Introduction and Implementation of WAND Algorithm
This article mainly introduces the principles and implementation of the WAND (Weak AND) algorithm. WAND is a search algorithm applied in scenarios where a query has multiple keywords or tags, and each document also has multiple keywords or tags (such as search engines). Especially when the query contains many keywords or tags, WAND can quickly select the Top n relevant documents. The original paper of the algorithm can be found at Efficient Query Evaluation using a Two-Level Retrieval Process. This article mainly explains the principles of this algorithm and implements it in Python.
Generally, retrieval often utilizes inverted indexes, which can quickly retrieve candidate documents based on keywords in the query. However, when the candidate document set is large, traversing all candidate documents takes significant time.
But retrieval often only needs to get Top n results. During traversing candidate documents, can we skip some documents with low relevance to the query to accelerate the retrieval process? The WAND algorithm is designed for this purpose.
Introduction to WAND Principles
The WAND algorithm estimates the upper bound of document relevance by calculating each term’s contribution upper bound, then compares it with a preset threshold to skip documents that definitely cannot meet the relevance requirement, thus achieving speedup.
The above sentence covers the WAND algorithm’s idea. Let me explain in detail:
WAND algorithm first needs to estimate each term’s contribution upper bound to relevance. The simplest relevance measure is TF-IDF. Generally, IDF is fixed, so we only need to estimate a term’s term frequency (TF) upper bound in various documents (i.e., the maximum TF of this term across all documents). This step can be completed through offline computation.
After offline computation of each term’s relevance upper bound, we can calculate the upper bound of relevance between a query and a document, which is the sum of relevance upper bounds for terms they share. By comparing with a preset threshold, if the query’s relevance with the document is greater than the threshold, proceed to the next calculation; otherwise, discard.
In the above process, if we still calculate relevance for the query and each document one by one, we haven’t reduced time complexity. The WAND algorithm uses inverted indexes in a clever way to skip documents that definitely cannot meet the relevance requirement.
WAND algorithm steps are as follows:
- Build inverted index, recording all document IDs (DID) where each word appears, with IDs sorted from small to large
- Initialize posting array, so that posting[pTerm] is the index of the first document in the inverted index for term pTerm
- Initialize curDoc = 0 (document IDs start from 1)
Then we can execute the following next function (from the original paper):
The meanings of several functions used in the above process are as follows:
1. sort(terms, posting): Sort all terms from small to large based on the current document ID pointed to by the posting array. Below are three terms and their corresponding indexed document IDs. At this point, the posting array is [1, 0, 1], so the sorting result based on each term’s current document ID should be t1, t2, t3
t0: [3, 26] t1: [4, 10, 100] t2: [2, 5, 56]
2. findPivotTerm(terms, θ): Following the previously obtained order, start accumulating each term’s relevance contribution upper bound (upper bound, UB) from the first term. These have been calculated offline earlier. Continue until the accumulated sum is greater than or equal to the set threshold θ, then return the current term. Here’s an example from this article. Below is the inverted index after sort(terms, posting). Assume threshold θ = 8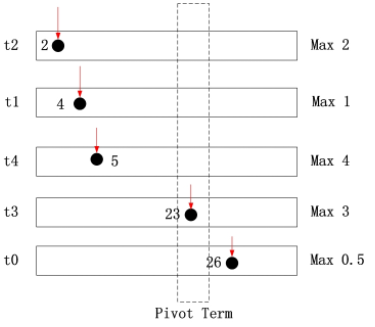
For doc 2, its possible maximum score is 2<8 For doc 4, its possible maximum score is 2+1=3<8 For doc 5, its possible maximum score is 2+1+4=7<8 For doc 23, its possible maximum score is 2+1+4+3=10>8 Therefore, t3 is the pivotTerm, and doc 23 is the pivot
3. pickTerm(terms[0..pTerm]): Select a term from 0 to pTerm (not including pTerm). For the selection strategy, the principle is to skip the most documents. The paper chose the term with the largest IDF. Using the above figure as an example, we can choose t2, t1 or t4, and select the term with the largest IDF value.
4. aterm.iterator.next(n): Return the document ID (DID) from the inverted index for aterm, where DID >= n. Then posting[aterm] ← aterm.iterator.next(n) essentially updates the current document for aterm in the posting array, thus skipping some unnecessary documents in aterm’s corresponding index.
Still using the above figure as an example, if the chosen aterm is t2, then the pointer pointing to 2 in t2 needs to move forward until DID >= 23. This way, some documents that don’t need calculation are skipped.
Actually, t1 and t4 can also perform this operation, because documents before doc 23 cannot reach threshold θ (since DIDs are sorted). So t2, t1, and t4’s corresponding items in the posting array can all jump directly to positions greater than or equal to doc23. However, the paper only selects one term each time. Although multiple iterations achieve the same effect, I think all three terms can be skipped together here.
Having introduced the important functions in the above process, let’s look at what each branch in the above code represents:
if (pTerm = null) return (NoMoreDocs)means the sum of upper bounds for all current terms cannot reach threshold θ, end the algorithmif (pivot = lastID) return (NoMoreDocs)means there are no more documents with relevance greater than threshold θ, end the algorithmif (pivot ≤ curDoc)means the DID pointed to by the current pivot has already had its relevance calculated, need to skip. This part of code will execute in step 4 before entering the loop againif (posting[0].DID = pivot)means the current pivot document’s relevance might satisfy being greater than threshold θ. Return this document’s ID and calculate the relevance between this document and the query.posting[0].DID = pivotmeans from the first term to the current term, they all point to the same document- The else statement corresponding to
if (posting[0].DID = pivot)means those terms traversed earlier whose current DIDs cannot satisfy being greater than threshold θ, so they need to be skipped. This is exactly where the number of documents requiring relevance calculation is greatly reduced.
WAND Implementation Code
The Python code implementing the WAND algorithm can be found here. I modified the code from this article and added a function to evaluate document-query similarity. Note the following points in the code:
- When all documents for a term have been traversed, there are two handling methods. The first is direct deletion, which reduces time complexity and memory usage for each sort, but deleting from an ordered list each time has O(n) time complexity where n is the number of terms. The second method is to add a number larger than all document IDs (LastID) at the end of each term’s document list. This way, traversed terms naturally get sorted to the end, making the overall code cleaner. Both methods were tried; detailed code can be seen in the commit history of the above code link.
- The
pickTermmethod in the original paper selects the term with the maximum IDF value. Here, we directly select the first one because the code is only for illustrating the algorithm flow, and each term has no IDF value. Of course, if each term has an IDF value, selection can be based on IDF. - In the algorithm flow of the above pseudocode, the final else statement selects any one term from pivotTerm and skips low-relevance documents. But from the earlier explanation, all terms before pivotTerm can perform this operation, so this part in the code differs from the pseudocode.
Here’s the complete code. You can compare it with the above pseudocode - naming conventions are basically kept consistent. Feel free to point out any errors.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138import heapq
UB = {"t0":0.5,"t1":1,"t2":2,"t3":3,"t4":4} #upper bound of term's value
LAST_ID = 999999999999 # a large number, larger than all the doc id in the inverted index
THETA = 2 # theta, threshold for chechking whether to calculate the relevence between query and doc
TOPN = 3 #max result number
class WAND:
def __init__(self, InvertIndex):
"""init inverted index and necessary variable"""
self.result_list = [] #result list
self.inverted_index = InvertIndex #InvertIndex: term -> docid1, docid2, docid3 ...
self.current_doc = 0
self.current_inverted_index = {} #posting
self.query_terms = []
self.sort_terms = []
self.threshold = THETA
self.last_id = LAST_ID
def __init_query(self, query_terms):
"""init variable with query"""
self.current_doc = 0
self.current_inverted_index = {}
self.query_terms = []
self.sort_terms = []
for term in query_terms:
if term in self.inverted_index: # terms may not appear in inverted_index
doc_id = self.inverted_index[term][0]
self.query_terms.append(term)
self.current_inverted_index[term] = [doc_id, 0] #[ docid, index ]
self.sort_terms.append([doc_id, term])
def __pick_term(self, pivot_index):
"""select the term before pivot_index in sorted term list
paper recommends returning the term with max idf, here we just return the firt term,
also return the index of the term instead of the term itself for speeding up"""
return 0
def __find_pivot_term(self):
"""find pivot term"""
score = 0
for i in range(len(self.sort_terms)):
score += UB[self.sort_terms[i][1]]
if score >= self.threshold:
return [self.sort_terms[i][1], i] #[term, index]
return [None, len(self.sort_terms)]
def __iterator_invert_index(self, change_term, docid, pos):
"""find the new_doc_id in the doc list of change_term such that new_doc_id >= docid,
if no new_doc_id satisfy, the self.last_id"""
doc_list = self.inverted_index[change_term]
# new_doc_id, new_pos = self.last_id, len(doc_list)-1 # the case when new_doc_id not exists
for i in range(pos, len(doc_list)):
if doc_list[i] >= docid: # since doc_list contains self.last_id, this inequation will always be satisfied
new_pos = i
new_doc_id = doc_list[i]
break
return [new_doc_id, new_pos]
def __advance_term(self, change_index, doc_id ):
"""change the first doc of term self.sort_terms[change_index] in the current inverted index
return whether the action succeed or not"""
change_term = self.sort_terms[change_index][1]
pos = self.current_inverted_index[change_term][1]
new_doc_id, new_pos = self.__iterator_invert_index(change_term, doc_id, pos)
self.current_inverted_index[change_term] = [new_doc_id, new_pos]
self.sort_terms[change_index][0] = new_doc_id
def __next(self):
while True:
self.sort_terms.sort() #sort terms by doc id
pivot_term, pivot_index = self.__find_pivot_term() #find pivot term > threshold
if pivot_term == None: #no more candidate
return None
pivot_doc_id = self.current_inverted_index[pivot_term][0]
if pivot_doc_id == self.last_id: # no more candidate
return None
if pivot_doc_id <= self.current_doc:
change_index = self.__pick_term(pivot_index)
self.__advance_term(change_index, self.current_doc + 1)
else:
first_doc_id = self.sort_terms[0][0]
if pivot_doc_id == first_doc_id:
self.current_doc = pivot_doc_id
return self.current_doc # return the doc for fully calculating
else:
# pick all preceding term instead of just one, then advance all of them to pivot
change_index = 0
while change_index < pivot_index:
self.__advance_term(change_index, pivot_doc_id)
change_index += 1
# print(self.sort_terms, self.current_doc, pivot_doc_id)
def __insert_heap(self, doc_id, score):
"""store the Top N result"""
if len(self.result_list) < TOPN:
heapq.heappush(self.result_list, (score, doc_id))
else:
heapq.heappushpop(self.result_list, (score, doc_id))
def __calculate_doc_relevence(self, docid):
"""fully calculate relevence between doc and query"""
score = 0
for term in self.query_terms:
if docid in self.inverted_index[term]:
score += UB[term]
return score
def perform_query(self, query_terms):
self.__init_query(query_terms)
while True:
candidate_docid = self.__next()
if candidate_docid == None:
break
#insert candidate_docid to heap
print('candidata doc', candidate_docid)
full_doc_score = self.__calculate_doc_relevence(candidate_docid)
self.__insert_heap(candidate_docid, full_doc_score)
print("result list ", self.result_list)
return self.result_list
if __name__ == "__main__":
testIndex = {}
testIndex["t0"] = [1, 3, 26, LAST_ID]
testIndex["t1"] = [1, 2, 4, 10, 100, LAST_ID]
testIndex["t2"] = [2, 3, 6, 34, 56, LAST_ID]
testIndex["t3"] = [1, 4, 5, 23, 70, 200, LAST_ID]
testIndex["t4"] = [5, 14, 78, LAST_ID]
w = WAND(testIndex)
final_result = w.perform_query(["t0", "t1", "t2", "t3", "t4"])
print("=================final result=======================")
for i in reversed(range(len(final_result))):
print("doc {0}, relevence score {1}".format(final_result[i][1], final_result[i][0]))
References:
Basic idea of WAND (Weak AND) algorithm WAND algorithm core part analysis