Large Language Model Technical Reports Overview
This Spring Festival, DeepSeek pushed large language model discussion to new heights. Even in an 18-tier small town’s New Year atmosphere, unexpected technological ripples were hidden. My cousin shouts dialect at her phone “Write me a New Year greeting”, my nephew chats with Douba’s gentle, understanding “school beauty”, even the alley’s Spring couplet vendor learned to customize gold-patterned designs with generative AI - these digital ripples in daily life, like a silent enlightenment movement, wove “large language models” into this small town’s capillaries.
Two years ago AI was like a bronze giant statue, trembling with computational roar when ingesting data, only able to process stellar data in first-tier city data centers. Today’s large models have become flowing streams, infiltrating along 5G base stations into county auto repair shops’ QR scan systems, kneaded into Kuaishou streamers’ dialect scripts, even hibernating in elderly phones’ voice assistants coughing once to remind medication. From “brute force aesthetics” hundred-billion parameter arms race, to MoE architecture deftly slicing computational cake, from millions-of-dollars lab aristocracy, to DeepSeek-R1 tearing open commoner admission with $6M training cost - this evolution isn’t just technological leap, but metaphor for tech narrative shifting from “monologue from the altar” to “dialogue with humanity”: when large models learn cost-optimized ballet on GPU remains, technology’s capillaries finally touched daily life’s heartbeat.
The passage above was generated by DeepSeek without complex prompts or repeated debugging - DeepSeek just “effortlessly” generated poetic yet realistic text. What’s more terrifying is this isn’t even DeepSeek-R1’s main selling point: low-cost yet o1-comparable reasoning capability.
After using it for a while, compared to two years ago, large models indeed have much improved user experience, no longer rigid text permutation machines. Besides well-known data + compute “brute force” techniques, what technological advances and innovations occurred? The podcast 89. Line-by-line Explanation of DeepSeek-R1, Kimi K1.5, OpenAI o1 Technical Reports I recently listened to introduces three representative large model reports. This article is a written version after learning. Hope you find it worthwhile!
OpenAI-o1
The report was released September 12, 2024: Learning to reason with LLMs. It mainly details that o1 performs very well on various benchmarks (much better than GPT-4o).
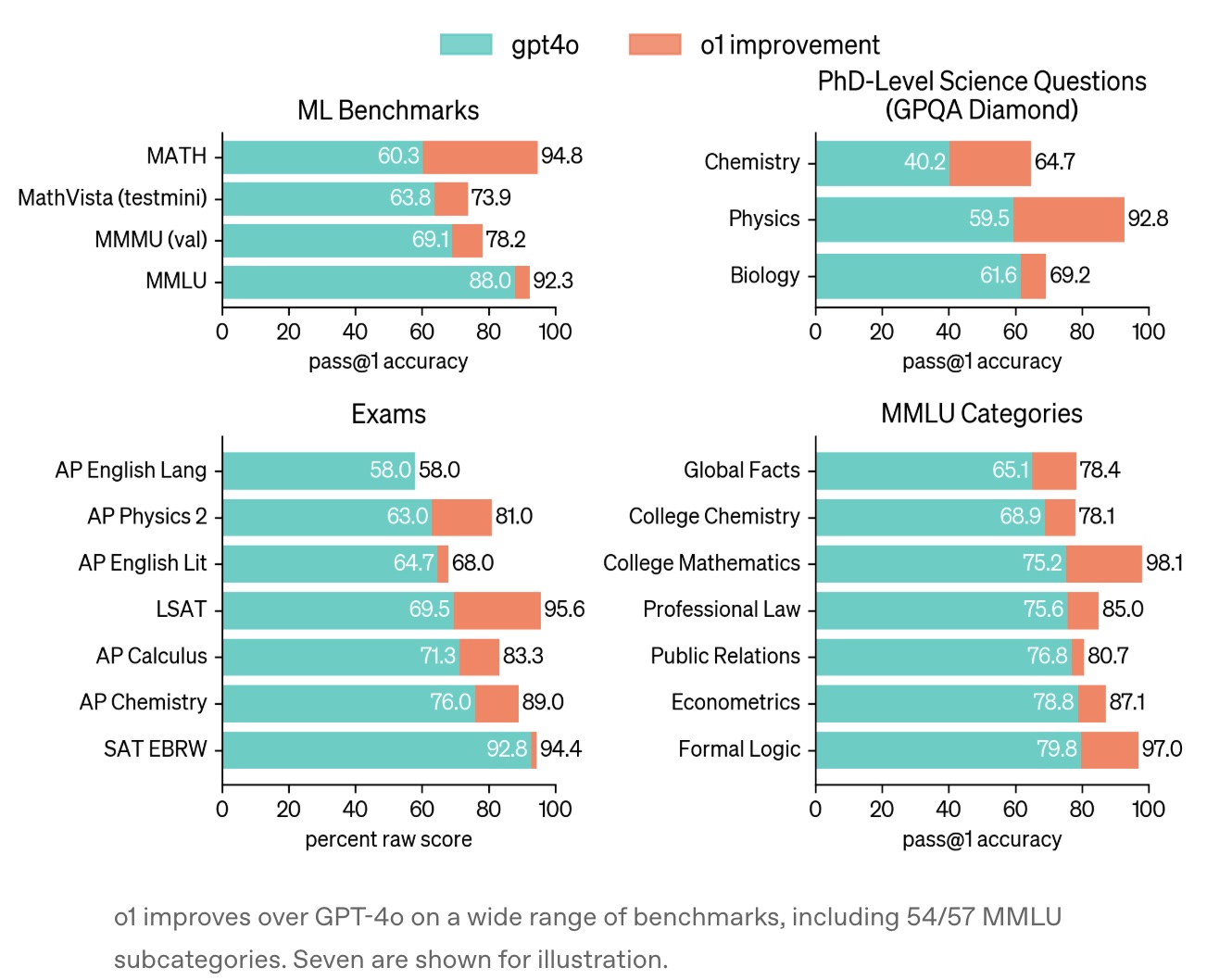
Chain of Thought (CoT) should be one of the biggest improvements in reasoning models compared to two years ago. Simply, before generating answers, the model does extended internal thinking, improving answer quality through multi-step reasoning, error correction, and strategy adjustment. This mechanism is similar to human “System 2” slow thinking, significantly improving logical rigor.
The report states “This process dramatically improves the model’s ability to reason”:
It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working.
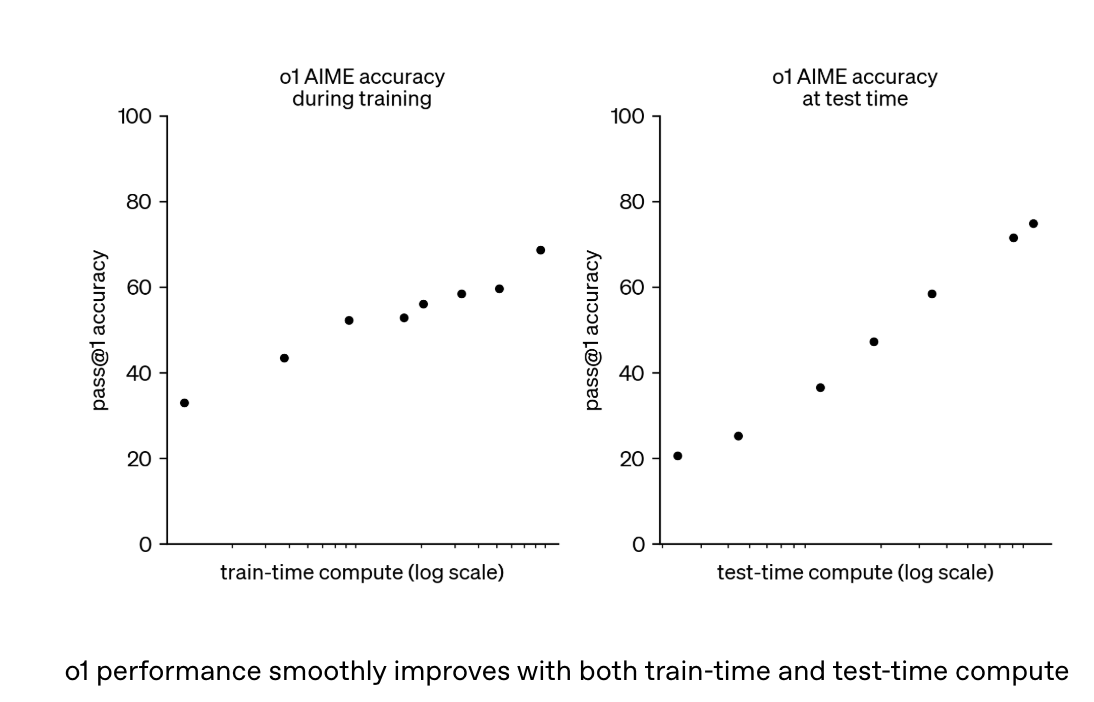
Chain of thought’s underlying technology is reinforcement learning. The report shows this capability continuously improves with increased training compute and inference thinking time, showing “Inference Scaling Law” similar to AlphaGo, also similar to LLM pretrain stage’s scaling law with increasing data:
The report does extensive performance benchmarks showing CoT advantages. But o1’s thinking process isn’t externally visible, only showing summaries. OpenAI considers this helpful for monitoring model safety (like preventing user manipulation).
As for specific implementation algorithm details, OpenAI’s report doesn’t reveal much (after all, it’s closedAI now…). External speculation at the time was mostly based on Process Reward Model (PRM), providing fine-grained supervision for each reasoning step rather than just final result (ORM). PRM was mentioned in OpenAI’s earlier paper Let’s Verify Step by Step - simply ORM only provides feedback on final result, PRM provides feedback per step. The report shows this significantly outperforms outcome supervision when training models to solve MATH dataset problems.
But DeepSeek’s report below shows PRM faces implementation challenges in practice - an unsuccessful attempt.
OpenAI’s report is very short with little effective information (after all, it’s closedAI now…).
DeepSeek
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning introduces DeepSeek-R1-Zero and DeepSeek-R1 models.
DeepSeek-R1-Zero directly applies large-scale RL training on base model without SFT (Supervised Fine-Tuning). This was considered common sense in LLM, traceable to deep learning’s 2016 emergence: fine-tuning pre-trained model parameters on specific task labeled data to optimize performance on that task.
This is the first public research report showing LLM reasoning capability can achieve good results through pure RL. More importantly, it provides clearer solution approach for various teams working on o1’s puzzle. As the paper states: “it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area”.
Before discussing the RL algorithms in the report, let’s review the widely-cited RLHF (Reinforcement Learning from Human Feedback) process, then understand DeepSeek’s related improvements.
RLHF
RLHF has 3 stages: SFT, RM, and RL, as shown below (image from What is RLHF?):
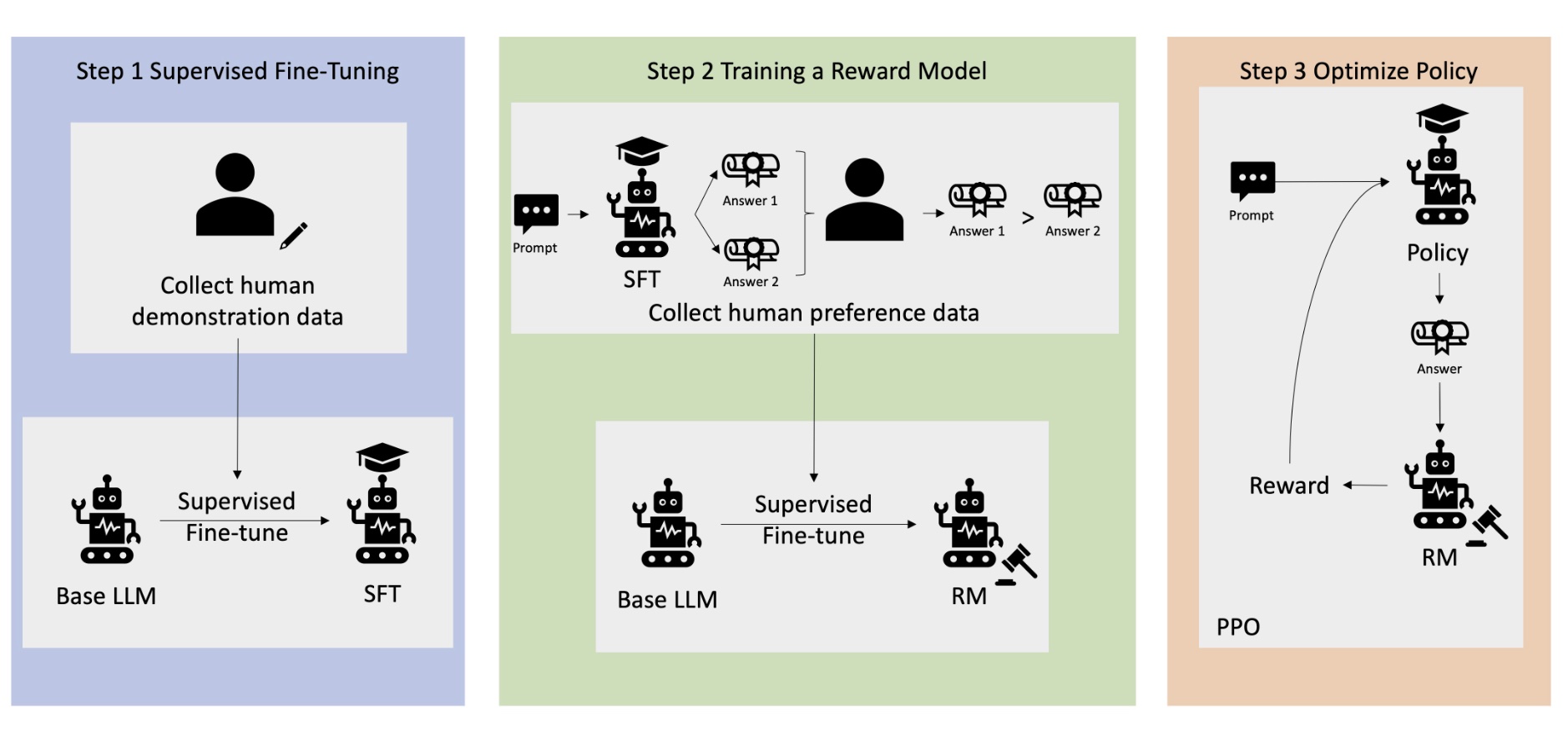
(1) Supervised Fine-Tuning (SFT) Stage
This is the SFT process mentioned above, adjusting pre-trained model based on annotated data to initially adapt to specific tasks (like dialogue, instruction following).
Specifically, fine-tune pre-trained model using high-quality human-annotated data (like human-written Q&A examples). Training method similar to pretraining, using autoregressive next-token prediction objective (like cross-entropy loss).
(2) Reward Model (RM) Stage
This stage builds a scoring model simulating human preferences, quantifying generated content quality.
Specifically, have SFT model generate multiple answers to same instruction, with humans ranking or scoring preferences. This process is also where improving model safety (avoiding harmful content) and value alignment (matching ethical preferences) relies on human correction.
Then modify output and loss function (e.g., contrastive loss, pairwise ranking loss) on original base model, training a regression model (RM) that takes instruction and answer, outputting scalar reward value.
(3) Reinforcement Learning (RL) Stage
Final stage uses RM’s reward signal to optimize SFT model to generate higher-reward responses, adjusting model parameters through RL algorithms (like DPO, GRPO, PPO) to maximize expected reward.
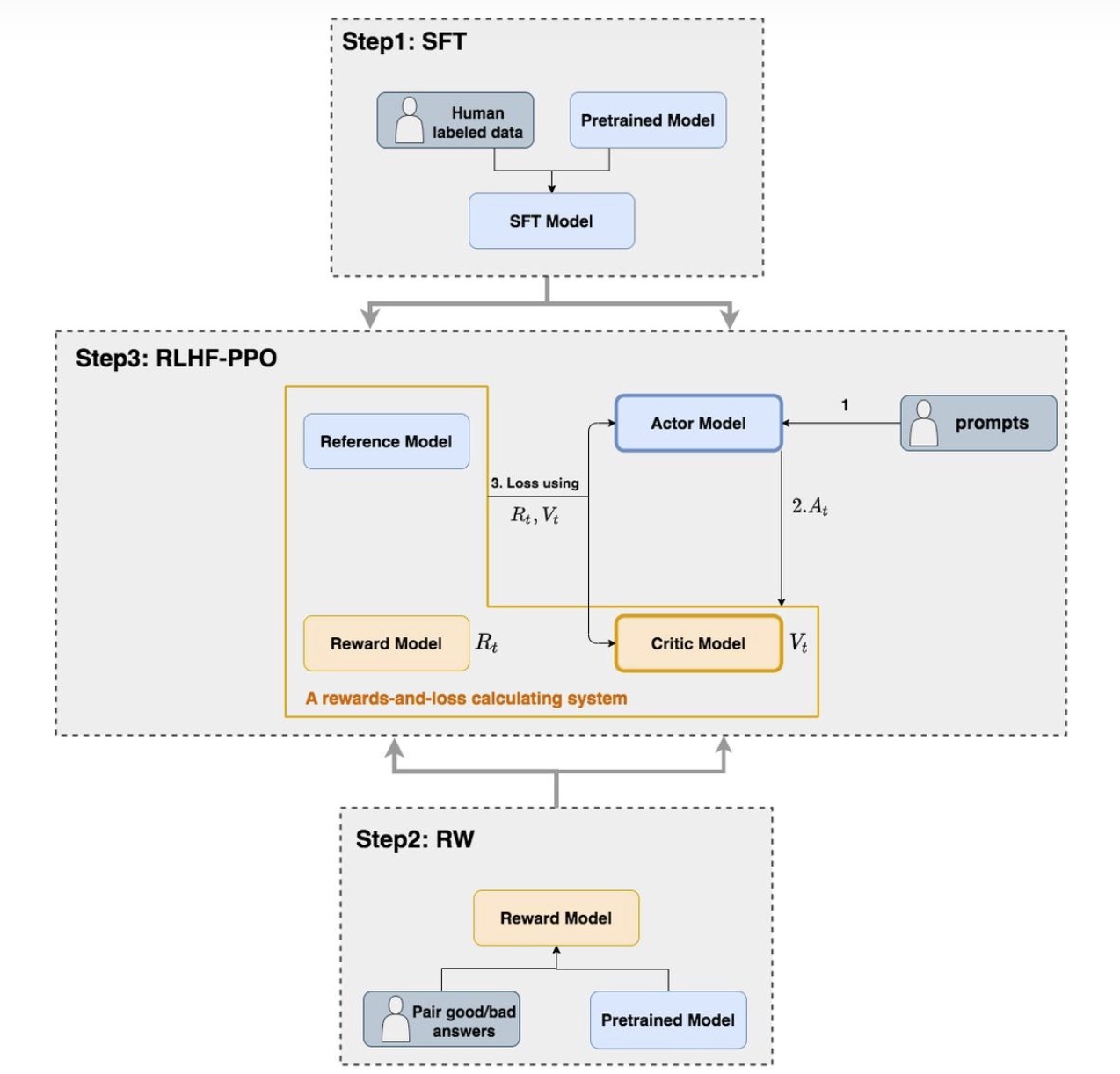
Taking PPO (Proximal Policy Optimization) as example, RL stage main process is Step 3 below:
Let me focus on original PPO algorithm. PPO is a policy-based algorithm. Let me briefly introduce RL’s two main technical paradigms: policy-based and value-based.
Value-based methods focus on learning a precise value function to evaluate expected return from executing action a in state s. When executing action, choose action with highest value. Common methods like Q-learning or DQN. Q-learning’s Q-table or DQN’s Q-network record or fit this value function. Former can be understood as intuitive score table, latter fits this table through NN. These methods generally only apply to finite action count (discrete) scenarios. Q-table also often limits finite states due to storage limits.
Policy-based methods focus on learning a policy function, directly outputting selected action based on estimated action probability distribution. Policy-based methods support both discrete and continuous action spaces.
For discrete action spaces, easy to understand - softmax normalizes n actions to probability distribution summing to 1, then select highest probability (this is also DQN’s approach).
For continuous action spaces, model outputs probability distribution parameters. Common approach assumes actions follow Gaussian distribution - model outputs mean \(\mu\) and standard deviation \(\sigma\) parameters, and agent randomly draws a value from \(N(\mu, \sigma^2)\) as actual executed action. Model learning goal is adjusting \(\mu\) (moving distribution center toward good actions) and \(\sigma\) (adjusting exploration certainty). This scenario typically uses NLL (Negative Log-Likelihood) loss, essentially MLE thinking, but unlike common binary classification MLE without absolute ground truth, using environment feedback’s specific reward to determine final gradient weight.
Policy-based methods often involve policy gradient concept, basically same as ML’s backpropagation gradient, can be understood as weighted gradient. For discrete space, it’s a multi-class task, just with additional reward multiplier in traditional multi-class backpropagation. Physical meaning is increasing probability for high-reward actions, decreasing for low-reward.
Back to PPO algorithm - PPO uses Actor-Critic architecture. PPO has 4 models: Actor Model, Critic Model, Reward Model, and Reference Model.
Reward Model and Reference Model are modules unique to RLHF in LLM scenario. Native PPO (for robots, games) doesn’t have these because in traditional RL (like playing Mario), environment directly gives Reward (coin +1). But for LLM generating text, environment (user) doesn’t immediately score. So we need to simulate environment - Reward Model does this, providing environmental reward for Actor model. Reference Model, as the name suggests, prevents model deviating too far from original parameters, comparing distribution difference with current Actor model output, penalizing excessive distribution change through KL divergence.
- Actor Model (Policy Model)
This model generates LLM output (like response in dialogue), main training target. Usually initialized from SFT model above, then updates parameters through policy gradient, maximizing reward signal while avoiding deviation from Reference Model.
- Reference Model
Also initialized from SFT model, parameters are fixed and not updated, equivalent to Actor’s initial version. Used for computing KL divergence constraint (distribution difference between current Actor and Reference outputs), preventing Actor from over-deviating from original distribution during training, mitigating reward hacking and catastrophic forgetting.
Reward hacking mainly means model deviating from reasonable policy (like fabricating false info) to increase reward score. Catastrophic forgetting means model losing general knowledge from pretraining when optimizing new tasks. Both are addressed through KL divergence constraining Actor-Reference output difference.
- Reward Model
This model is trained in stage (2) above, providing real-time reward signal for generated response. Training through contrastive learning on human-annotated preference pairs. Like Reference Model, parameters are frozen during training process.
- Critic Model
Reward Model predicts immediate benefit (current action’s benefit), Critic Model predicts current state’s long-term benefit. Critic Model’s important role is smoothing gradients, because if only using final Reward to update, gradient variance would be very large (a sentence written well might just be luck).
Critic Model output mainly computes Advantage Function, guiding Actor optimization direction. The “advantage function” mentioned computes differently for specific RL algorithms, but core idea is measuring specific action’s quality relative to policy’s average performance. In PPO, advantage function definition:
\[A(s,a)=Q(s,a)−V(s)\]
- \(V(s)\): State-Value Function, average expected return executing all actions under current policy in state s (in PPO, estimated by Critic Model for current moment’s future expected reward)
- \(Q(s, a)\): Action-Value Function, expected total return after executing action a in state s (including future reward discounting). In PPO, sum of Reward Model’s immediate reward and Critic Model’s next moment future reward.

When \(A(s,a)>0\), action a outperforms average, vice versa.
For why this function has this form, Everyone Can Understand RL-PPO Theory gives intuitive example (highly recommend reading this article):

Critic Model’s role is similar to Reward Model (in fact, later GRPO algorithm removes Critic Model), but Critic Model parameters are updated. Since predicting value, update method uses MSE-like loss to minimize actual-predicted return difference.
Therefore, one PPO training round:
- Actor generates response based on current policy
- Reference Model computes KL divergence (prevent drift), Reward Model gives final raw score. Final Reward = RM score - KL penalty
- Critic Model observes every state during generation, outputting predicted \(V(s)\) values
- Actor computes advantage function \(A(s,a)\) through step 2’s “final Reward” and step 3’s \(V(s)\) values, updates Actor parameters through PPO-Clip mechanism
- Critic also adjusts own parameters based on error between actual return and predicted value
For Actor Loss and Critic Loss, see Illustrating Large Model RLHF Series: Everyone Can Understand PPO Principles and Code Interpretation with code examples.
DeepSeek-R1-Zero: Pure RL with GRPO
Although Actor-Critic paradigm in PPO above seems reasonable, Critic training accuracy can’t be guaranteed, so when value function isn’t accurate, using wrong value estimate is worse than abandoning it directly.
Group Relative Policy Optimization (GRPO) does exactly this. GRPO is an RL algorithm proposed in DeepSeek-v2. As mentioned earlier, Critic Model role is similar to Reward Model, and in GRPO, Critic Model is removed. How does GRPO work? Simply, through multiple sampling of same problem’s different answers, directly using in-group reward statistics (like mean, variance) to compute relative advantage. GRPO vs PPO:
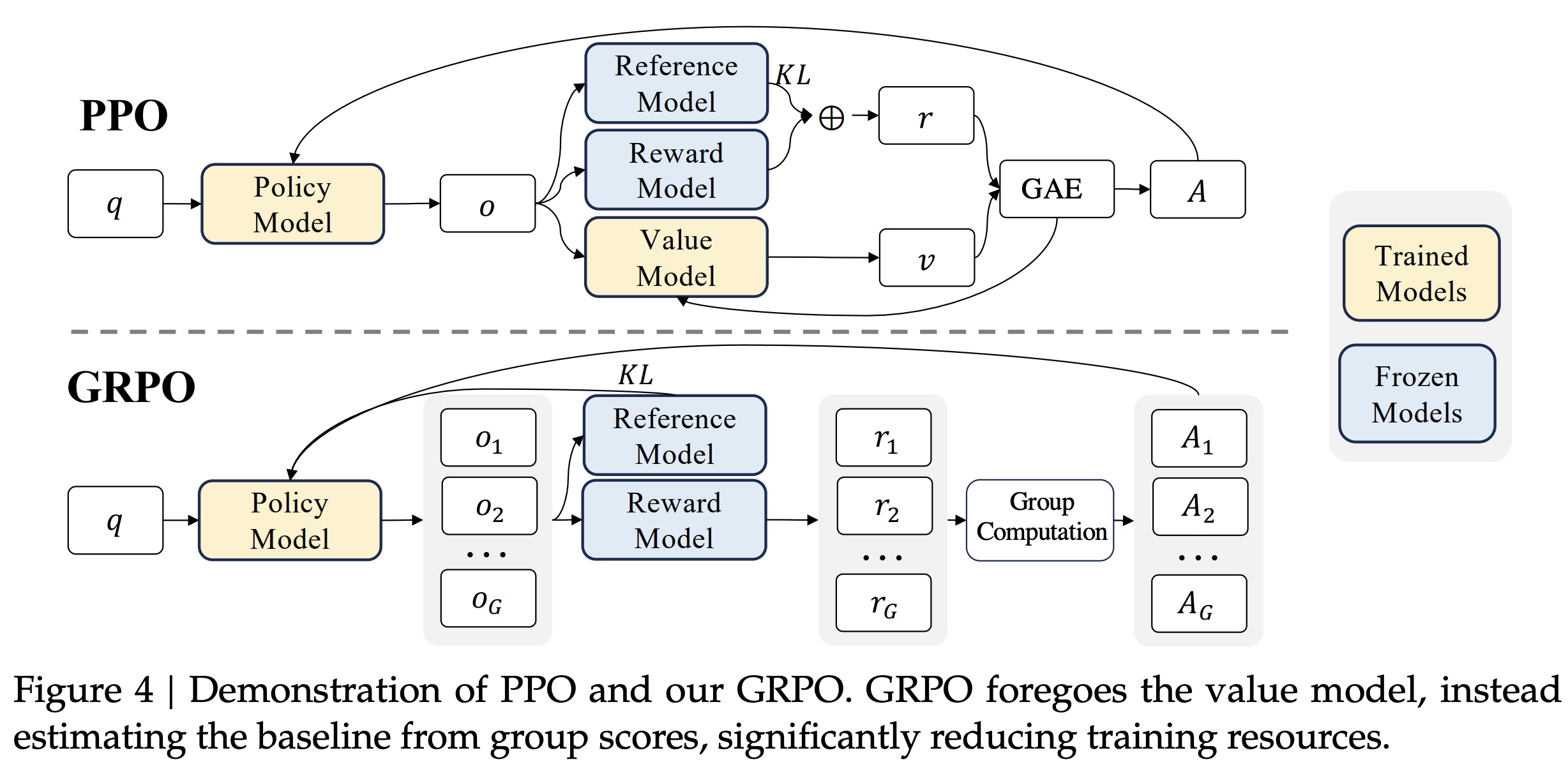
We can see GRPO has no Value Model (i.e., Critic Model), replaced by generating \(G\) outputs each time, computing reward for each:

After getting \(G\) rewards, compute each reward’s advantage function \(A_i\) through Group Computation. Method is based on group mean and variance:

Then policy model loss function:
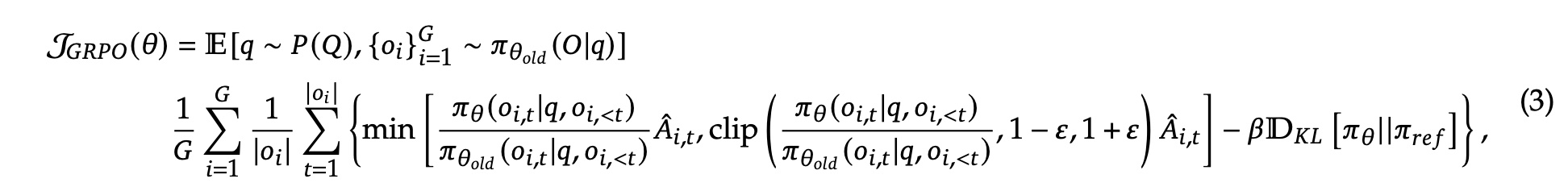
Overall GRPO training algorithm:

Reward Modeling
Although removing Critic Model while keeping Reward Model, DeepSeek-R1’s Reward Model isn’t model-based estimation like PPO above, but rule-based reward modeling. Paper uses two rule-based rewards: accuracy reward and format reward. Rule-based approach is used because model-estimated reward modeling in large-scale RL training easily causes reward hacking (actually all reward-from-estimation approaches have this problem), while making training more complex.

DeepSeek-R1: User-Friendly Model with Cold Start
Although GRPO training significantly improved reasoning capability, DeepSeek-R1-Zero still has defects in practical use. On one hand, R1-Zero’s generated reasoning content has poor readability, language mixing occurs, making reasoning hard to understand. On other hand, directly doing RL on base model without early guidance causes unstable early training and slow convergence.
DeepSeek-R1-Zero encounters challenges such as poor readability, and languagemixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates a small amount of cold-start data and a multi-stage training pipeline.
To address these, DeepSeek-R1 makes 4 improvements:
(1)Specifically, we begin by collecting thousands of cold-start data to fine-tune the DeepSeek-V3-Base model
(2)Following this, we perform reasoning-oriented RL like DeepSeek-R1-Zero
(3)Upon nearing convergence in the RL process, we create new SFT data through rejection sampling on the RL checkpoint, combined with supervised data from DeepSeek-V3 in domains such as writing, factual QA, and self-cognition, and then retrain the DeepSeek-V3-Base model
(4)After fine-tuning with the new data, the checkpoint undergoes an additional RL process, taking into account prompts from all scenarios.
(1) Cold Start
DeepSeek-R1 collects thousands of long CoT data to fine-tune DeepSeek-V3-Base, then does RL training above. This data obtained through various methods like few-shot prompting, guiding model to generate answers with reflection and verification. Cold start data improves output readability, incorporates human prior knowledge, provides better training starting point. After fine-tuning, doing DeepSeek-R1-Zero-style training gives better overall results than pure RL.
(2) Language Consistency Reward
For DeepSeek-R1-Zero’s language mixing in reasoning, DeepSeek-R1 adds language consistency reward during RL training. This reward is computed based on target language word ratio in CoT - higher ratio gets higher reward. Although slightly decreasing model performance, effectively alleviates language mixing, making reasoning more readable.
(3) Rejection Sampling and SFT
First two steps focus on reasoning. This step collects various data to improve model’s general capabilities like writing, role-playing.
Contains two data types: Reasoning data and Non-Reasoning data. Rejection sampling means generating multiple candidate outputs, filtering best samples by specific criteria to improve data quality. E.g., generate 10 possible reasoning paths, only keep most logical or closest to correct answer.
For reasoning data, part comes from previously trained model’s reasoning trajectories, then rule-based rejection sampling (e.g., whether answer matches preset format, whether final result correct). Another part introduces generative reward model, judging whether model reasoning logic matches human-annotated ground truth by inputting model prediction and ground truth into DeepSeek-V3, evaluating logical consistency and semantic matching. Total ~600k data filtered.
For non-reasoning data like writing, factual QA, reuse part of DeepSeek-V3’s SFT dataset, ~200k samples.
Using ~800k total samples, fine-tune base model DeepSeek-V3-Base for two epochs, improving both basic reasoning and general task capabilities.
(4) All-Scenario RL
This step mainly aligns model with human preferences (like harmlessness, helpfulness). Based on step (3) model, additional RL training. For harmlessness, need to identify and remove potentially harmful content by examining reasoning process and final result. For helpfulness, focus on final result’s effectiveness.
Distillation
The report also confirms a “common sense” about distillation: distilling DeepSeek model reasoning capability to other models gives better results than original model and publicly available distilled models:
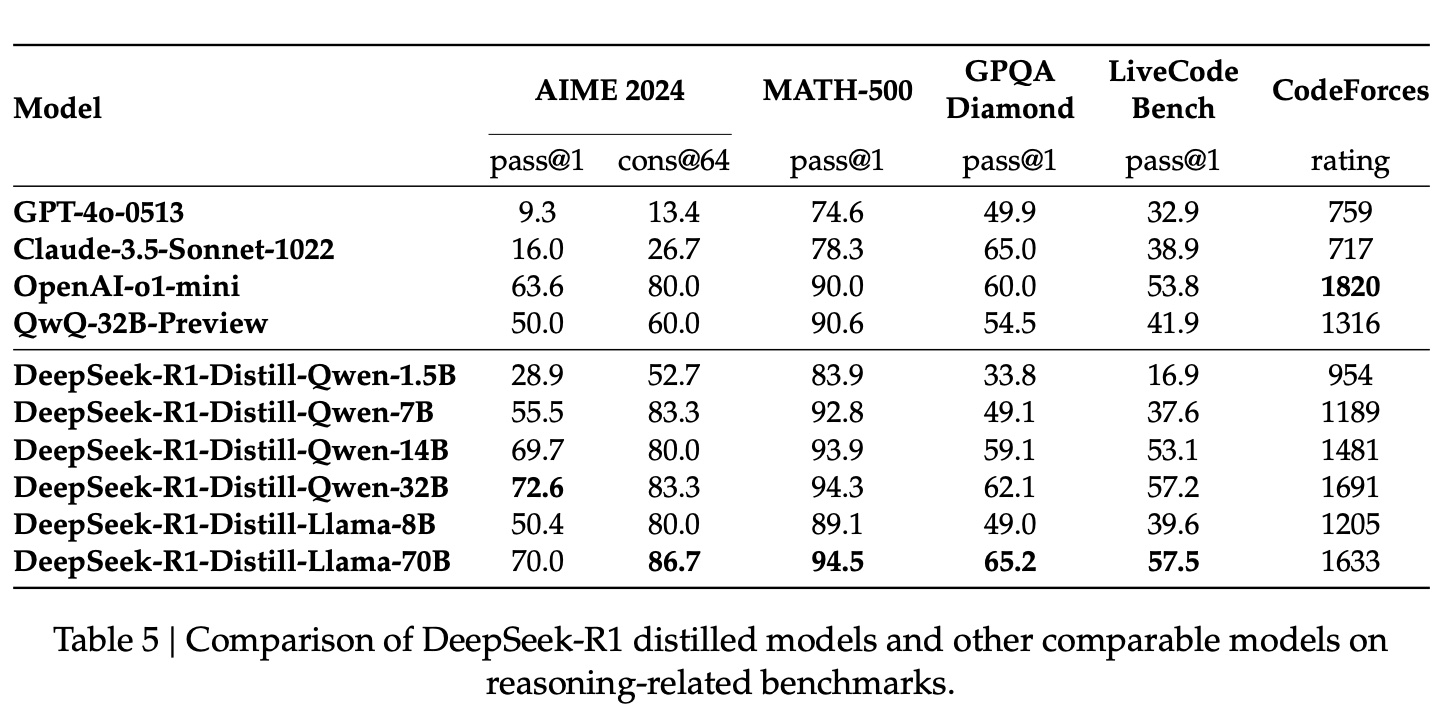
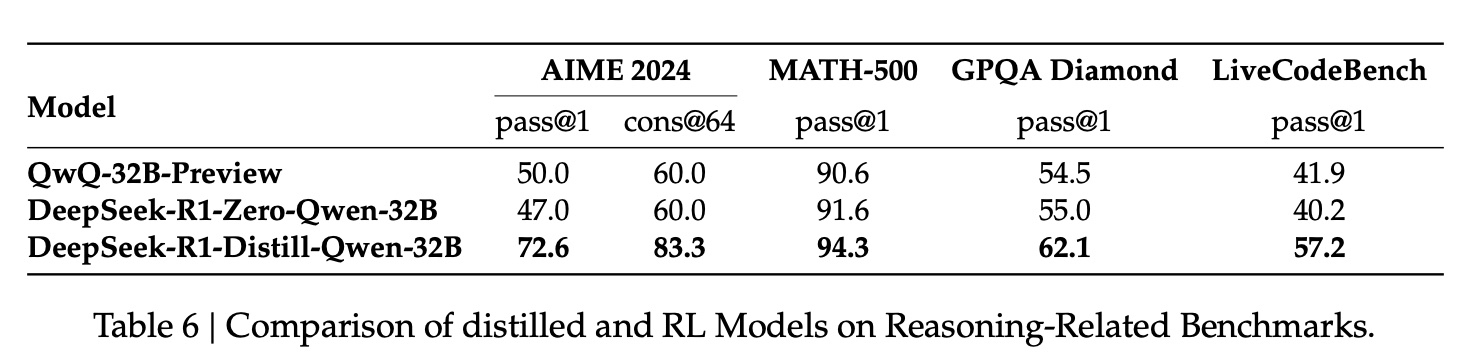
Additionally, with same model parameters, distilled model performs better than using DeepSeek-R1-Zero training process directly, while using less compute:
distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation
Unsuccessful Attempts
This part mainly mentions two unsuccessful attempts: Process Reward Model (PRM) and Monte Carlo Tree Search (MCTS).
Process Reward Model (PRM): Mainly means process reward model hard to implement in practice. Paper mentions several reasons: First, defining steps is difficult (breaking reasoning into steps). Second, defining reward for each step is difficult (model scoring not considered, human annotation impractical). Third, if PRM gets each step’s reward from estimation, reward hacking is inevitable for same reason above: all reward-from-estimation approaches have this problem.
Monte Carlo Tree Search (MCTS): Key method in AlphaGo, not proven effective for LLM training. Main reason is excessive search space and difficulty training value model. Paper does:
MCTS involves breaking answers into smaller parts to allow the model to explore the solution space systematically. To facilitate this, we prompt the model to generate multiple tags that correspond to specific reasoning steps necessary for the search. For training, we first use collected prompts to find answers via MCTS guided by a pre-trained value model. Subsequently, we use the resulting question-answer pairs to train both the actor model and the value model, iteratively refining the process.
MCTS requires multiple simulations and evaluations for each generation step’s possible paths. In games, possible path count is limited, but in natural language generation, each token choice involves thousands of possibilities, causing exponential search space growth. E.g., a 100-token sentence with 100 candidate words per token has \(100^{100}\) total paths, far beyond feasible computation. Pruning can be done, but paper mentions this easily causes poor learning (getting stuck in local optima).
Also MCTS needs training value model to evaluate intermediate steps, difficult to train mainly because reward signal hard to define (same reasons as PRM). So general experience is MCTS suits closed, clear-objective tasks (like problem solving, code generation), but has limited effect in open-domain generation (like creative writing, multi-turn dialogue).
Kimi
Kimi’s report KIMI K1.5:SCALING REINFORCEMENT LEARNING WITH LLMS has similar methods to DeepSeek-R1, 可以说是殊途同归了.
Both reports show RL driving models to autonomously generate CoT, with emergent behaviors like self-verification, reflection. Both significantly improve reasoning capability, especially in math, programming tasks.
Both use distillation to transfer large model capability to smaller models. Kimi proposes Long2Short optimization (like model merging, DPO training), DeepSeek-R1 directly uses large model generated data to fine-tune small models.
But Kimi’s training flow differs from DeepSeek-R1. Kimi still uses multi-stage training (pretraining → SFT → long-chain SFT → RL), unlike DeepSeek’s pure RL exploration. Kimi’s report also mentions many training details not in DeepSeek and OpenAI, providing useful info for other teams to reproduce.
The report mentions achieving good results through “Long context scaling” + “Improved policy optimization” without complex techniques like unsuccessful MCTS and PRM exploration.
Long context scaling
“Long” means extending RL context window to 128k tokens, supporting longer CoT generation, improving complex reasoning capability.
Report mentions RL prompt set - carefully selected problems (math, programming, logic reasoning, etc.) guiding model to generate long-chain reasoning during RL, also important training data source. This data needs constraints:
- Diversity coverage: Covering STEM, programming, general reasoning, ensuring model adapts to different tasks
- Evaluability: Answers verifiable through rules (like math formula verification) or test cases (like programming), excluding easily guessed problems (like multiple choice)
- Balanced difficulty: Including simple, medium, hard problems for progressive learning
Construction methods:
Auto filtering: Determine difficulty through model self-evaluation (e.g., SFT model generating multiple answers, computing pass rate). Filter easily reward-hacked problems, like excluding simple format or random-guess solvable.
Tag system: Classify problems with domain tags (math, programming) and difficulty tags (easy/medium/hard), ensuring balanced training data distribution.
Validation and exclusion: If model can guess answer within multiple attempts (e.g., 8 tries), exclude. Avoid subjective judgment problems (like proofs), maintaining evaluation objectivity.
Long-chain SFT training data is generated from RL prompt set problems through human or automatic high-quality CoT annotation (e.g., through rejection sampling or human refinement), similar to DeepSeek-R1 cold start data.
Improved policy optimization
Policy Optimization
Report proposes variant based on Online Policy Mirror Descent, similar to GRPO, also removing Critic model. Where \(r\) is reward model, \(\pi\) is actor model (also called policy model) and reference model:

Formula (3) above shows final function similar to GRPO, using current \(k\) sampled responses’ mean reward as loss weight, with KL divergence constraint between Actor and Reference outputs.
Length Penalty
Kimi 1.5 introduces length penalty, not mentioned in OpenAI or DeepSeek. Simply, as answer length increases, marginal ROI gradually decreases (model effectiveness / training cost). So training introduces length reward to constrain answer length, computing max and min length among \(k\) sampled responses, then giving extra reward to shorter answers:
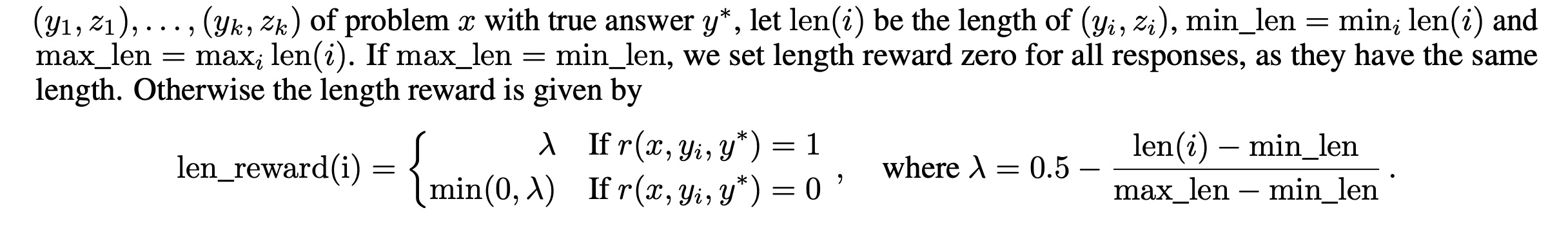
Sampling Strategies
Besides RL’s own sampling, paper proposes two additional strategies: Curriculum Sampling and Prioritized Sampling.
Curriculum Sampling means training simple tasks first, then hard tasks (based on RL prompt set difficulty). Reason is RL model performs poorly initially, so allocating equal training resources to hard tasks gives poor results and low efficiency.
Prioritized Sampling increases sampling probability for hard tasks. If a problem’s success rate is \(s_i\), sampling probability is \(1 − s_i\).
Long2short
This part is similar to distillation, transferring large model capability to smaller models. “Long” and “short” refer to long-CoT models and short-CoT models.
Report uses 4 methods: model merging, shortest rejection sampling, DPO, and long2short RL.
- Model merging: Average two models’ parameters
- Shortest rejection sampling: Sample n times (n=8) for same problem, select shortest answer for SFT
- DPO: Sample n times, select shortest correct answer as positive, long answers (1.5x shortest) as negative (regardless of correctness)
- Long2short RL: Based on trained model, additional RL training with length penalty above
Summary
When RL gradients surge through Transformer architecture, a silent revolution in reasoning capability is reshaping large model evolution trajectory. From OpenAI-o1’s “System 2” slow thinking paradigm in chain of thought, to DeepSeek-R1’s breathtaking leap breaking SFT dependency with pure RL; from PRM’s atomic supervision on reasoning steps, to GRPO algorithm showing group relative advantage after eliminating value function - these breakthroughs not only deconstruct hundred-billion parameter mystique from “brute force aesthetics” era, but compose new possibilities in compute-algorithm duet. When DeepSeek uses rule-based reward models to solve RL reward hacking dilemma, when model distillation compresses reasoning capability into lighter architectures, this technological evolution proves: large models’ core competitiveness might not be how much stellar data they consume, but how to build ladders to production intelligence with more elegant algorithms on GPU remains.
The passage above was also generated by DeepSeek based on this article’s content. After reading, I can’t help marveling at large model capabilities. Whether refusing or accepting, this LLM revolution is reshaping civilization’s texture with gentler roar than steam engine; when 18th century textile workers fearfully watched Jenny spinning machine, they didn’t imagine mechanical arms would support entire industrial civilization; now facing reasoning capability emerging in language models, we’re more fortunate than ancestors - everyone can gather fire in open source community’s compute fragments, every county developer can weave intelligent neural networks with API interfaces. Rather than worrying whether expanding model parameters will devour jobs, better to become first generation of LLM “algorithmic textile workers”; history never sympathizes with passive ones, when LLM chain of thought can penetrate mathematical proof’s copper walls, when DeepSeek-R1’s reasoning capability is being distilled into elderly phone chips through model distillation - this silent cognitive revolution will forever leave hesitaters in steampunk metaphor.