Gradient Clipping and Its Role
This article briefly introduces the gradient clipping method and its role. I recently found this mechanism has a huge impact on results when training RNNs.
Gradient clipping is generally used to solve the gradient explosion problem, which occurs especially frequently when training RNNs, so training RNNs basically requires this parameter. Common gradient clipping methods have two approaches:
- Directly clip based on the parameter’s gradient value
- Clip based on the L2 norm of the vector composed of several parameters’ gradients
The first approach is easy to understand - set a gradient range like (-1, 1). Gradients less than -1 are set to -1, and gradients greater than 1 are set to 1.
The second method is more common. First set a clip_norm, then after one backward propagation, construct a vector from each parameter’s gradient. Calculate this vector’s L2 norm (square root of sum of squares), denoted as LNorm. Then compare LNorm with clip_norm. If LNorm <= clip_norm, do nothing. Otherwise, calculate the scaling factor scale_factor = clip_norm/LNorm, then multiply the original gradient by this scaling factor. This ensures the gradient vector’s L2 norm is less than the preset clip_norm.
The role of gradient clipping can be more intuitively understood from the figure below. Without gradient clipping, if the gradient is too large, the optimization algorithm may overshoot the optimal point.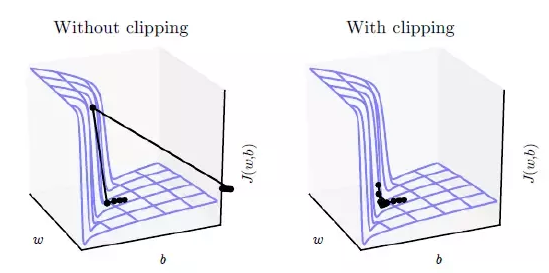
In some frameworks, gradient clipping is often set in the Optimizer. For example, in TensorFlow:1
2
3
4optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
gvs = optimizer.compute_gradients(cost)
capped_gvs = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gvs]
train_op = optimizer.apply_gradients(capped_gvs)
In Keras, it’s even simpler:1
optimizer = optimizers.SGD(lr=0.001, momentum=0.9, clipnorm=1.),
Besides this, debugging RNNs is a tricky task. You can refer to this Zhihu question: What special tricks do you use when training RNN?
Additionally, the opposite problem to gradient explosion is gradient vanishing, which has different solutions - you can’t simply use scaling. For details, refer to this question: Why not solve the gradient vanishing problem through gradient scaling?. The actual handling method is generally using RNN units with memory like LSTM or GRU.
References:
- Gradient Clipping
- What does clip gradient mean in Caffe?
- What is gradient clipping and why is it necessary?