Distributed Machine Learning (3) - Application Driven
This article mainly introduces a common technology behind several important Internet businesses (online advertising, recommendation systems, search engines): semantic understanding, and various methods to implement it, including matrix factorization, topic models, etc. The original video is here (requires VPN).
Businesses Supported by Semantic Understanding
Online Advertising
The author uses the Peacock system developed at Tencent as an example to introduce the semantic understanding technology needed for online advertising. Below is the semantic understanding result returned by the Peacock system for the query keyword “红酒木瓜汤” (red wine papaya soup):
The topics at the bottom are inferred from the query, each row is a topic. “weight” is the probability that the query belongs to that topic; “topic_words” are words in that topic, sorted by relevance to the query from high to low.
If we generate the same topics distribution from advertisers’ ad descriptions, we can match queries with ads. The Peacock system is based on LDA (Latent Dirichlet allocation), detailed in the paper Peacock: Learning Long-Tail Topic Features for Industrial Applications.
Besides user queries, we can also derive topic distribution from content users browse, then recommend associated ads based on browsing content.
Recommendation Systems
The most familiar algorithm in recommendation systems is collaborative filtering, which measures user similarity through user vectors in the users-items matrix, and item similarity through item vectors. See this article for details. However, collaborative filtering is powerless in the following situation: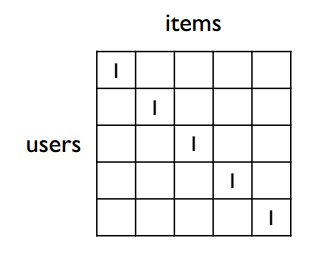
The situation shown above is that different user vectors have no common items, so user vector similarity cannot be calculated. Real data is often very sparse—different users have few intersecting items—so collaborative filtering is almost no longer used in recommendation systems.
So how can we apply semantic understanding to recommendation systems? As shown below, if we divide the original users-items matrix into two large topics, each user and each item can be mapped to a topic vector. Then by comparing topic vectors, we can compare the similarity of two users or items: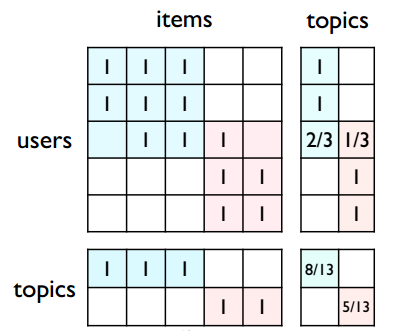
In practice, matrix factorization methods are more commonly used—we don’t need to pre-partition the users-items matrix, but get topic vectors for each user and item through matrix factorization. Common methods include SVD, NMF, etc.
Search Engines
Search engines are similar to online advertising—both return related content based on user queries. The text in the figure below can be understood as user search keywords and page keywords: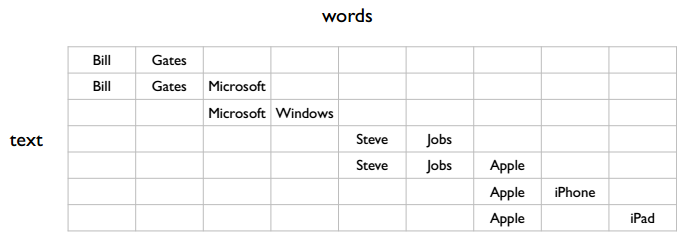
There are several topics in the figure. The simplest is two: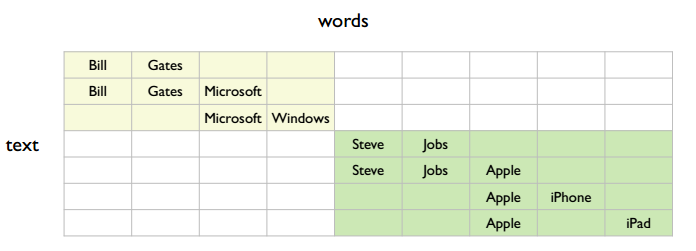
But it could also be four: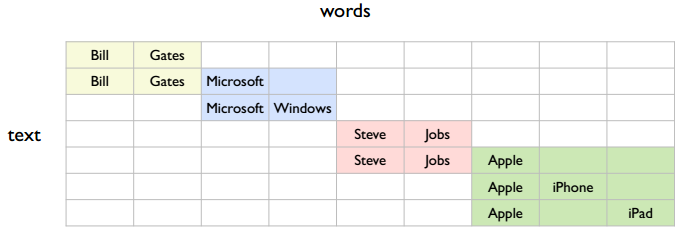
So an important question: what granularity of topics should we learn? The author’s view is that learning smaller-grained semantics has more benefits. For example, with the first coarse-grained semantic partition, row 1 and row 3 are related; with the second fine-grained partition, row 1 and row 3 have no direct connection, but can be connected through row 2. That is, finer-grained semantics can accomplish what coarser-grained semantics can, but not vice versa. Considering search precision, fine-grained semantics definitely gives more precise search results than coarse-grained semantics.
Methods for Implementing Semantic Understanding
Methods for implementing semantic understanding can be divided into unsupervised and supervised categories. Supervised is essentially classification (classifying users or items), but supervised requires manually labeled data and it’s hard to determine the exact number of categories. So in practice, unsupervised methods are often used. Below are some unsupervised methods:
Frequent itemset mining was covered in the previous lecture. In practice, frequent itemset mining and collaborative filtering are not used much.
LSA (Latent semantic analysis) is essentially SVD decomposition on a text matrix (each row is a document, each column is a word). The resulting U and V matrices contain topic vectors for each document or word. Other matrix factorization methods follow this same approach.
NMF (Non-negative matrix factorization) is constrained SVD—elements in the decomposed matrices must be positive.
pLSA (Probabilistic latent semantic analysis) adds probability to LSA, making results interpretable.
LDA (Latent Dirichlet allocation): pLSA can only explain input data and is helpless with new data, so it can’t work in real-time. Thus LDA emerged—LDA can infer topic distribution for new data. “Smoothed pLSA” refers to LDA adding prior probability to pLSA, specifically the Dirichlet prior distribution.
HDP (Hierarchical Dirichlet process) is similar to LDA in effect; the benefit is not needing to specify the number of topics before training.
The author believes that although many models are listed above, quite a few are equivalent. For example, the equivalence of NMF and pLSA can be found in this article; equivalence of pLSA and LDA in this article.
Finally, when semantic understanding is applied to the three Internet businesses mentioned above (online advertising, recommendation systems, search engines), the basic steps are consistent:
- Relevance: information retrieval
- Ranking: click-through rate prediction
The first step uses semantic understanding to find results related to the query; the second step ranks these related results based on click-through rate and business-specific metrics.