Introduction to CTR Prediction Models - Deep Learning
This article mainly introduces some deep learning models in CTR prediction, including FNN, Wide&Deep, PNN, DIN, Deep&Cross, etc. Each model will briefly introduce its principles, paper sources, and some open-source implementations.
FNN (Factorization-machine supported Neural Network)
Model Structure
FNN was published by University of London in 2016. The model structure is as follows: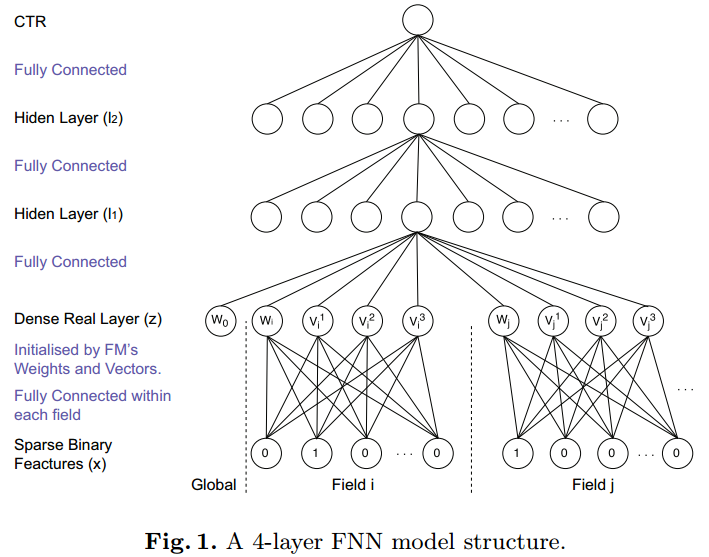
FNN assumes that the input data format is discrete categorical features (represented as one-hot encoding), and each feature belongs to a field. Through the embedding layer, high-dimensional sparse features are mapped to low-dimensional dense features, which are then used as input to the multi-layer perceptron (MLP).
Generally, embedding layer parameters can be randomly initialized, but in FNN, the embedding initialization uses the latent vectors of each feature obtained through FM pre-training. The benefit of this initialization is that using pre-trained vectors as initialization parameters allows model parameters to start from a better position (the purpose of training is actually to obtain optimal model parameters), which can speed up the convergence process. As for effectiveness, it may not necessarily be better than random initialization, because random initialization through multiple iterations may also converge to the same effect.
Related Papers
The paper proposing FNN Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction was published by Dr. Zhang Weinan during his time at University of London. Dr. Zhang Weinan has many papers related to RTB, which can be found on his homepage.
Open-source Implementations
The paper author provided FNN code in the deep-ctr repository on github, but it’s implemented in Theano; later the author updated the code to the Tensorflow framework, see product-nets. This repository also contains the implementation code for PNN which will be introduced later.
Wide&Deep
Model Structure
Wide & Deep was released by Google in June 2016. The model combines traditional feature engineering with deep models: it has both the Wide LR model and the Deep NN model.
Its structure is as follows: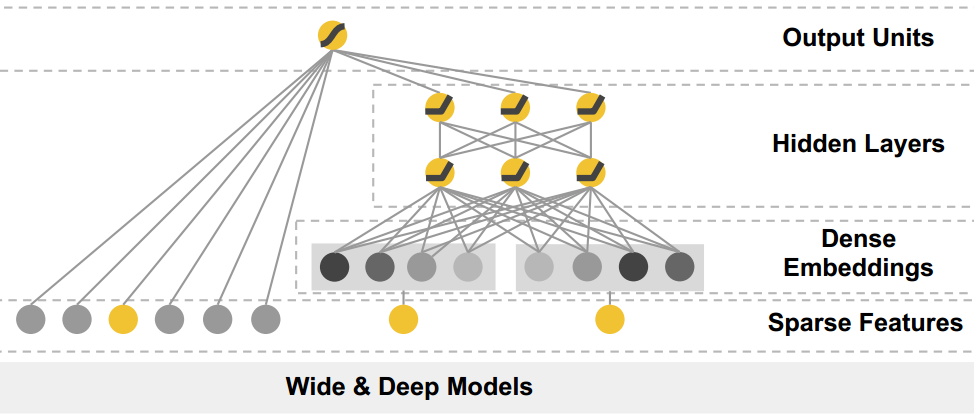
The wide part is actually LR, and the deep part is actually FNN, except that the deep part’s embedding layer doesn’t use latent vectors from FM training for initialization. According to the paper, the wide part is mainly responsible for memorization, and the deep part is mainly responsible for generalization; memorization mainly refers to remembering samples that have appeared, which can be understood as the ability to fit training data, while generalization is the generalization ability.
According to the paper’s experiments, wide & deep is better than pure wide or deep, but according to my subsequent experiments and some online articles, the wide part still requires manual feature design. When feature design is not good enough, the entire wide&deep model may not perform as well as a single deep model.
Wide&Deep also allows inputting continuous features, which is different from FNN. Continuous features can be directly used as input to the Wide part or Deep part without embedding mapping, as shown in the figure below.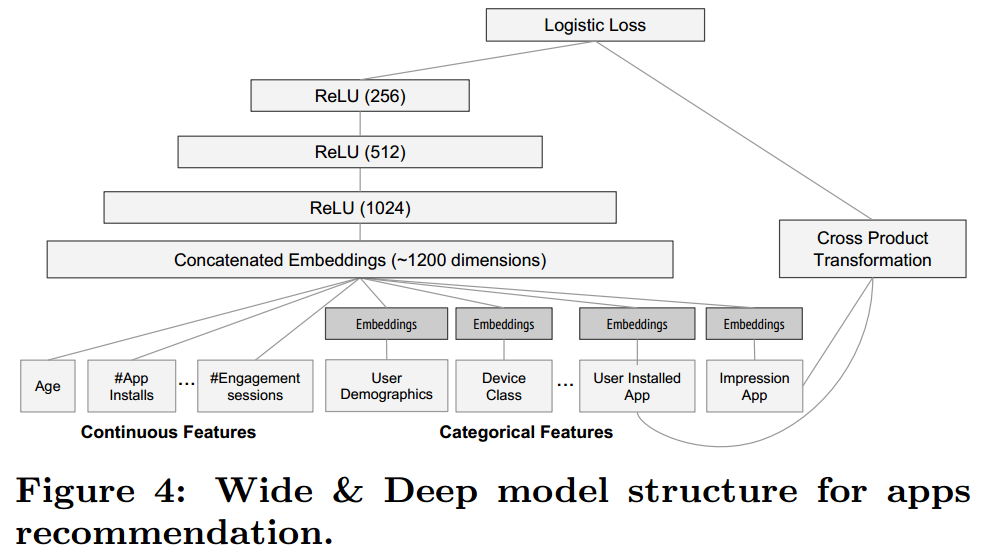
Related Papers
Wide&Deep was proposed by Google in the paper Wide & Deep Learning for Recommender Systems. The paper was originally used for Google Play recommendations, but recommendation and CTR are actually the same type of problem: ranking problem, so it can also be migrated to the CTR prediction field.
Open-source Implementations
Since Wide&Deep was proposed by Google, the Tensorflow framework provides Wide&Deep API. For specific usage, refer to the official documentation TensorFlow Wide & Deep Learning Tutorial.
PNN (Product-based Neural Networks)
Model Structure
PNN was published by Shanghai Jiao Tong University in 2016. FNN improved upon PNN by adding second-order feature cross terms. Therefore, the relationship between FNN and PNN is similar to the relationship between LR and FM, except that both FNN and PNN perform embedding mapping on original features. The PNN model structure is as follows: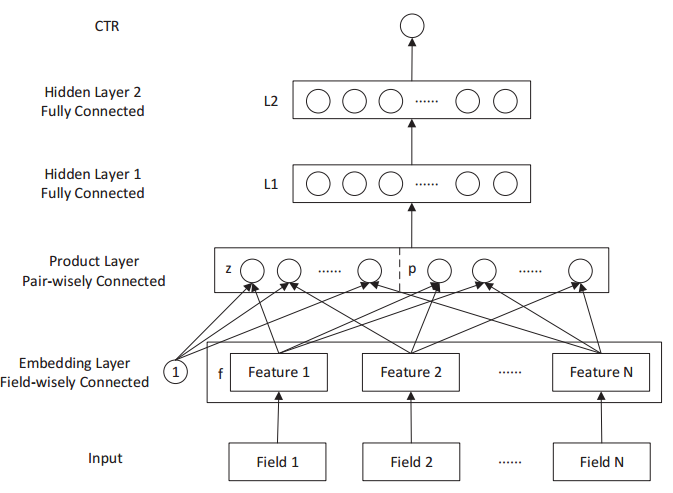
After features are mapped through the embedding layer, there are two types of product operations. The first is outer product with 1, which is actually concatenating the mapped features, obtaining the z vector part in the figure above; the second is inner product with other features pairwise, obtaining the p vector part in the figure above. This operation is actually equivalent to feature crossing, except this crossing is after embedding mapping. The subsequent structure is actually another multi-layer perceptron.
Related Papers
PNN was proposed by Shanghai Jiao Tong University in 2016 in this paper Product-based Neural Networks for User Response Prediction.
Open-source Implementations
PNN’s author open-sourced its code on github at product-nets, implemented through Tensorflow. The code also contains implementations of FNN, DeepFM, and some other models.
DeepFM
Model Structure
DeepFM was proposed by Huawei Noah’s Ark Lab in 2017 for CTR prediction. DeepFM actually imitates Wide&Deep, but replaces the Wide part with FM, so the innovation is not significant. Its structure is as follows: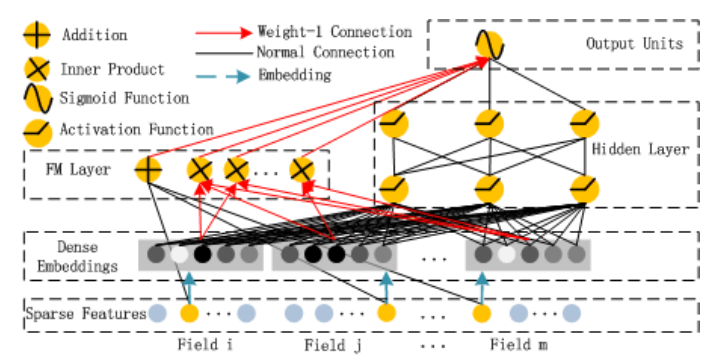
Related Papers
DeepFM was proposed in this paper DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Open-source Implementations
The author didn’t release the source code. The product-nets mentioned above provides implementation code for this model, and tensorflow-DeepFM also provides a tensorflow implementation version, with a relatively high star count on github.
DIN (Deep Interest Network)
Model Structure
From the models mentioned earlier, we know that the basic idea of deep learning models in CTR prediction is to map original high-dimensional sparse features to a low-dimensional space, i.e., embedding the original features, then together pass through a fully connected network to learn interaction information between features and the final nonlinear relationship with CTR. One thing worth noting is that when processing user historical behavior data, each user has a different number of historical clicks, and we need to encode them into a fixed-length vector. The previous approach is to do the same embedding operation for each historical click, then do a sum or max operation, similar to passing through a pooling layer operation. The paper proposing DIN believes this operation loses a lot of information, so it introduces the attention mechanism (which is actually a weighted sum).
DIN was proposed by Alibaba Mom in 2017. Its model structure is as follows: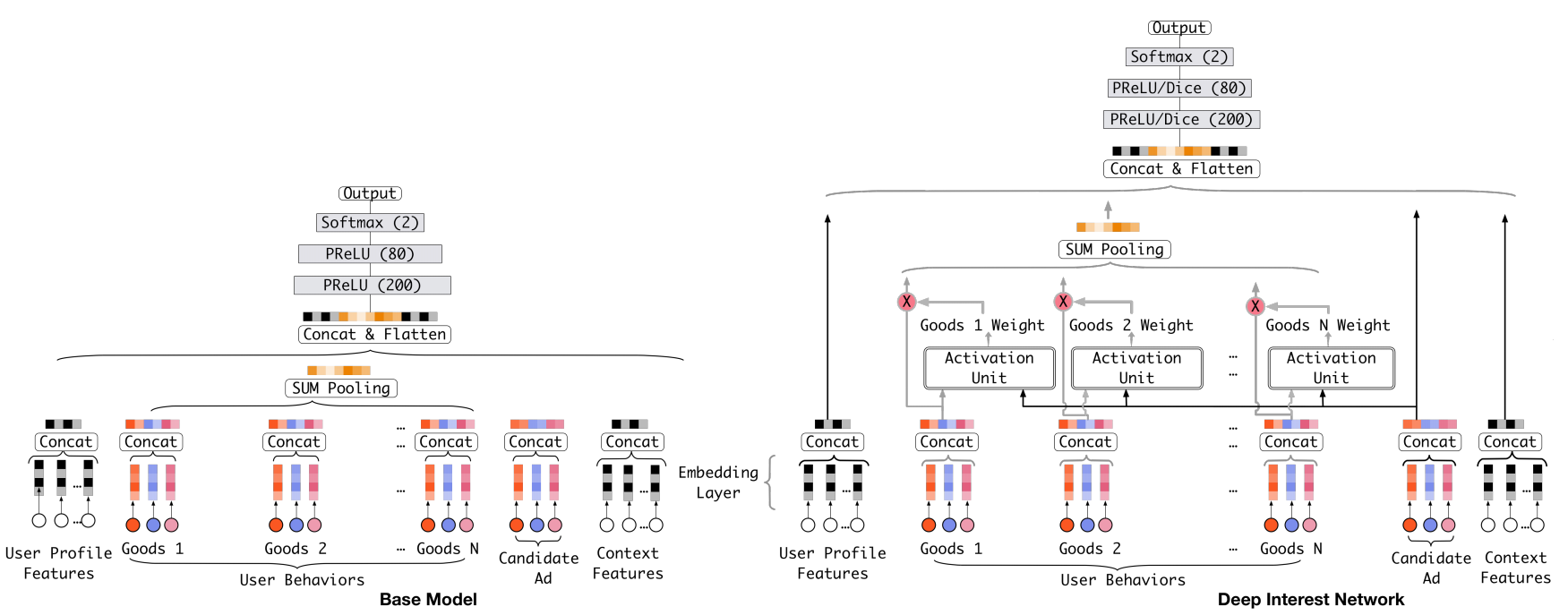
The Activation Unit structure is as follows: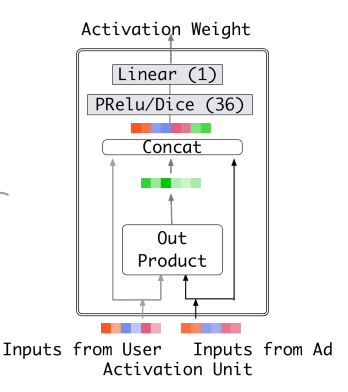
The DIN model introduces attention network (i.e., the Activation Unit in the figure) in computing user representation. DIN embeds user features and user historical behavior features, considering them as representations of user interests, then through attention network, assigns different weights to each interest representation. This weight is calculated from matching user interests with the ad to be estimated, so the model structure conforms to the two observations mentioned earlier - diversity of user interests and partial correspondence. The attention network calculation formula is as follows: \(V_u\) represents user representation vector, \(V_i\) represents user interest representation vector, \(V_a\) represents ad representation vector, \(w_i\) represents the weight of each user interest representation vector, and \(g\) is the Activation Unit logic. The paper proposed an Activation Unit as shown in the figure above, but of course, new Activation methods can also be designed.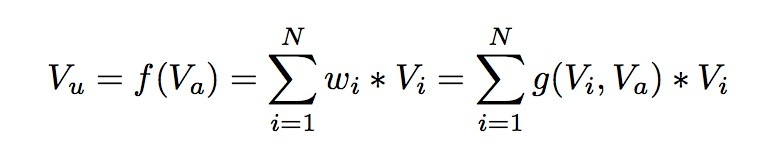
Related Papers
DIN was proposed in the paper Deep Interest Network for Click-Through Rate Prediction.
Open-source Implementations
The paper author open-sourced its code on github at DeepInterestNetwork, implemented through Tensorflow.
Deep&Cross
Model Structure
PNN performs second-order feature crossing, aiming to obtain features with more information. Besides second-order, third-order, fourth-order, or even higher-order features would have more discriminative power; Deep&Cross is a neural network that can perform arbitrary high-order crossing.
Deep&Cross was proposed by Stanford and Google in 2017. Similar to Wide&Deep, the model also consists of two parts: Deep network and Cross network. The model structure is as follows: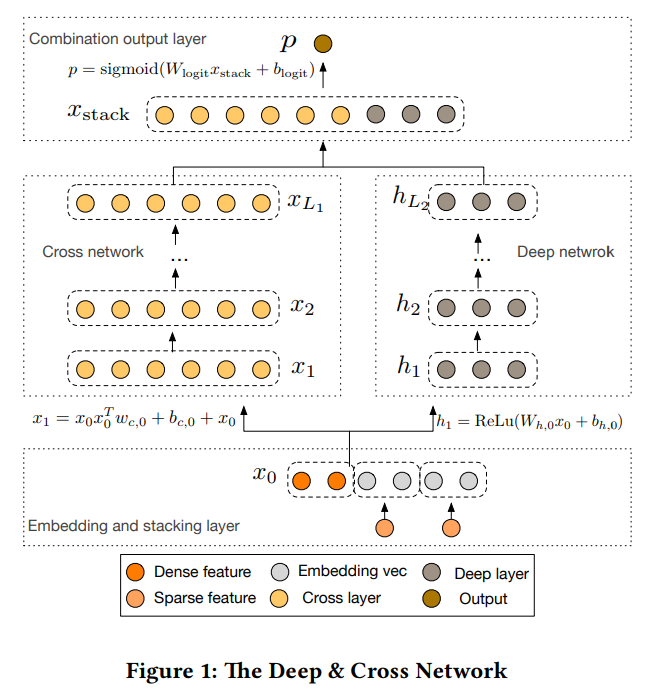
\(x_i\) can be determined by the following formula: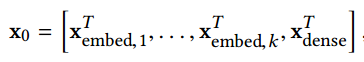
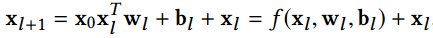
From the above two formulas, we can see that neurons in the \(l+1\) layer of the Cross network are jointly determined by the most original input and neurons in the \(l\) layer, so the \(l\) layer is equivalent to performing \(l\)-order crossing on original features.
Related Papers
Deep&Cross was proposed in this paper Deep & Cross Network for Ad Click Predictions.
Open-source Implementations
The paper didn’t release code. DeepCTR provides a tensorflow implementation of Deep&Cross for reference.
Summary
In CTR prediction, whether to use traditional methods or deep learning methods is actually a trade-off between massive discrete features + simple model and small amount of continuous features + complex model. You can either discretize and use linear models, or use continuous features with deep learning. Features and models are often dual - the former is easier, and multiple people can work in parallel with successful experience; the latter currently looks great, but how far it can go remains to be seen.