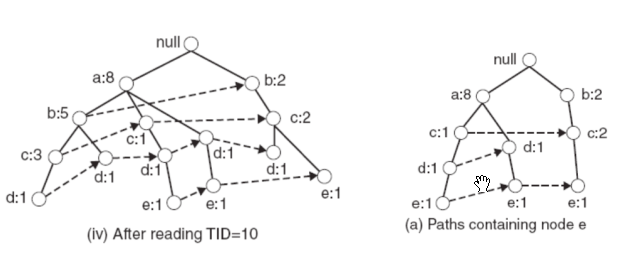
Next, update parent node counts to the sum of child node counts, and remove the ‘e’ leaf node: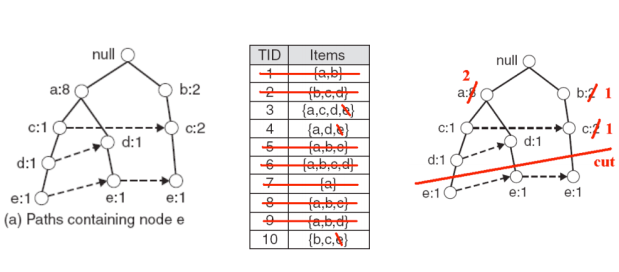
In this process, we need to remove items whose support doesn’t meet min-support. Let min-support be 2—since ‘b’ in the above figure has support of only 1, we need to remove ‘b’: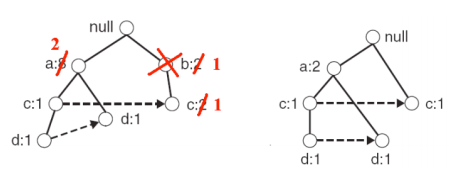
After constructing ‘e’s conditional FP-tree, we just need to mine frequent itemsets in the conditional FP-tree and append ’e’ to all frequent itemsets. For example, if frequent itemsets mined from the conditional FP-tree are {a:2, d:2} and {c:2}, then frequent itemsets for ‘e’ are {a:2, d:2, e:2} and {c:2, e:2}. This is actually solving a recursive problem.
MapReduce Implementation of FP-growth
Generally, the original data for mining frequent itemsets is quite large, so the constructed FP-tree will also be large. When memory cannot store the FP-tree, one solution is to increase min-support to reduce FP-tree size, but based on the long-tail effect we discussed earlier, this will cut off long-tail data.
Another method is to implement the algorithm in a distributed way. Distributed implementation allows supporting smaller min-support when building FP-tree, thus able to mine infrequent itemsets. The distributed framework used here is MapReduce—below are the implementation details.
First, let’s introduce the MapReduce programming paradigm. Input, intermediate results, and output are all key-value pairs. The intermediate shuffling process aims to hand pairs with the same key to the same worker.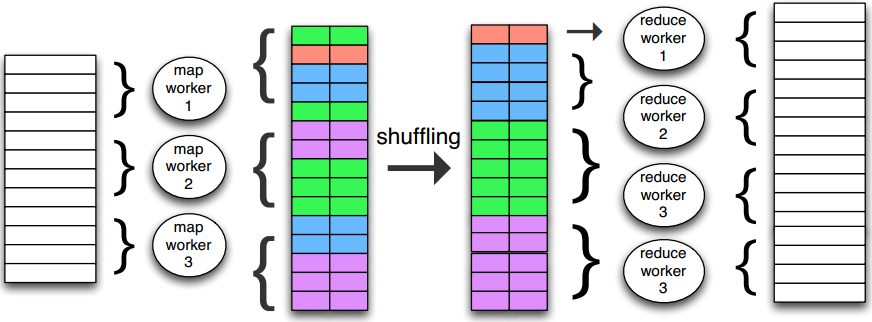
In implementation, the shuffling process can decide which worker handles a kv pair by hashing the key and taking modulo (number of workers).
Data transmission is through distributed file systems—requiring repeated disk writes for data transfer, which is why MapReduce cannot be fast.
From above, finding frequent itemsets for item A and item B are independent tasks—just need to find conditional FP-trees for item A and item B respectively, so they can be handled by two workers separately.
For FP-growth implemented through MapReduce, each map + reduce process outputs the conditional FP-tree for an item. The figure below shows the map process, which outputs conditional transactions for each item from transactions:
The map input on the left is the original transactions. After sorting and filtering out infrequent items, we get conditional transactions for each item as map output, which goes into the reduce process. The reduce process is shown below—reduce aggregates conditional transactions with the same key (item), then builds the conditional FP-tree for that item.
After getting the item’s conditional FP-tree, we can perform the same MapReduce operation on this conditional FP-tree. Therefore, each recursion of the original FP-growth algorithm is one MapReduce Job here.
The implementation above is actually the PFP (Parallel FP-growth) algorithm, which has corresponding implementation in the Spark framework that can be called directly.
Finally, note that while PFP can mine infrequent itemsets—the tail part of long-tail data—it cannot judge which itemsets in these infrequent itemsets are valid and which are noise.
In summary, this article mainly introduced the FP-growth algorithm for frequent itemset mining and how to implement it through MapReduce. The MapReduce version can support smaller min-support, thus able to mine infrequent itemsets—the tail part of long-tail data—but this method cannot judge which infrequent itemsets are valid.
References
Distributed Machine Learning Series - 01 Infrequent Pattern Mining using MapReduce FP Tree Algorithm Principle Summary