Reading Notes on "Embedding-based Retrieval in Facebook Search"
Embedding-based Retrieval in Facebook Search is a 2020 Facebook paper on vector retrieval for search. Reading through it, it’s like a frontline engineer explaining how they built a retrieval system from 0 to 1, covering training data and feature selection, model training and serving, integrating new retrieval strategies into existing ranking systems. The paper doesn’t have many formulas and derivations, but has many practical lessons that can be applied beyond search to recommendation / advertising. This article mainly 提炼 s the author’s understanding, recommend reading the original.
Key points from this paper:
- Negative sample selection for retrieval models (why not just use exposed unclicked samples as negatives, easy negative vs hard negative)
- How new retrieval strategies overcome current ranking system’s bias
- Common flow for building retrieval systems and experience in each step
The following content basically matches the paper, mainly introducing key points.
System Overview
In recommendation, advertising, and search, the basic architecture is retrieval + ranking. Since all three need to select top-k from a huge candidate set when each request arrives, and retrieval faces nearly the entire candidate set, to meet latency requirements, retrieval doesn’t use complex models and features, and often builds inverted indices for items.
The paper’s overall architecture is shown below. When each request arrives, user embedding is computed in real-time, then document embedding inverted index is used for retrieval. For speed, vector retrieval also uses Quantization (covered in serving step later).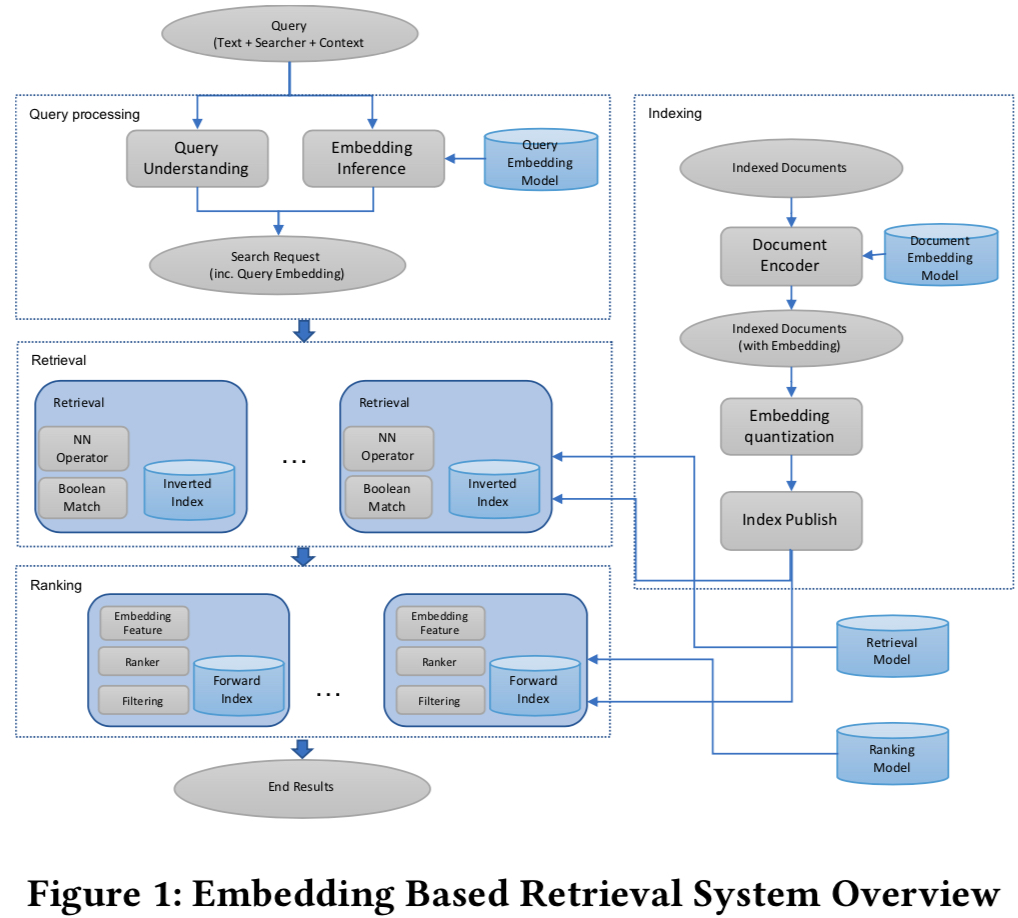
Model
Here model refers to Query Embedding Model and Document Embedding Model above that generate embeddings. Uses classic two-tower model shown below. Unified embedding means input raw features include not only query and document text, but also context information. This approach was already in Google’s 2016 Deep Neural Networks for YouTube Recommendations, an advantage of NN over Matrix Factorization - more features can be added.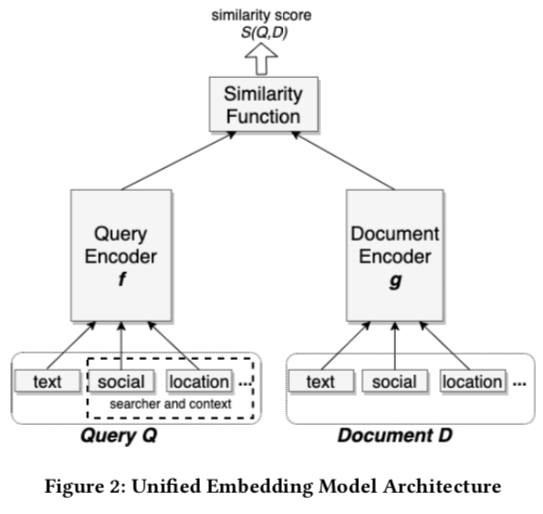
Loss Function
Model uses triplet loss, first proposed in face recognition. Assume each training sample is \((q^{(i)},d_+^{(i)}, d_-^{(i)})\), where \(d_+^{(i)}\) is the relevant document for query \(q^{(i)}\), and \(d_-^{(i)}\) is irrelevant. The paper’s loss is:
\[\begin{align} L=\sum_{i=1}^{N} \max(0, D(q^{(i)},d_+^{(i)}) - D(q^{(i)},d_-^{(i)}) + m) \end{align}\]
\(m\) is a hyperparameter representing enforced margin between positive and negative samples. If distance difference exceeds m, it’s an easy example not needing further learning. The paper mentions this hyperparameter significantly affects results since optimal m varies by task.
\(D\) is distance function (smaller means more similar). Paper uses \(D(q,d) = 1-cos(q, d)\).
Additionally, for the training sample pairs in the paper, classic LTR pairwise loss could also be used. See From RankNet to LambdaRank to LambdaMART: An Overview.
Paper uses offline recall as metric, with validation set being 10000 search sessions with each query and its target result (paper doesn’t explicitly give this standard, just mentions clicks or manual evaluation are fine).
Training Samples
Training sample selection is a key emphasis in the paper. The key is negative sample selection. Paper selects clicked samples as positive, and compares two negative sampling approaches:
- Random negative sampling
- Exposed unclicked samples as negatives
Results show exposed unclicked samples as negatives perform much worse than random negatives. Paper explains:
We believe it is because these negatives bias towards hard cases which might match the query in one or multiple factors, while the majority of documents in index are easy cases which do not match the query at all. Having all negatives being such hard negatives will change the representativeness of the training data to the real retrieval task, which might impose non-trivial bias to the learned embeddings.
The author understands using exposed unclicked as negatives causes training-serving inconsistency. Exposed unclicked are mostly hard cases - even though ultimately unclicked, they still have some relevance to the query. But online retrieval faces all candidates, mostly easy cases completely irrelevant to this query. Using only hard cases as negatives creates inconsistency with final serving.
Besides negatives, paper also explores positive selection, comparing:
- Clicks as positives
- Exposures as positives
Results show similar performance with same data volume. Even adding click positives on top of exposure positives, no further improvement.
For positive selection, though paper says both work similarly, the author thinks using exposure samples as positives is more appropriate in practice:
- Clicks are sparse with less data
- Unclicked samples aren’t necessarily bad - might be due to position etc. Sampling these is somewhat like exploration
hard mining
This is Section 6 content, but also a key point in training sample selection.
As mentioned above, negatives shouldn’t be exposed unclicked hard cases, but if all negatives are easy cases easily distinguished from positives, the model may not learn well either. Paper states:
This motivated us believe that the model was not able to utilize social features properly yet, and it’s very likely because the negative training data were too easy as they were random samples which are usually with different names. To make the model better at differentiating between similar results, we can use samples that are closer to the positive examples in the embedding space as hard negatives in training.
Hard negatives are those with high similarity to positives (relative to random negatives), but not exposed unclicked negatives. Paper proposes two methods: online hard negative mining and offline hard negative mining.
online hard negative mining
In each batch’s training, assuming positive pairs \(\lbrace(q^{(i)},d_+^{(i)})\rbrace_{i=1}^{n}\), for each query \(q^{(i)}\), randomly select k documents from \(\lbrace d_+^{(1)} \dots d_+^{(j)} \dots d_+^{(n)} | j \ne i\rbrace\) as hard negatives. Paper finds k=2 optimal; more degrades performance.
Experimental data shows adding such hard negatives improves recall across different item types.
But negatives selected this way aren’t hard enough, because these negatives belong to different queries with low cross-query relevance, so these samples’ similarity isn’t high. Hence offline hard negative mining.
offline hard negative mining
Offline hard negative mining is more like LTR’s pairwise sample construction. Selection method: for each query’s documents, select samples ranked 101-500 as hard negatives. Notably, selecting hardest negatives (e.g., ranked 2nd) isn’t optimal.
Above is negative mining. Positive mining is similar but paper covers less, only mentioning “we mined potential target results for failed search sessions from searchers’ activity log”, roughly finding unrecalled but positive samples from failed search sessions.
In summary, paper emphasizes negatives should contain both easy and hard negatives. Paper’s view: hard negatives focus on non-text features (like social features), while easy negatives focus on text features. Mixing both is needed. Two mixing approaches:
(1)blending: train with both mixed. Optimal ratio is easy:hard ≈ 100:1 (2)transfer learning from “hard” model to “easy” model: train with hard negatives first, then easy (paper mentions “easy” to “hard” doesn’t achieve same effect)
Feature Engineering
Feature engineering emphasizes that adding context features (paper mainly proposes location feature and social embedding feature) beyond text features gives significant improvement.
text feature
For text features, paper uses character n-gram instead of word n-gram. N-gram means treating n consecutive characters or words as items input to embedding table. Paper proves character n-gram outperforms word n-gram with advantages:
- Smaller embedding lookup table size, better parameter learning, essentially reduced model size
- Better robustness for out-of-vocabulary words since embedding granularity is character
location feature
Paper adds location features to both query and document. For query: searcher’s city/region/country/language. For document: publicly available information like explicit group location tags.
Below shows document location comparison before and after adding location feature - after adding, returned documents’ locations are more similar to searcher’s.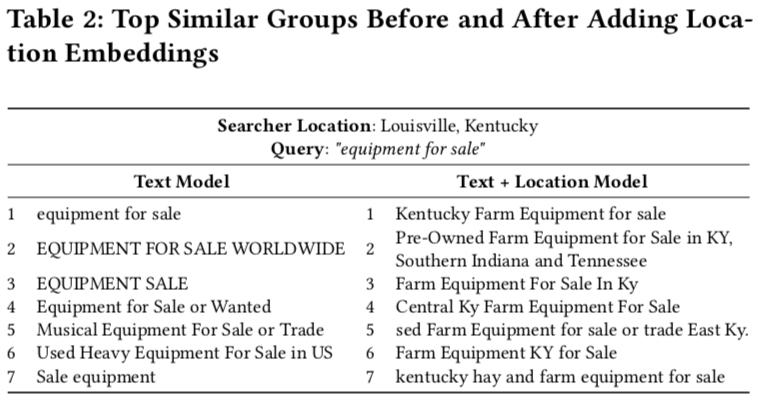
social embedding feature
Paper doesn’t detail this. Guess it’s obtained through graph embedding and input as feature to retrieval model.
Below shows improvement after adding location and social embedding features: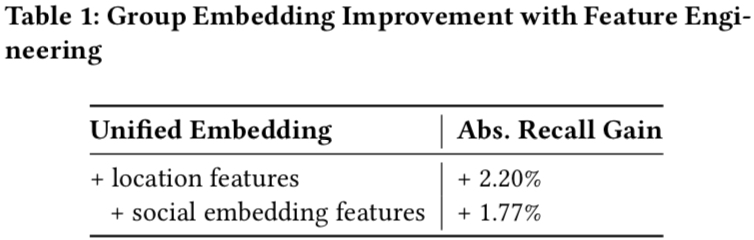
Serving
Serving uses ANN (Approximate Near Neighbor) with quantization to further shorten similarity computation. Quantization is a vector compression technique. See Understanding Product Quantization.
Vector retrieval systems typically have two steps: indexing and scoring. Indexing filters most irrelevant candidates; scoring computes and ranks among relevant candidates. Indexing commonly uses K-means, HNSW, LSH; scoring mainly uses various quantization variants.
These steps are named differently in different places. Paper calls them coarse quantization and product quantization. Coarse quantization clusters entire candidate library, selecting top-k clusters when query arrives, then scoring via product quantization. Uses Facebook’s open-source faiss library. See PQ and IVF Introduction.
Paper summarizes experience:
- When comparing coarse quantization algorithms, fix recall count (paper uses 1-Recall@10). Common practice since different algorithms cluster differently.
- When model changes significantly (non-trivial), ANN hyperparameters need adjustment for new model.
- PQ’s OPQ (Optimized Product Quantization) generally performs better.
- PQ’s sub-space partition size is a hyperparameter. Larger means more accurate but more resource overhead. Paper suggests 4: “From empirical results, we found that the accuracy improvement is limited after x > d/4.”
Actual serving only computes query tower embedding in real-time; document tower embeddings are precomputed and indexed. New documents generate incremental indices; periodically recompute full indices.
Later-stage Optimization
This mainly describes a bias in all recommendation systems: training data is generated by current system and fed back, easily causing “Matthew effect” - strong get stronger, weak get weaker. This is also an E&E problem.
In the paper, this shows as new ANN retrieval results may not be recognized by ranking:
since the current ranking stages are designed for existing retrieval scenarios, this could result in new results returned from embedding based retrieval to be ranked sub-optimally by the existing rankers
Paper proposes two solutions:
- Add retrieval embedding as ranking feature. Paper’s motivation: faster learning of new retrieval characteristics. Ways: embedding as feature directly, computed values like cosine similarity. Best results from cosine similarity feature.
- Manually intervene in training data distribution after adding new retrieval. Avoid new retrieval not being recognized. Paper labels retrieved results manually, but this is costly in practice.
Summary
Paper mainly covers Facebook’s basic steps for building ANN retrieval in search: training data selection, model training, serving, etc., with practical experience in each part. Key point is negative sample selection - paper divides negatives into easy and hard, proving using only either isn’t optimal; both must be combined.
Paper also mentions embedding ensemble: weighted concatenation (parallel, like bagging) and cascade model (cascade, like boosting). But author thinks retrieval candidates are very large with strict latency requirements; adding ensemble increases latency. Is this practical in production? Ensemble in ranking might be more reasonable?
Finally, Zhihu has an interpretation worth reading: Negative Samples are King: Reviewing Facebook’s Vector Retrieval Algorithm. For embedding applications in recommendation/advertising, see Recommendation System Embedding Technology Practice Summary.