Long Tail Problem In Item Recommendation
The long tail problem is common in recommendation/advertising systems (mainly for items). There are many reasons. The author’s understanding is that the system has a feedback loop (training data is generated by the model, and then used for training). Without external intervention, the Matthew effect naturally causes severe head effects, where a small portion of items dominate the system.
For example, in recommendation systems, many videos/articles don’t get exposure opportunities and don’t appear in training sets, while popular videos/articles rank high across different users and get recommended multiple times. In advertising systems, some campaigns have very high spend while others can’t spend at all. This leads to poor user or advertiser experience, often categorized as ecosystem problems.
Since the system’s natural characteristics cause severe head effects (or Pareto effects) without intervention, can forcibly intervening in the system distribution solve this problem? The answer is yes, and most current methods do exactly this. Common approaches are:
- Strategy level: Design rules based on system and business characteristics, such as specific support for long-tail items to forcibly reach more users
- Model level: Core idea is to let the model better learn long-tail item representations, because the root cause is insufficient samples for long-tail items, leading to poor model learning. Specific methods are detailed below.
This article mainly introduces papers at the model level, since strategy-level methods often require business-specific rules, while model-level methods are more universal.
Dual Transfer Learning Framework
This method comes from a Google paper: A Model of Two Tales: Dual Transfer Learning Framework for Improved Long-tail Item Recommendation
The dual transfer learning mentioned in the paper name refers to model-level and item-level transfer learning. Simply put, the former makes few-shot model parameters approach many-shot model parameters (here split into two models based on sample count), while the latter makes long-tail item representations close to head items. Representations are embeddings output by the few-shot and many-shot models mentioned above. The paper’s overall framework is shown below: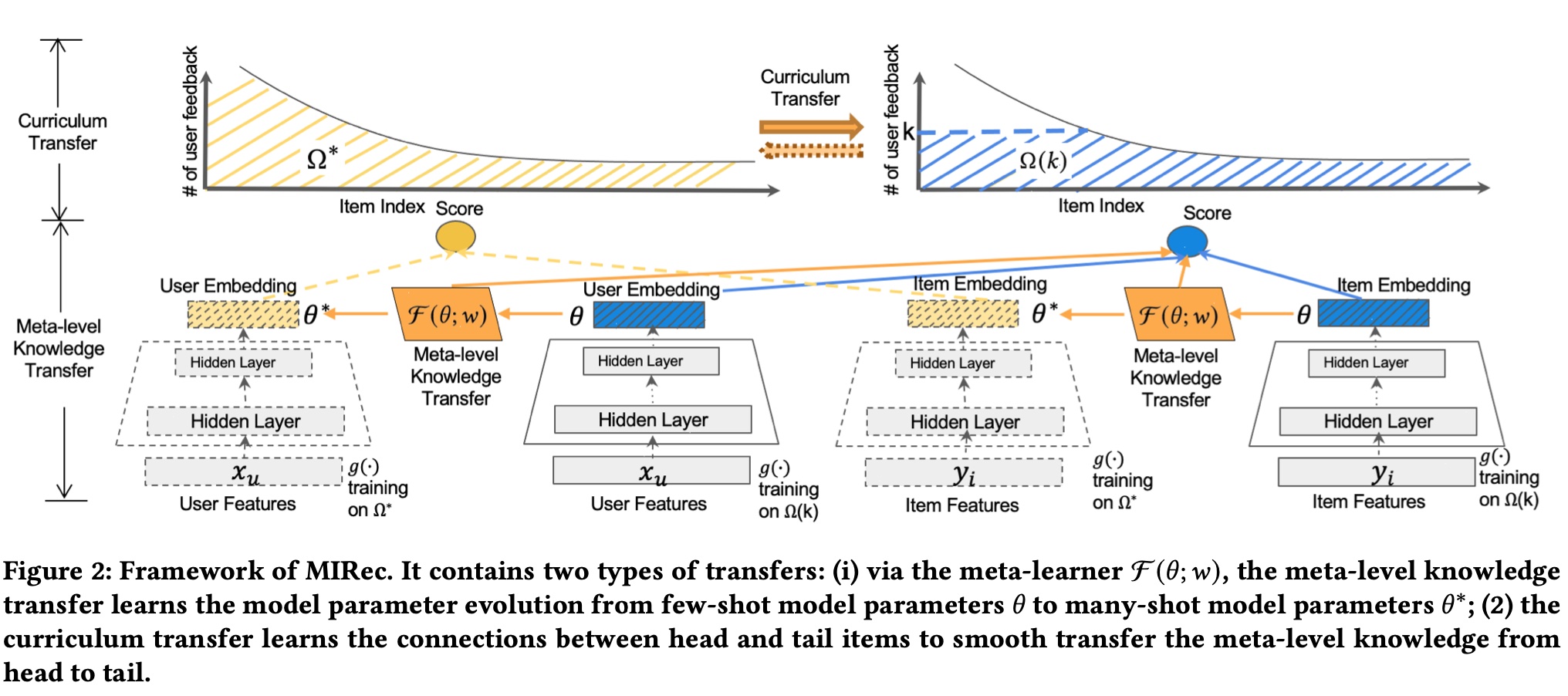
Symbol meanings in the figure:
![]()
As seen above, based on sample count, we model with many-shot and few-shot models. The core is meta-level knowledge transfer and curriculum transfer, corresponding to model-level and item-level mentioned earlier, described below.
model-level
The idea is simple: learn a meta learner \(\mathcal{F}\) whose input and output are both few-shot model parameters. The supervision signal is that output parameters should be close to many-shot model parameters, applied as a loss term.
Base learner loss is standard softmax loss, where \(r(u,i)\) is 1/0 indicating whether there’s feedback (like click):
![]()
Meta learner \(\mathcal{F}\) uses MSE loss as a regularization term added to the few-shot model’s original loss. The final few-shot model loss is formula (5):
![]()
Meta learner \(\mathcal{F}\)’s specific structure can vary; here it uses simple fully connected layers.
item-level
This part mainly trains the model through curriculum learning. Curriculum learning’s basic idea is organizing the order of samples entering the model during training. From the survey linked above:
Curriculum learning (CL) is a training strategy that trains a machine learning model from easier data to harder data, which imitates the meaningful learning order in human curricula. As an easy-to-use plug-in, the CL strategy has demonstrated its power in improving the generalization capacity and convergence rate of various models in a wide range of scenarios such as computer vision and natural language processing etc.
Back to the paper, this part mainly constructs the two training datasets: \(\Omega^{*}\) and \(\Omega(k)\):
![]()
\(\Omega(k)\) construction: contains items from two parts: items in \(I_{h}(k)\) with exactly k samples, and all samples from \(I_{t}(k)\):
![]()
The paper gives two reasons for this, but the author thinks the core is separating long-tail item samples to avoid domination by head items:
- tail items are fully trained in both the many-shot model and few-shot model to ensure the high quality of the learned item representations in both many-shot and few-shot models
(2)In the few-shot model training, the distribution of tail items relatively keeps the same as the original distribution. It can alleviate the bias among tail items that brings by the new distribution
training & serving
The overall training process is shown below, divided into two phases: phase 1 trains the many-shot model conventionally; phase 2 trains the few-shot model using many-shot model parameters and meta learner:
![]()
For serving, the scores from both models are weighted:
![]()
experiment
The paper uses 2 public datasets: MovieLens1M and Bookcrossing. Evaluation metrics are Hit Ratio at top K (HR@K) and NDCG at top K (NDCG@K). HR@K is essentially recall.
The expected goal is improving long-tail item performance without degrading overall performance. Therefore, both metrics are evaluated on all items, head items, and tail items.
The paper focuses on four questions:
RQ1: How well does the dual transfer learning framework MIRec perform compared to the state-of-the-art methods?
RQ2: How do different components (meta-learning and curriculum learning) of MIRec perform individually? Could they complement each other?
RQ3: How does our proposed curriculum learning strategy compare with the alternatives?
RQ4: Besides downstream task performance, are we actually learning better representations for tail items? Could we see the differences visually?
RQ1 compares with other SOTA methods; the paper’s method is best. Details omitted.
RQ2 is ablation: both meta-learning and curriculum learning alone are positive, and combined is best.
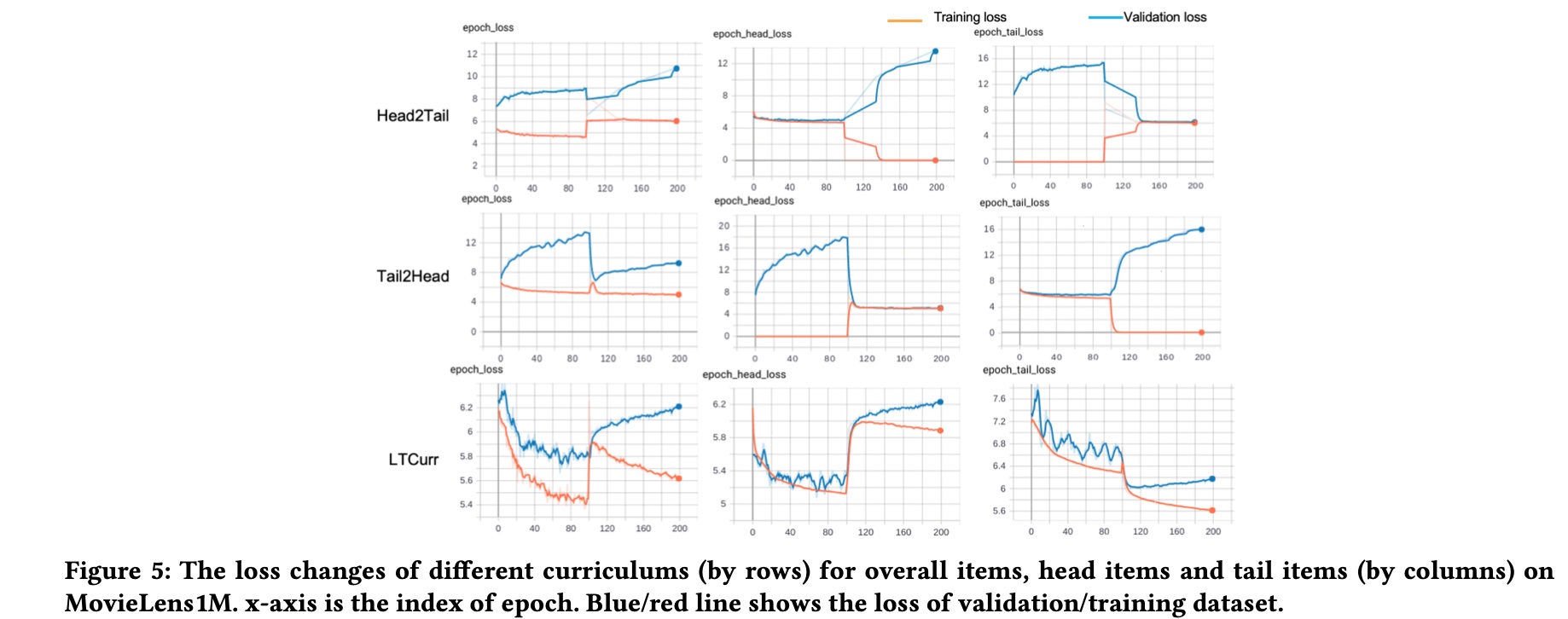
RQ3 compares different curriculum learning strategies’ effects on training and validation loss. Mainly compares head2tail and tail2head strategies. Effects shown below with conclusions:
- Compared to the tail item loss in different curriculums (column 3), our proposed curriculum can bring a two-stage decent for both the training and validation loss
- When the model is trained based on only head/tail items, the validation performance for the other part of items decreases. The different changes of head and tail loss indicate the large variations between head and tail items
- It is easily to get validation loss increases if the model is trained purely based on head/tail items, as shown in first column of the first two rows
RQ4 visualizes learned embeddings to show the method learns more distinguishable representations. Only two case studies with limited data, omitted here.
Self-supervised Learning Framework
This method comes from another Google paper Self-supervised Learning for Large-scale Item Recommendations, also addressing item long-tail problems, mainly improving representation learning. As the paper states:
The framework is designed to tackle the label sparsity problem by learning better latent relationship of item features. Specifically, SSL improves item representation learning as well as serving as additional regularization to improve generalization. Furthermore, we propose a novel data augmentation method that utilizes feature correlations within the proposed framework.
SSL Framework
The paper’s overall framework is shown below. Symbol meanings are in the figure caption:
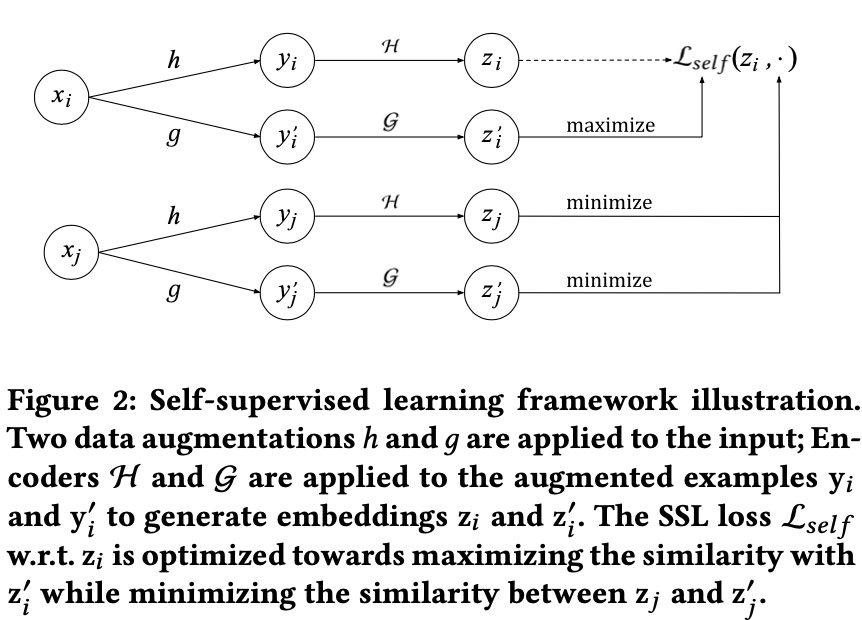
\(x_i\) and \(x_j\) represent two samples in a training batch (samples in recommendation can have three meanings: query/item/query-item pair; here specifically items). The core idea is the same sample should have similar representations after different transformations, while different samples should be dissimilar.
Therefore, in the representations obtained through \(h, g, \mathcal{H}, \mathcal{G}\), \((z_i, z_i^{'})\) is a positive pair, \((z_i, z_j^{'})\) is negative. For a batch with \(N\) samples, the self-supervised loss for sample \(i\) is:
\[\begin{align} \mathcal{L}_{self}(x_i) = -\log \frac{\exp(s(z_i, z_i^{'})/\tau)}{\sum_{j=1}^{N}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
\(\tau\) is a hyperparameter (softmax temperature), \(s(z_i, z_j^{'})\) is cosine similarity: \(s(z_i, z_j^{'})=< z_i, z_j^{'}>/(||z_i|| \cdot ||z_j^{'}||)\).
The overall batch self-supervised loss:
\[\begin{align} \mathcal{L}_{self}(\lbrace x_i \rbrace; \mathcal{H}, \mathcal{G}) = - \frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(s(z_i, z_i^{'})/\tau)}{\sum_{j=1}^{N}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
The two encoders \(\mathcal{H}\) and \(\mathcal{G}\) share parameters in the paper (mentioned in model structure later).
If both data augmentation methods \(h\) and \(g\) are the same, the loss degenerates to:
\[\begin{align} -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(1/\tau)}{ \exp(1/\tau) + \sum_{j \ne i}\exp(s(z_i, z_j^{'})/\tau)} \end{align}\]
The objective is to make different samples’ similarity \(s(z_i, z_j^{'})\) as small as possible.
two-stage data augmentation
Here we describe the two data augmentation methods \(h\) and \(g\). The paper states the key is: A good transformation and data augmentation should make minimal amount of assumptions on the data such that it can be generally applicable to a large variety of tasks and models.
The paper uses masking, borrowing from BERT, but without sequence concepts, so masking item features. Actual implementation is two-stage: masking + dropout:
Masking. Apply a masking pattern on the set of item features. We use a default embedding in the input layer to represent the features that are masked.
Dropout. For categorical features with multiple values, we drop out each value with a certain probability. It further reduces input information and increase the hardness of SSL task.
For specific masking, the paper doesn’t use random masking but masks based on mutual information between features. Core idea is masking highly correlated features, because the SSL contrastive learning task may exploit the shortcut of highly correlated features between the two augmented examples, making the SSL task too easy.
Specifically, randomly select a feature \(f_{seed}\) each time, then use precomputed mutual information to select the most correlated \(k/2\) features with this feature. Finally mask these \(k/2 + 1\) features.
training & serving
The self-supervised loss \(\mathcal{L}_{self}(\lbrace x_i \rbrace)\) is only an auxiliary loss.
The main task loss computes query-item loss using batch softmax loss, same form as self-supervised loss but computing query-item similarity instead of item-item:
\[\begin{align} \mathcal{L}_{main} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(s(q_i, x_i)/\tau)}{\sum_{j=1}^{N}\exp(s(q_i, x_j)/\tau)} \end{align}\]
Total loss:
\[\begin{align} \mathcal{L} = \mathcal{L}_{main} + \alpha \mathcal{L}_{self} \end{align}\]
The final model is shown below. Note the 3 item towers share parameters: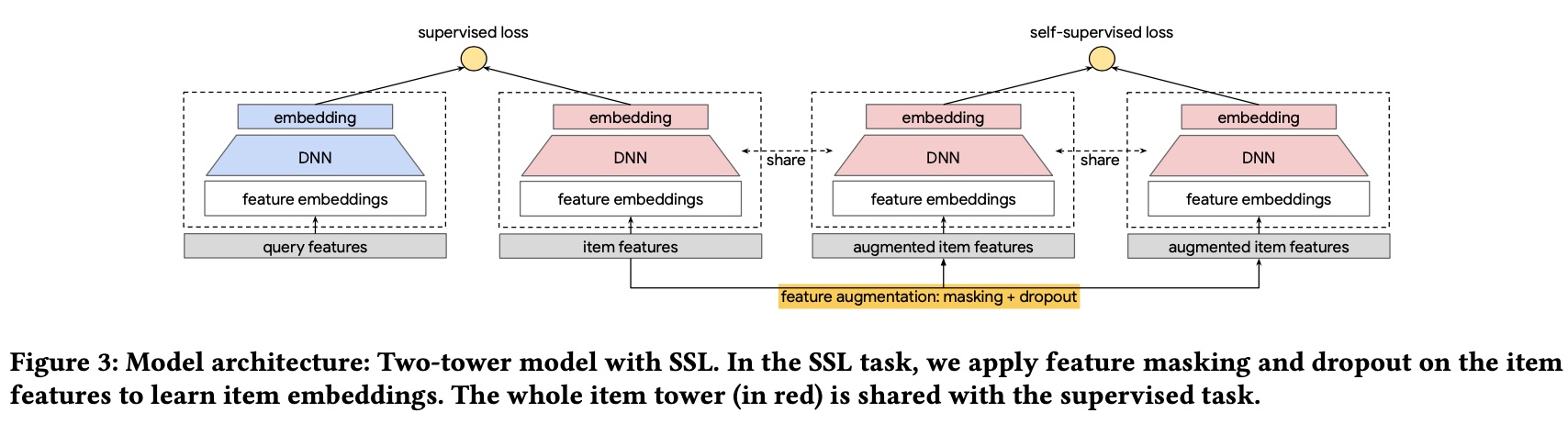
For serving, since we only added an auxiliary loss, normal prediction works.
experiment
The paper answers 4 questions:
RQ1: Does the proposed SSL Framework improve deep models for recommendations?
RQ2: SSL is designed to improve primary supervised task through introduced SSL task on unlabeled examples. What is the impact of the amount of training data on the improvement from SSL?
RQ3: How do the SSL parameters, i.e., loss multiplier \(\alpha\) and dropout rate in data augmentation, affect model quality?
RQ4: How does RFM perform compared to CFM? What is the benefit of leveraging feature correlations in data augmentation?
RQ1 compares with 3 baselines on 2 public datasets using MAP@10/50 and Recall@10/50, evaluated on all/head/tail items like the previous paper.
RQ2 answers data amount’s effect on SSL: more data is better. This seems intuitive; unclear why the paper mentions it separately.
RQ3 answers \(\alpha\)’s effect. Comparing spread-out regularization loss with paper’s self-supervised loss, same \(\alpha\) values show self-supervised loss is better. spread-out regularization loss is also a contrastive loss but without data augmentation.
RQ4 answers whether random mask (RFM) or correlation-based mask (CFM) is better: CFM outperforms RFM on all four metrics.
Additionally, the paper includes online A/B experiments with significant results.
Summary
This article introduces two papers addressing long-tail problems at the model level. Both papers’ core idea is better learning long-tail item representations.
The first proposes a dual transfer framework (model-level + item-level), using two models for head and tail items separately. At model level, tail item model parameters learn from head item model; at item level, curriculum learning organizes sample order. Serving requires fusing both models’ predictions.
The second proposes a self-supervised learning framework, using in-batch data augmentation (mask + dropout) to add an auxiliary loss, making the same item’s embedding similar after transformation while different items are dissimilar. Both offline and online experiments validate effectiveness.
The author feels in industry, the first method has higher cost than the second, and the first didn’t do online A/B experiments so online effectiveness is unknown. The second method’s self-supervised learning through in-batch sample pairs is more universally applicable.
Besides recommendation, there’s a CV survey on long-tail problems: Deep Long-Tailed Learning: A Survey, with more comprehensive methodology covering both papers above. But CV differs significantly from recommendation (e.g., recommendation typically has many more items than CV), so actual business application is uncertain, not detailed here.