A Survey of Multi-Domain Learning
In practical business scenarios, data often consists of multiple domains. Taking advertising as an example, there are often multiple conversion targets, and when predicting CTR and CVR, the influence of different conversion targets must be considered, because the distributions (such as mean and variance) of CTR and CVR are often inconsistent across different conversion targets.
The most intuitive approach to this problem is to add domain-related features or split models by domain. The former is an implicit method that requires features to be sufficiently distinctive and learnable by the model, but there’s no quantitative standard for “sufficiently distinctive,” so we basically have to rely on experimental results. The latter has the problem of high maintenance cost—for example, with n domains, you’d need n separate models.
This article focuses on methods to serve multiple domains with a single model, mainly covering work that has been validated in industry and publicly published. These methods can generally be categorized into three types:
- Multi-head structure
- LHUC mechanism
- GRL mechanism
MMOE
Splitting into multiple heads within a single model (where each head represents a domain) and learning domain-specific distributions through each head’s parameters is a relatively intuitive and common approach.
The representative of this class of methods is MMOE: Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
The figure below intuitively demonstrates several common approaches to splitting heads:
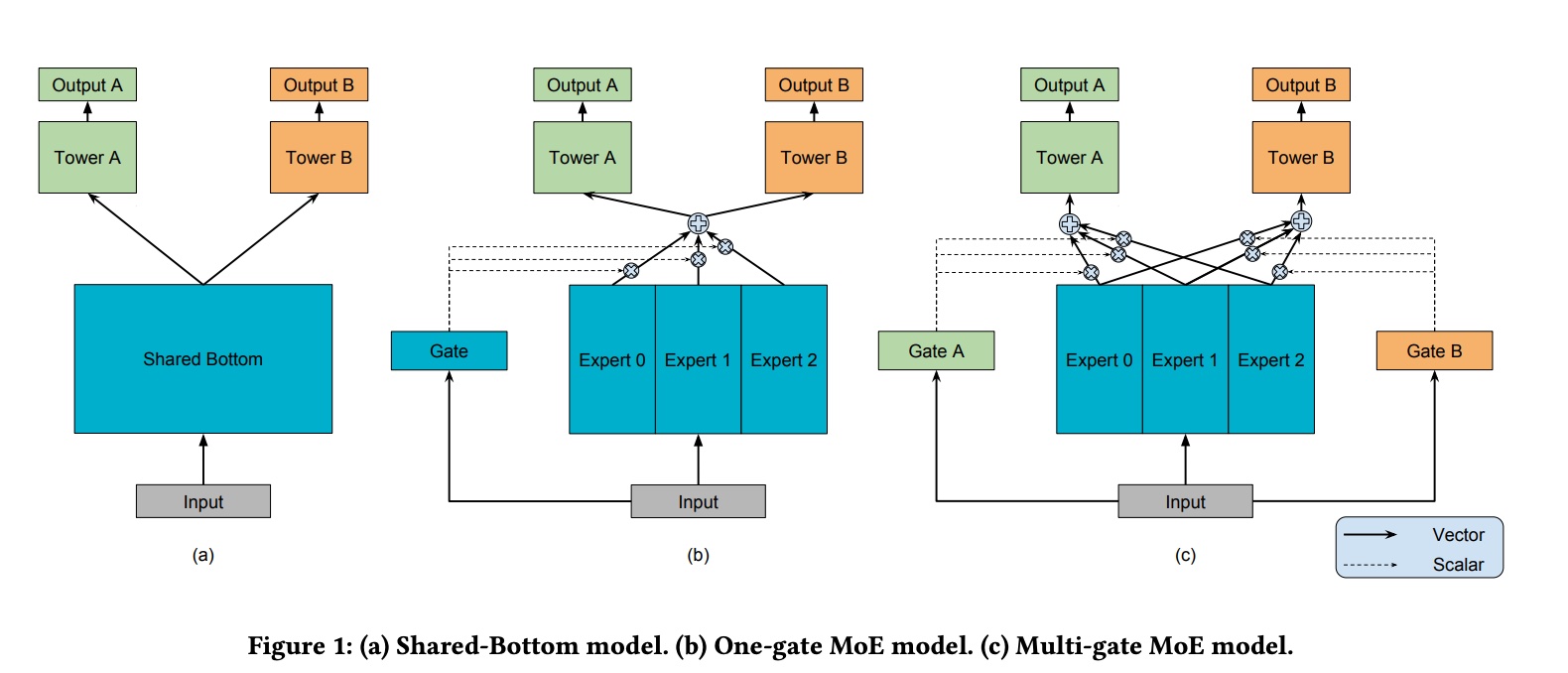
The two M’s in MMOE stand for multi-gate and multi-expert respectively. Multi-expert is easy to understand—from an ensemble perspective, it’s doing bagging. The gate controls the weight of each expert, and multi-gate assigns a separate gate for each expert, essentially achieving domain-wise optimization.
The gate is also implemented as an MLP, ultimately obtaining the weight of each expert through softmax. For the k-th task, the calculation process is shown below:

STAR
This is a paper from Alibaba, applied in a typical CTR prediction scenario: One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
In terms of model structure, it also allocates separate parameters for each domain to serve multiple domains within a single model. This principle is the same as MMOE. The paper states:
Essentially, the network of each domain consists of two factorized networks: one centered network shared by all domains and the domain-specific network tailored for each domain
The basic structure of STAR is shown in figure (b) below. Intuitively, there is a shared head and a separate head for each domain. The final parameters for each head are the element-wise product of the shared head parameters and the domain head parameters.
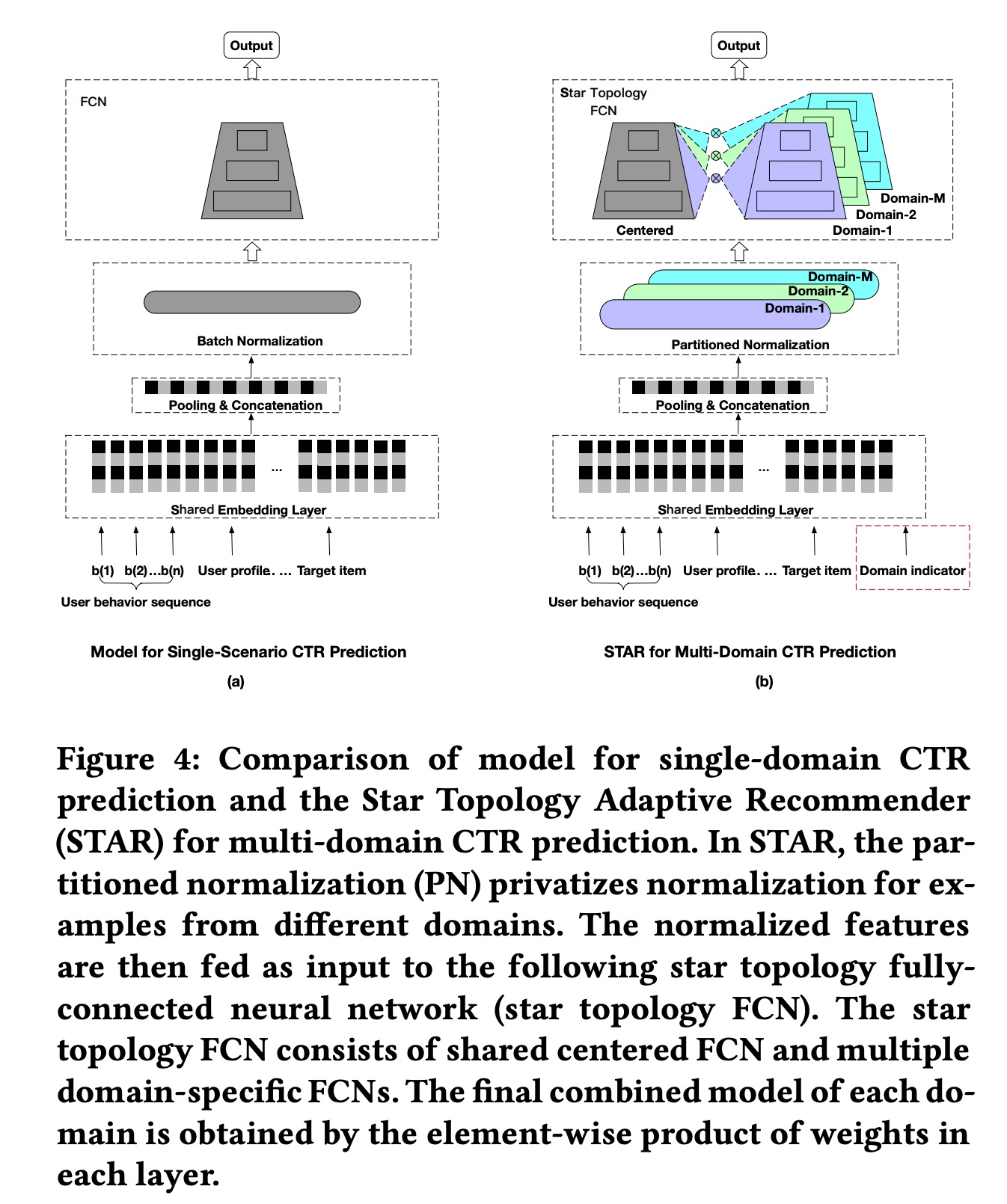
- Partitioned Normalization (PN)
In the structure above, there is a Partitioned Normalization (PN) component, designed to address the issue where standard batch normalization is not suitable for multi-domain scenarios.
Conventional batch normalization calculates the mean and variance of all samples in a batch, then normalizes. This assumes the samples are independent and identically distributed (i.i.d.), but multi-domain learning specifically addresses the problem that different domains have different distributions, so standard batch normalization cannot be directly applied. For more on why BN is effective, see: Rethinking “Batch” in BatchNorm

PN’s approach is to generate additional domain-specific parameters for the original BN parameters \(\gamma\) and \(\beta\), as shown below:

- Auxiliary Network
This is a small network whose input is the domain indicator (indicating which domain this sample comes from), and the output is a prediction value. The final prediction is added to the STAR model’s output. This is equivalent to adding a bias term for each domain.

The experimental results are not elaborated here. The paper shows better results than some existing multi-domain methods (whether parameter counts are matched is not mentioned). Ablation studies on PN show that PN performs better than directly using BN.
LHUC
The previous two articles both follow the basic idea of allocating separate head parameters for different domains, then using different heads to describe differences between domains.
The LHUC paper does not explicitly split heads, but achieves a similar effect by multiplying a domain-aware embedding on hidden layers: Learning Hidden Unit Contributions for Unsupervised Acoustic Model Adaptation
This paper was originally proposed in the speech domain. The basic idea is to adjust part of the parameters in the fully connected layers of the NN for each speaker, achieving personalized prediction for each speaker. The overall idea is quite intuitive and can easily be migrated to recommendation scenarios.
Kuaishou’s PEPNet (Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information) also borrows this idea from LHUC.
The overall model structure is shown below. The LHUC part is the PPNet on the far right, where each GateNU generates a domain-aware embedding for each hidden layer. The EPNet on the left generates similar embeddings for different embeddings.
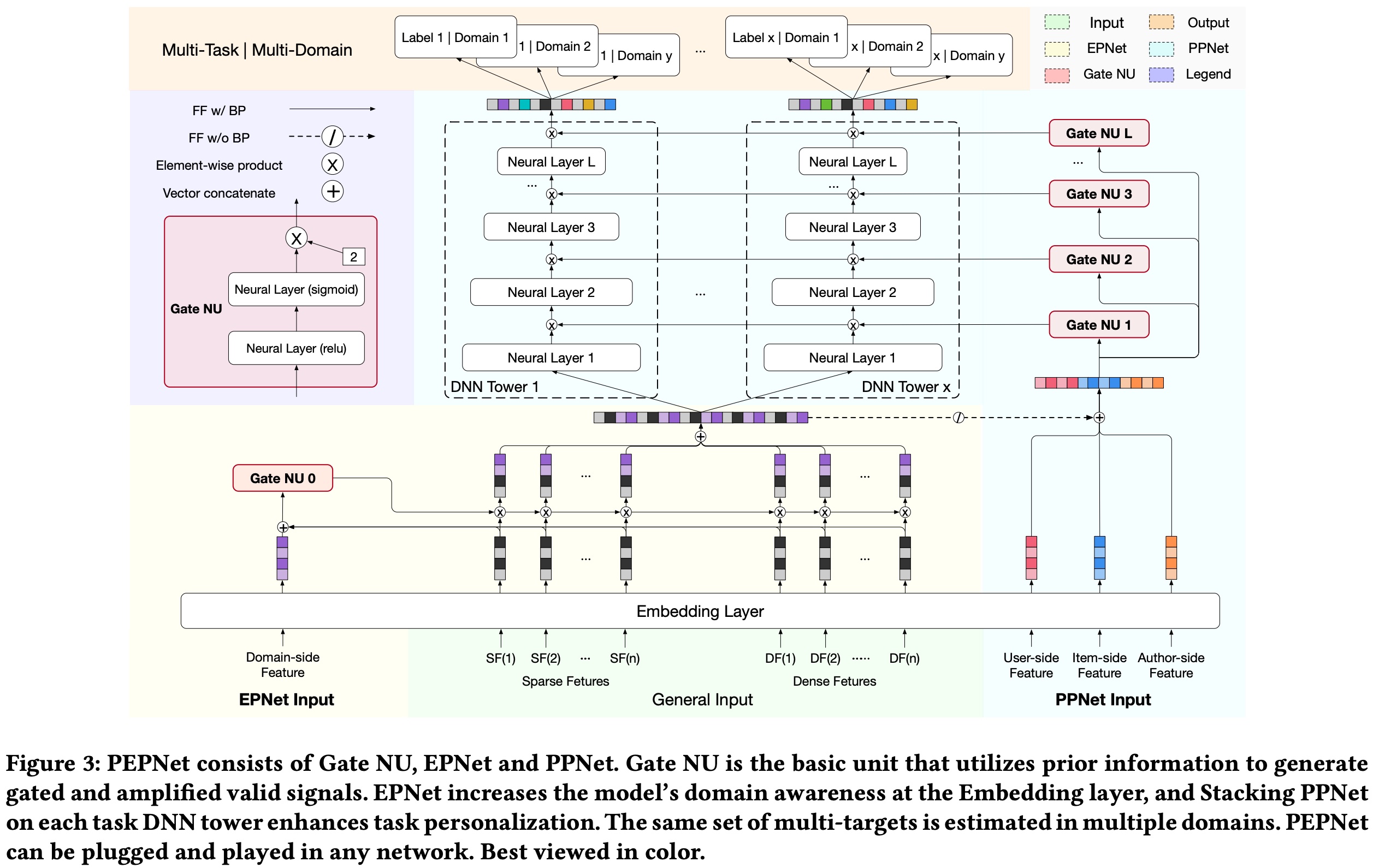
Gate NU can be understood as a simple two-layer NN network. The input is features selected based on prior knowledge that can distinguish different domains, and the output is a tensor (with the same dimension as the hidden layer).


Besides structural improvements, this paper also made several engineering optimizations, which are not detailed here.
GRL
Here we mainly want to introduce the GRL (Gradient Reversal Layer) mechanism, from the paper Unsupervised Domain Adaptation by Backpropagation
The paper mainly addresses the domain adaptation problem: when we have abundant data in the source domain but limited data in the target domain, how can we effectively solve both domains’ problems? The paper’s solution approaches this from the feature level.
the approach promotes the emergence of “deep” features that are (i) discriminative for the main learning task on the source domain and (ii) invariant with respect to the shift between the domains.
To achieve this goal, the paper proposes the GRL mechanism shown below:
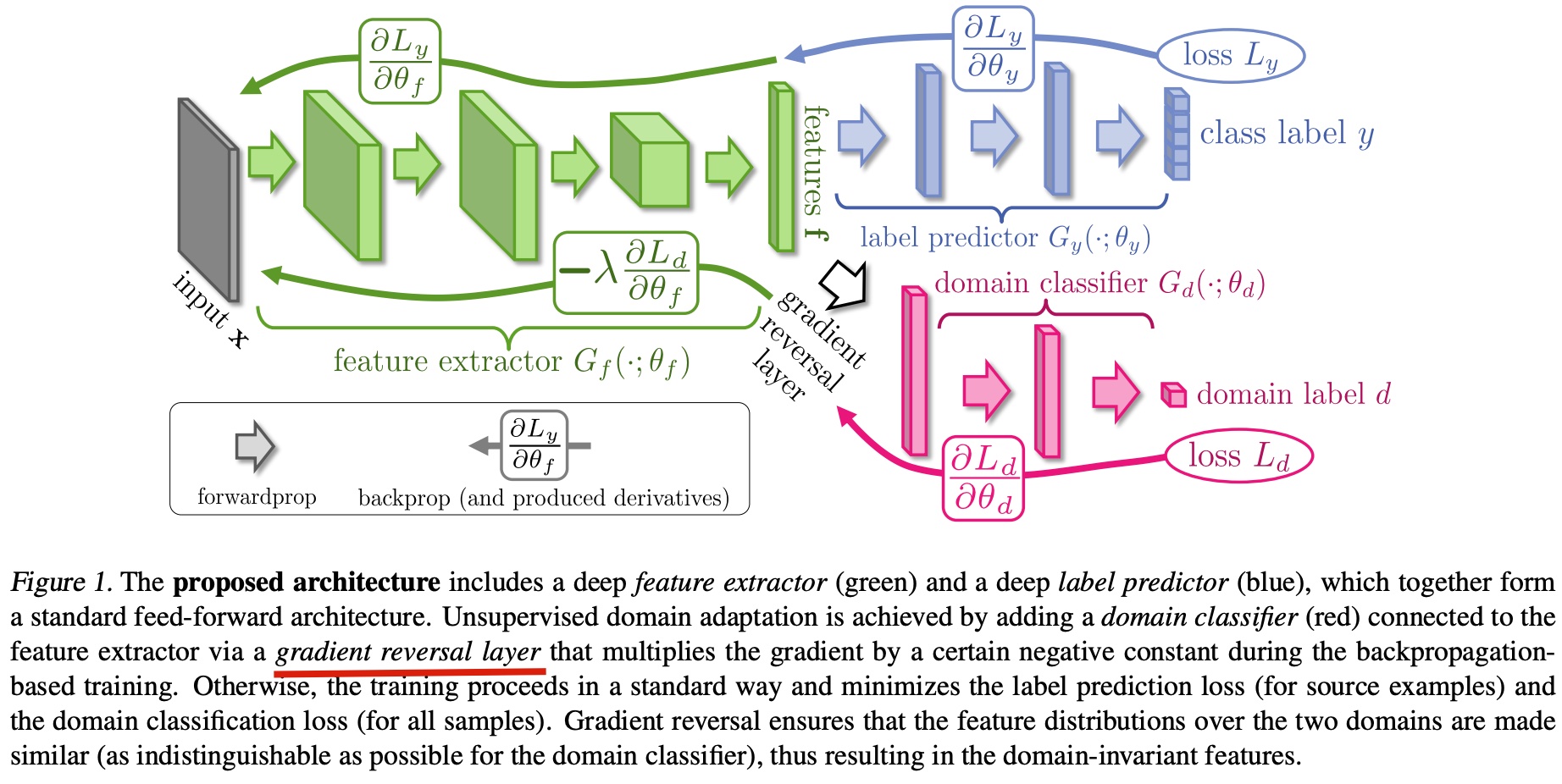
Structurally, this is also a multi-head structure. The blue head is the original task for the source domain, and the red head (hereafter referred to as discriminator) is a domain classifier, used to distinguish which domain a sample belongs to.
During backpropagation, the blue head backpropagates gradients normally, while the discriminator multiplies a negative constant when gradients are backpropagated to the feature extractor (the green part). This is the GRL mechanism.
Why do this? The paper explains:
we want to make the features \(f\) domain-invariant. That is, we want to make the distributions \(S(f) = \lbrace G_f(x;\theta_f)|x∼S(x) \rbrace\) and \(T(f) = \lbrace G_f(x;\theta_f)|x∼T(x) \rbrace\) to be similar. Under the covariate shift assumption, this would make the label prediction accuracy on the target domain to be the same as on the source domain (Shimodaira, 2000).
That is, we want the features extracted by the feature extractor to be domain-invariant, insensitive to domain, or equivalently, the discriminator cannot well distinguish which domain a sample comes from based on the extracted features.
Without GRL, normal backpropagation would enable the discriminator to distinguish which domain a sample comes from. Adding GRL achieves the goal mentioned above: “the discriminator cannot well distinguish which domain a sample comes from.”
Another question: why do this at the feature extractor layer rather than adding a negative sign at \(L_d\)?
Because if we directly add a negative sign at \(L_d\), this would make the discriminator classify to the wrong domain, but a good feature should make the discriminator unable to distinguish which domain it comes from, not classify it to the wrong domain.
Therefore, the GRL mechanism is also a type of feature engineering, used to extract features suitable for multiple domains.
Summary
In summary, this article mainly introduces three approaches to solving multi-domain problems: multi-head structure, LHUC mechanism, and GRL mechanism. As far as the author knows, all these approaches have been deployed in industry and are worth trying in relevant business scenarios.
The multi-head mechanism is quite intuitive, allocating a separate head for each domain to learn different domain distributions. MMOE and STAR belong to this category. The LHUC mechanism selects a batch of discriminative features based on prior knowledge, learns a latent variable through a small NN and applies it to hidden layers (it can also be applied to embeddings; EPNet in PEPNet does this, with similar principles). GRL makes features extracted by the model domain-invariant through training, similar to the adversarial training idea in GAN.