Introduction to Distillation
This article briefly describes the principles of distillation in machine learning. Distillation can be simply divided into model distillation and feature distillation. As the name suggests, distillation compresses the original model/features. The reasons may be to reduce model size (model distillation), or because certain features are only available during training but not during serving (feature distillation). In practical business, these two techniques can be flexibly applied according to specific scenarios.
Basic Principles
Distillation can be divided into Model Distillation and Feature Distillation. The idea is to train two models simultaneously during training: a teacher model and a student model, while only using the student model during serving. The assumption here is: the teacher model is more complex in model structure (Model Distillation) or has richer feature sets (Feature Distillation) compared to the student model; therefore, its accuracy will be better than the student model.
The figure below shows examples of Model Distillation and Feature Distillation (the following figures and formulas are basically from Privileged Features Distillation for E-Commerce Recommendations)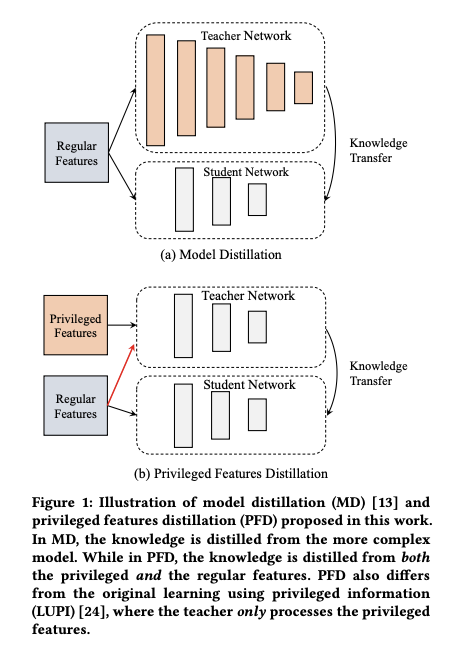
How to use the teacher model to guide the student model to learn better? The basic approach is to use the teacher model’s output as soft label (relative to hard label as ground truth), adding an additional loss term for the student model; as shown in formula (1) below:
\[\begin{align} \min_{W_s} (1-\lambda)L_s(y, f_s(X;W_s))+\lambda*L_d(f_t(X;W_t),f_s(X;W_s)) \tag{1} \end{align}\]
The symbols in the formula have the following meanings:
- \(f_s(X; W_s)\): student model’s prediction value
- \(f_t(X;W_t)\): teacher model’s prediction value
- \(L_s\): student model’s original loss
- \(L_d\): distillation loss calculated using teacher model’s prediction output as soft label
- \(\lambda\): hyperparameter balancing \(L_s\) and \(L_d\)
The above formula (1) is a typical approach for Model Distillation. We can see that the features input to the teacher model and student model are the same, i.e., \(X\); while formula (2) describes Feature Distillation which considers that the teacher model’s features (\(X^*\)) are richer than the student model’s features (\(X\)):
\[\begin{align} \min_{W_s} (1-\lambda)L_s(y, f_s(X;W_s))+\lambda\*L_d(f_t(X^\*;W_t),f_s(X;W_s)) \tag{2} \end{align}\]
The above two formulas are the core idea of Distillation. Theoretically, the teacher network should be trained first, then the student network; but in actual training, to speed up training, the teacher model and student model are trained simultaneously; therefore, the final loss function becomes the form of formula (3), where \(L_s\) and \(L_t\) are logloss, and \(L_d\) is cross entropy loss:
\[\begin{align} \min_{W_s, W_t} (1-\lambda)L_s(y, f_s(X;W_s)) + \lambda\*L_d(f_t(X^\*;W_t),f_s(X;W_s)) + L_t(y, f_t(X^\*;W_t))\tag{3} \end{align}\]
In summary, the model structures during training and serving are shown below: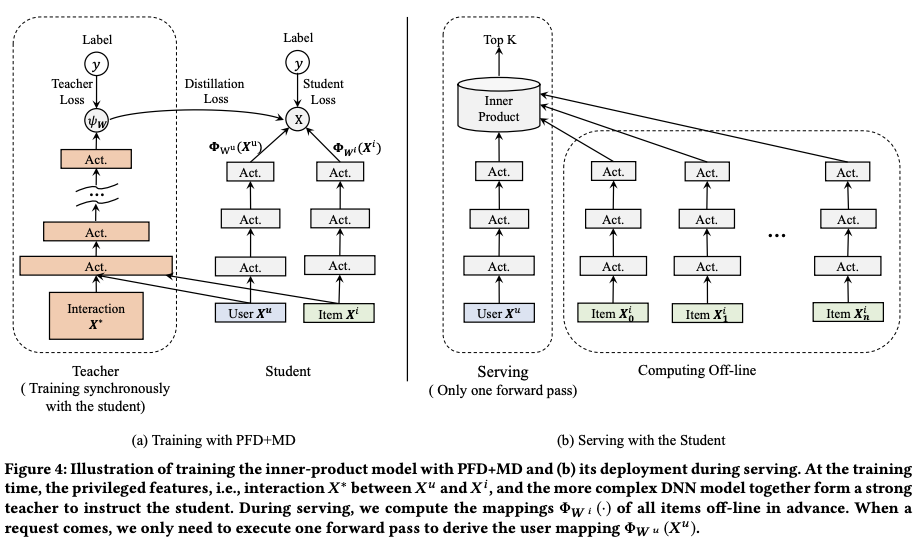
Training Considerations
As mentioned above, distillation requires training both teacher and student networks, so there are two training modes:
- Train the teacher network first, then train the student network, also called asynchronous training
- Train the teacher network and student network simultaneously, also called synchronous training
Theoretically, approach (1) should be used, but since training two models serially leads to very long training time, approach (2) was proposed; however, approach (2) brings the problem of unstable training results, because in the early stage of teacher training, its results are often not good yet, and using its output as label can easily cause the student network to diverge.
Therefore, a more common approach is to make a trade-off between these two, basically setting \(\lambda\) in formula (3) to 0 in the early stage of training, then gradually increasing the value of \(\lambda\).
The paper mentioned above proposed a simpler strategy for this point: only after \(k\) steps let the teacher network’s output as loss affect the student network, where \(k\) is a predetermined hyperparameter. Therefore, the detailed training method is as follows:
Implementation
Tensorflow provides an implementation of distillation distillation.py, usage can be found in this answer on stack-overflow.
The core code is shown below. The comments are already very clear. The default mode below is to train the Teacher network first, then train the Student network, which is the asynchronous training mode mentioned above; but it can also be easily modified to synchronous training.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52### Teacher Network
with tf.variable_scope("teacher"):
teacher_outputs = self.teacher_model.body(features)
tf.logging.info("teacher output shape: %s" % teacher_outputs.get_shape())
teacher_outputs = tf.reduce_mean(teacher_outputs, axis=[1, 2])
teacher_logits = tf.layers.dense(teacher_outputs, hp.num_classes)
teacher_task_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=one_hot_targets, logits=teacher_logits)
outputs = teacher_logits
if is_distill:
# Load teacher weights
tf.train.init_from_checkpoint(hp.teacher_dir, {"teacher/": "teacher/"})
# Do not train the teacher
trainable_vars = tf.get_collection_ref(tf.GraphKeys.TRAINABLE_VARIABLES)
del trainable_vars[:]
### Student Network
if is_distill:
with tf.variable_scope("student"):
student_outputs = self.student_model.body(features)
tf.logging.info(
"student output shape: %s" % student_outputs.get_shape())
student_outputs = tf.reduce_mean(student_outputs, axis=[1, 2])
student_logits = tf.layers.dense(student_outputs, hp.num_classes)
student_task_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=one_hot_targets, logits=student_logits)
teacher_targets = tf.nn.softmax(teacher_logits / hp.distill_temperature)
student_distill_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=tf.stop_gradient(teacher_targets),
logits=student_logits / hp.distill_temperature)
# scale soft target obj. to match hard target obj. scale
student_distill_xent *= hp.distill_temperature**2
outputs = student_logits
# Summaries
tf.summary.scalar("distill_xent", student_distill_xent)
if not is_distill:
phase_loss = teacher_task_xent
else:
phase_loss = hp.task_balance * student_task_xent
phase_loss += (1 - hp.task_balance) * student_distill_xent
losses = {"training": phase_loss}
outputs = tf.reshape(outputs, [-1, 1, 1, 1, outputs.shape[1]])
return outputs, losses