Uplift Modeling and Strategy Optimization in Practice
Many business problems appear to be prediction tasks on the surface, but what they really need is intervention decision-making. For example, when sending coupons, buying ads, or adjusting traffic allocation, the real question is usually not “who is most likely to convert?” but rather who should we intervene on to generate the largest net incremental lift?
This distinction between the two types of problems leads to fundamentally different modeling approaches.
Traditional predictive models are good at answering questions like “will this user buy?” or “will this user retain?” But they struggle to answer questions like “if I send this coupon, will the user buy more because of it?” or “if I reduce live-stream exposure, will the user’s long-term value improve?” The former is a correlation problem; the latter is a causality problem.
The value of Uplift Modeling lies in shifting the optimization target from outcome prediction to estimating the incremental effect of an intervention. Compared with “finding high-probability users,” it focuses more on “finding high-incrementality users,” so that under resource constraints we can maximize the true objective value of a strategy.
This article attempts to introduce the basic principles of uplift and a real-world application scenario. The main contents are as follows:
- Why traditional predictive models are not suitable for directly guiding intervention strategies
- The causal inference foundations behind Uplift Modeling and common modeling methods
- How to understand offline evaluation metrics such as AUUC and Qini
- In general business strategy optimization scenarios, how to go from experiment design all the way to online deployment
- Modeling ideas for extended scenarios such as multiple treatments and continuous treatments
Problem Definition
Correlation ≠ Causation
“Correlation does not imply causation” is almost a cliché in data analysis, but in concrete business settings it is often the easiest thing to overlook. Consider a few classic examples.
- Ice cream sales and drowning accidents
In the data, ice cream sales and drowning accidents are often highly positively correlated. But clearly, banning ice cream would not reduce drownings. The real common cause is temperature: when the weather is hot, people are both more willing to eat ice cream and more willing to go swimming.
- Years of education and income level
People with more years of education usually earn more, but this does not automatically mean that “studying for a few more years” will increase everyone’s income in the same proportion. Factors such as ability and family background may affect both educational choice and income.
- Users who receive coupons spend more
This kind of conclusion is extremely common in marketing scenarios. But the problem is that coupons may have already been targeted at high-value users. In that case, the relationship between “receiving a coupon” and “high spending” may not be caused by the coupon at all; it may simply reflect the correlation induced by the targeting strategy.
Behind these examples lies the same core issue: what the business really needs is what changed because of the intervention, not merely that “the intervention and the outcome happened together.”
Limitations of Traditional Prediction
Traditional machine learning models usually take the outcome \(Y\) as the prediction target:
\[ \hat{Y} = f(X) \]
What they do well is: given user features \(X\), predict whether the user will ultimately take some action. This works for many tasks, but once the question becomes “should we intervene on this user,” three limitations show up.
(1) High-probability users are not the same as high-incrementality users
Suppose we want to optimize purchases after coupon distribution. Traditional models usually identify the people with the highest purchase probability, but these people may not actually be worth targeting.
| User type | Without coupon | After coupon | Worth intervening on? |
|---|---|---|---|
| Sure buyers | Will buy | Will buy | No |
| Persuadables | Won’t buy | Will buy | Yes |
| Lost causes | Won’t buy | Won’t buy | No |
| Sleeping dogs | Will buy | Won’t buy | Should avoid |
Traditional models can only identify “who is more likely to buy,” but they cannot distinguish whether those people are sure buyers, persuadables, or sleeping dogs. Yet in practice, the people worth allocating resources to are usually only the second group: those whose behavior changes positively because of the intervention.
(2) They cannot identify the direction of causality
In advertising, if we observe that “users who saw the ad converted more,” this does not prove that the ad improved conversion. It may simply be that users who were already easier to convert were also easier to target with ads, or more likely to be allocated ad exposure by the system.
(3) They cannot see the counterfactual
When making decisions, what we really care about is:
- What happens after intervention
- What happens without intervention
- How large the difference is
But traditional predictive models usually only observe the one world that actually happened, and cannot see “what would have happened if we had not done it.”
And that counterfactual is exactly the key object in causal estimation.
What Uplift Is Estimating
Uplift Modeling does not focus on the outcome itself, but on the net change caused by an intervention.
For a single user \(i\), what we want to estimate is:
\[ \tau_i = Y_i(1) - Y_i(0) \]
where:
- \(Y_i(1)\) is the outcome if the user receives the treatment
- \(Y_i(0)\) is the outcome if the user does not receive the treatment
- \(\tau_i\) is the incremental effect of the treatment on that user
This makes the difference between traditional prediction and Uplift Modeling very clear:
| Dimension | Traditional predictive model | Uplift Modeling |
|---|---|---|
| Core question | Will the user convert? | Can intervention make the user convert more? |
| Learning target | Outcome probability | Causal incrementality |
| Identification target | High-probability users | High-incrementality users |
| Strategic consequence | May waste resources | Better suited for fine-grained targeting |
Theoretical Foundations
Potential Outcomes
From a theoretical perspective, the most common foundation for Uplift Modeling is the Potential Outcomes Framework in causal inference.
For any user \(i\), there are theoretically two potential outcomes:
- \(Y_i(1)\): the outcome after receiving the treatment
- \(Y_i(0)\): the outcome without receiving the treatment
The Individual Treatment Effect (ITE) is defined as:
\[ \tau_i = Y_i(1) - Y_i(0) \]
But this immediately runs into a classic difficulty: for the same user, we can never simultaneously observe the states “treated” and “untreated.” This is the Fundamental Problem of Causal Inference.
Therefore, in practice we usually do not directly estimate the true ITE for an individual user. Instead, we estimate the Conditional Average Treatment Effect (CATE):
\[ \tau(x) = E[Y(1) - Y(0) \mid X = x] \]
That is: among people with similar features, how much change does the intervention create on average? This is what most uplift models actually try to learn.
Four Types of Users
From a business perspective, one of the biggest values of uplift is that it lets us move from “segmenting users by outcomes” to “segmenting users by treatment response.” A common four-quadrant breakdown is as follows:
| User type | Behavior after treatment | Behavior without treatment | Treatment effect | Strategy recommendation |
|---|---|---|---|---|
| Persuadables | Positive | Negative | Positive | Worth treating |
| Sure Things | Positive | Positive | Close to 0 | No need to treat |
| Lost Causes | Negative | Negative | Close to 0 | No need to treat |
| Sleeping Dogs | Negative | Positive | Negative | Avoid treatment |
The most important group here is Persuadables; the one to avoid most carefully is Sleeping Dogs.
Many business strategies look like “users with higher model scores get more aggressive exposure,” but if high-score users are mostly Sure Things, resources are wasted. And if we accidentally harm a large number of Sleeping Dogs, the strategy may even create negative returns.
Three Assumptions
To make uplift estimation credible, we usually rely on at least the following three assumptions.
1. Unconfoundedness
\[ (Y(1), Y(0)) \perp T \mid X \]
That is, conditional on features \(X\), treatment assignment \(T\) is independent of the potential outcomes.
In plain language: if the treatment is targeted by an online strategy, and that strategy is itself strongly correlated with conversion tendency, then confounding is easily introduced. In that case, we can no longer tell whether “the treatment worked” or whether “the treated people were already more likely to convert.”
So in uplift settings, we usually rely on RCTs to make treatment assignment as random as possible, thereby reducing confounding and improving identifiability.
2. Overlap
\[ 0 < P(T=1 \mid X=x) < 1 \]
This means that for any type of user, there should be some chance of entering either the treatment group or the control group. Every subgroup must contain both treatment and control samples, otherwise the model cannot learn the before-vs-after treatment difference for similar users, i.e., the CATE.
3. Stable Unit Treatment Value Assumption
A user’s potential outcome should be affected only by that user’s own treatment status, and not by the treatment statuses of other users.
In simple terms, the treatment effect of a user should depend only on that user’s own treatment.
But if other people’s treatments can also affect that user, the problem becomes more complicated. The outcome no longer depends only on “was I treated,” but also on factors like whether my friends were treated, whether other merchants received subsidies, or whether other users in the same traffic pool were treated.
In real business settings, this assumption may be violated when there are strong social spillovers, resource competition, or system-level interactions between users.
For example, suppose we study whether a person getting vaccinated reduces that person’s infection risk. If only “did this person get vaccinated” matters, the comparison is simple. But in reality, whether other people are vaccinated also affects you: if many people around you are vaccinated, virus transmission weakens overall, so even if you are not vaccinated, your infection risk drops. That is a case where SUTVA does not hold.
In practice, SUTVA often does not hold perfectly in real businesses either. Many businesses naturally involve interactions: social contagion, resource competition, inventory constraints, and so on. For example, in LT optimization, suppressing one content genre may increase the user’s consumption of other genres, so the user’s final LT change is jointly affected by both genre shifts.
So SUTVA is often not a binary “fully true” or “fully false” assumption. Rather, the question is: how strong is the interference, and can it be ignored?
If the interference is weak, engineering practice may accept it as an approximation. If the interference is strong, the experiment may need to be redesigned, for example: - randomize by group rather than by individual, e.g. send coupons to the same friend circle together instead of splitting them - switch from “user-level randomization” to “time-level randomization,” i.e. do not let some users be treated and others untreated at the same time; instead, turn treatment fully on in some time windows and fully off in others
Modeling Methods
There is no single standard answer in Uplift Modeling. In engineering practice, two families of methods are more common:
- Meta-Learners: decompose causal effect estimation into several supervised learning subproblems, such as various xx-Learners
- Direct Uplift Models: directly design the model or splitting criterion around the treatment effect; Causal Forest is the most common representative of this family
Below is a brief introduction.
Meta-Learners
1. S-Learner
The idea of the S-Learner is the most direct: treat the intervention variable \(T\) as a standard feature, and feed it into the model together with the other user features.
\[ \mu(x, t) = E[Y \mid X=x, T=t] \]
At serving time, for the same user we input \(t=1\) and \(t=0\) separately, and the difference between the two predictions is the uplift estimate:
\[ \hat{\tau}(x) = \hat{\mu}(x, 1) - \hat{\mu}(x, 0) \]
Pros:
- Simple to implement
- All samples are used to train one model
- A good baseline for quick validation
Cons:
- If the treatment signal is weak, the model may ignore \(T\)
- Regularization bias can appear under strong regularization
If you just want to quickly test whether uplift has potential in the business, the S-Learner is often a very practical starting point. But if you truly care about higher-quality CATE estimation, it is usually not the final answer.
2. T-Learner
The T-Learner fully separates the treatment group and the control group, training two models independently:
\[ \mu_1(x) = E[Y \mid X=x, T=1] \]
\[ \mu_0(x) = E[Y \mid X=x, T=0] \]
Their difference is the uplift:
\[ \hat{\tau}(x) = \hat{\mu}_1(x) - \hat{\mu}_0(x) \]
Pros:
- Can fit different patterns for treatment and control separately
- Less likely than S-Learner to wash out the treatment signal
Cons:
- Each model only uses part of the samples, so sample efficiency is lower
- Performance degrades easily under sample imbalance
- Errors from the two models accumulate
3. X-Learner
The X-Learner can be understood as improving sample efficiency on top of the T-Learner, especially in scenarios where treatment and control samples are imbalanced.
Its core steps can be summarized in three stages:
3.1 Train two response models
\[ \hat{\mu}_1(x) = E[Y \mid X=x, T=1] \]
\[ \hat{\mu}_0(x) = E[Y \mid X=x, T=0] \]
3.2 Construct pseudo causal effects
For treatment-group samples:
\[ D_i^1 = Y_i^1 - \hat{\mu}_0(X_i) \]
For control-group samples:
\[ D_i^0 = \hat{\mu}_1(X_i) - Y_i^0 \]
Then train two separate effect models:
\[ \hat{\tau}_1(x) = E[D^1 \mid X=x] \]
\[ \hat{\tau}_0(x) = E[D^0 \mid X=x] \]
3.3 Combine them using propensity-score weighting
\[ \hat{\tau}(x) = g(x) \cdot \hat{\tau}_0(x) + (1-g(x)) \cdot \hat{\tau}_1(x) \]
where \(g(x)\) is usually taken as the propensity score \(P(T=1 \mid X=x)\).
Pros:
- More robust to sample imbalance
- Often achieves better CATE accuracy than S-Learner and T-Learner
- Better suited to asymmetric experiment designs in business settings
Cons:
- More complex to implement and tune
- Longer training pipeline and harder diagnosis
Direct Uplift Models
Direct Uplift Models refer to models that directly design the split criterion or loss function around the treatment effect. Common methods include:
- Uplift Tree: a tree adapted for uplift settings, using criteria such as KL / Euclidean / Chi-square distance to split, with the goal of maximizing the distribution difference between treatment and control groups
- Causal Forest: an ensemble version of Causal Trees, with more statistically principled split criteria (e.g. CMSE, SFT), often combined with honest estimation
Their essential difference from ordinary decision trees is:
- Ordinary trees: the split objective is about prediction error or class purity
- Trees in uplift: the split objective is about heterogeneity in the treatment effect
Let us go through them separately.
1. What an ordinary decision tree does when splitting
The splitting logic of an ordinary decision tree (classification or regression) is essentially trying to make each node more “pure.” Common criteria include:
Gini impurity
\[ G = \sum_{k=1}^{K} p_k (1 - p_k) \]
where \(p_k\) is the fraction of samples in the node that belong to class \(k\). Smaller Gini means the node is more homogeneous.
Information gain (based on entropy)
\[ H = -\sum_{k=1}^{K} p_k \log p_k \]
The greater the entropy reduction after a split, the more the split separates the classes.
Mean squared error (MSE) for regression trees
\[ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \bar{y})^2 \]
The splitting objective is to make the variance within the left and right child nodes as small as possible, so the predictions are more concentrated.
These criteria all reveal one thing: ordinary decision trees only care about putting people with similar outcomes together. They do not care about the treatment, and they do not care about the difference between “treated” and “untreated.” So using an ordinary tree to predict “will the user buy after receiving a coupon” is really learning “who is more likely to buy,” not “who becomes more likely to buy because of the coupon.”
2. What an Uplift Tree does when splitting
An Uplift Tree no longer splits around “outcome purity,” but around the difference between the treatment group and the control group.
Its intuition is: if a split makes the treatment effect on the left and right branches clearly different, then that feature is likely capturing who is more sensitive to the intervention.
Common split criteria include:
KL divergence
\[ D_{KL}(P^T || P^C) = \sum_y P^T(y) \log \frac{P^T(y)}{P^C(y)} \]
Euclidean distance
\[ D_E = \sum_y (P^T(y) - P^C(y))^2 \]
Chi-square distance
\[ D_{\chi^2} = \sum_y \frac{(P^T(y) - P^C(y))^2}{P^C(y)} \]
These three formulas look different, but their core logic is the same:
- \(P^T(y)\) is the outcome distribution for the treatment group
- \(P^C(y)\) is the outcome distribution for the control group
- The split objective is to make these two distributions as different as possible
Why can a distribution difference reflect uplift?
There is an important mathematical link behind this. For binary-outcome problems (e.g. whether the user purchases), uplift is defined as:
\[ \hat{\tau} = P^T(Y=1) - P^C(Y=1) \]
That is, uplift is essentially the difference between the two distributions at the point \(Y=1\).
So what is the relationship between KL / Euclidean / Chi-square distance and uplift? Take Euclidean distance as an example:
\[ D_E = \sum_y (P^T(y) - P^C(y))^2 = (P^T(1) - P^C(1))^2 + (P^T(0) - P^C(0))^2 \]
Because \(P(1) + P(0) = 1\), we have \(P^T(1) - P^C(1) = -(P^T(0) - P^C(0))\), so:
\[ D_E = 2 \times (P^T(1) - P^C(1))^2 = 2 \times \hat{\tau}^2 \]
Maximizing Euclidean distance is equivalent to maximizing the square of uplift.
KL divergence and Chi-square distance can be understood as “weighted amplifications” of uplift. They not only consider the size of the difference, but also the relative position of the distributions. When \(P^C\) is close to 0 or 1, the same uplift receives a larger weight.
So the shared logic of these three distances is: when \(P^T\) and \(P^C\) differ greatly, the treatment has a stronger impact on the outcome, meaning the absolute uplift is larger.
The split criterion of an Uplift Tree is therefore: find a split that makes the \(P^T\)-\(P^C\) distribution difference on the two sides as different as possible. If the left branch has a large \(P^T\)-\(P^C\) difference (high uplift) while the right branch has a small one (low uplift), then the split has successfully separated “high-uplift users” from “low-uplift users.”
A more intuitive way to say it is that an Uplift Tree asks, at each split: can this split separate people with a large before-vs-after treatment difference from people with a small one?
Let us illustrate with an example. Suppose we have two candidate features for splitting, and want to judge which one is better.
After splitting on candidate feature A:
| Group | Purchase rate with coupon | Purchase rate without coupon | Uplift |
|---|---|---|---|
| Left | 30% | 10% | +20% |
| Right | 25% | 20% | +5% |
After splitting on candidate feature B:
| Group | Purchase rate with coupon | Purchase rate without coupon | Uplift |
|---|---|---|---|
| Left | 28% | 18% | +10% |
| Right | 27% | 17% | +10% |
Feature A creates a 15% uplift gap between left and right (20% - 5%), while feature B produces almost the same uplift on both sides (both 10%).
From the Uplift Tree’s perspective:
- Feature A successfully separates users into two groups: “coupon-sensitive” (left, uplift = 20%) and “less coupon-sensitive” (right, uplift = 5%), so it captures heterogeneity
- Feature B may also improve purchase rates, but the uplift is almost the same on both sides, meaning it does not distinguish who is more sensitive
So the Uplift Tree will prefer feature A, because it “cuts out” heterogeneity in the treatment effect.
But if we used an ordinary decision tree instead, it would only look at the purchase rate itself:
- Purchase rate on A-left: (30% + 10%) / 2 = 20%
- Purchase rate on A-right: (25% + 20%) / 2 = 22.5%
- Purchase rate on B-left: (28% + 18%) / 2 = 23%
- Purchase rate on B-right: (27% + 17%) / 2 = 22%
An ordinary tree might think feature B is better (because the purchase rates are more similar and the nodes look “purer”), but that is exactly because it ignores the uplift difference we actually care about.
The one-sentence summary is:
- Ordinary tree: make the outcome in each node purer (who is more likely to buy)
- Uplift Tree: make the treatment effect in each node more extreme (who is more likely to be changed)
3. What a Causal Forest does when splitting
A Causal Forest can be understood as an ensemble version of a Causal Tree, and it is one of the more commonly used methods in real businesses. Its core idea is not simply to “assign a score to each user,” but rather: for a target user \(x\), automatically find a neighborhood of samples that are more similar to that user in treatment effect, and then estimate the local CATE within that neighborhood.
Theoretical background: CMSE and SFT
Before introducing the concrete criteria, let us first understand two theoretical concepts.
CMSE (Causal Mean Squared Error)
In theory, we want to minimize the error of the causal effect estimate:
\[ \text{CMSE} = E\left[(\tau(X) - \hat{\tau}(X))^2\right] \]
where \(\tau(X)\) is the true CATE and \(\hat{\tau}(X)\) is the model estimate.
But the problem is: the true \(\tau\) is unobservable, so CMSE cannot be computed directly. This theoretical objective tells us what we should optimize, but practical algorithms must approximate it with computable quantities.
SFT (Signal-to-Noise Ratio / stability consideration)
Another perspective is that we should not only look at how large the effect difference is, but also how stable it is. If the effect difference is large but the estimation variance is also large, the difference may just be noise.
For CMSE, there is a key question: how can a split criterion implement the optimization target of CMSE? Or, since CMSE cannot be computed directly, how can a criterion that maximizes estimated effect differences indirectly minimize CMSE?
The core logic is: maximizing between-leaf differences is approximately equivalent to minimizing within-leaf error.
CMSE optimizes for “small estimation error,” which is equivalent to making the estimate \(\hat{\tau}\) close to the true value \(\tau\) in each leaf. To achieve that, we want the true \(\tau\) values within each leaf to be as consistent as possible (small variance). If the true \(\tau\) values of the people in a leaf are all similar, then using a single \(\hat{\tau}\) to represent them naturally incurs small error.
The split criterion maximizes the difference between the left and right branches. Thinking in reverse: if the two sides differ a lot, that suggests the people on the left have true \(\tau\) values close to one level, while the people on the right have true \(\tau\) values close to another. In other words, each leaf becomes more homogeneous internally.
Mathematically, one can show that:
\[ \text{Total variance} = \text{Between-leaf variance} + \text{Within-leaf variance} \]
Maximizing the “between-leaf difference” means maximizing between-leaf variance. Since total variance is fixed, larger between-leaf variance implies smaller within-leaf variance. Smaller within-leaf variance means more consistent \(\tau\) within each leaf, and therefore smaller estimation error.
But there is an important premise: the split uses \(\hat{\tau}\) (the estimate), not the true \(\tau\). If \(\hat{\tau}\) is inaccurate, it may separate people who were actually homogeneous, or group together people who were actually heterogeneous. This is why we need: - enough samples, so each leaf has enough treatment and control data - Honest Estimation, so we do not use the same data to choose the split and estimate the effect, which would otherwise cause overfitting
So the full, somewhat unintuitive logic chain is:1
2
3
4
5
6
7
8
9Goal: minimize CMSE = E[(τ - τ̂)²]
↓
Equivalent to: make τ within each leaf as consistent as possible
↓
Implementation: maximize between-leaf differences (maximize the difference in τ̂ between left and right)
↓
Mathematical principle: larger between-leaf variance → smaller within-leaf variance
↓
Key trick: Honest Estimation keeps τ̂ approximately unbiased
These two theoretical concepts motivate the following two practical split criteria (choose one of the two).
Criterion 1: maximize effect difference
Choose the split that maximizes the treatment effect difference between the left and right child nodes:
\[ \max_{j,s} \left( \hat{\tau}^{left}(j,s) - \hat{\tau}^{right}(j,s) \right)^2 \]
Within a node, \(\hat{\tau}\) is computed as:
- Average outcome of the treatment group \(\bar{Y}^T\)
- Average outcome of the control group \(\bar{Y}^C\)
- Estimated treatment effect \(\hat{\tau} = \bar{Y}^T - \bar{Y}^C\)
But note that the true treatment effect \(\tau\) (which would require observing both the treated and untreated outcomes for every user) and \((\tau - \hat{\tau})^2\) are both uncomputable. As discussed above, we approximate the CMSE objective using only \(\hat{\tau}\).
So this criterion uses only the estimate \(\hat{\tau}\) and never involves the true \(\tau\).
In plain language, if a split makes the uplift on the two sides clearly different (for example, 15% on the left and -5% on the right), then the split captures heterogeneity and should be selected.
Criterion 2: a t-statistic-style criterion that accounts for variance
On top of the effect difference, also account for the stability of the estimate:
\[ \frac{\left(\hat{\tau}^{left} - \hat{\tau}^{right}\right)^2}{\widehat{Var}(\hat{\tau}^{left}) + \widehat{Var}(\hat{\tau}^{right})} \]
The numerator is the squared effect difference; the denominator is the sum of the estimation variances.
In plain language, this criterion asks: “is the uplift gap between left and right real heterogeneity, or is it just due to too few samples and too much noise?”
If a split gives left uplift = 30% and right uplift = 5%, but the left side has only 10 samples, then this difference may just be noise. This criterion automatically downweights such unstable splits.
How do we choose between the two criteria?
| Criterion | Characteristics | Suitable scenario |
|---|---|---|
| Maximize effect difference | Simple and direct; only looks at effect magnitude | Large sample size, controllable noise |
| t-statistic style | Balances difference and stability | Limited sample size, need more robust estimation |
Key trick: Honest Estimation
No matter which criterion is chosen, Causal Trees are usually used together with Honest Estimation:
| Sample | Purpose |
|---|---|
| Sample A | Decide how to split (discover heterogeneity structure) |
| Sample B | Estimate the treatment effect after splitting |
Why do this? If the same samples are used both to choose the split and to estimate the effect, the model will prefer splits that happen to show large differences in this dataset, rather than splits that truly reflect heterogeneity. This is just like training and evaluating on the same training set: the result is too optimistic.
After separating splitting and estimation, Sample B becomes an independent and “fair” estimator, so the estimated uplift is more credible. More rigorously, this avoids overfitting bias and, under suitable conditions, makes the CATE estimate asymptotically normal.
Uplift Tree and Causal Forest: a unified view
At a higher level, Uplift Trees and Causal Forests are doing the same thing: finding where the difference between treatment and control is the largest. The only difference is the angle from which they measure that difference:
Uplift Tree: distribution-difference perspective
It uses KL / Euclidean / Chi-square distance to measure the “distance” between the distributions \(P^T\) and \(P^C\). A larger distance means the treatment has a stronger impact on the outcome distribution. Its characteristic is that it considers the deviation of the entire distribution, not just the mean.
Causal Forest: point-estimate perspective
It directly computes \(\hat{\tau}^{left} - \hat{\tau}^{right}\), where \(\hat{\tau} = \bar{Y}^T - \bar{Y}^C\). This is the difference in the point estimate of uplift. At the same time, it uses variance adjustment (the t-statistic style) to ensure the stability of that difference.
The mathematical connection between the two is that for binary outcomes, \(P^T(1) - P^C(1) = \hat{\tau}\), so distribution difference and uplift difference are essentially two measures of the same thing.
Which method should you choose? It depends on business needs:
- Need to consider changes in the full outcome distribution → the distance measure in Uplift Trees is more comprehensive
- Need a clean uplift point estimate and confidence interval → Causal Forest is more direct
- Sample size is limited and stability matters → the variance adjustment in Causal Forest is more robust
4. Summary: comparing the split objectives of three types of trees
| Method | Split objective | Plain-language summary |
|---|---|---|
| Ordinary decision tree | Minimize prediction error or class impurity | Put people with similar outcomes together |
| Uplift Tree | Maximize the distribution difference between treatment and control | Put people with large treatment-effect differences together |
| Causal Tree / Forest | Maximize treatment-effect heterogeneity while controlling estimation error | Put people with different treatment effects together, and make sure the difference is trustworthy |
An even more intuitive summary is: ordinary trees learn “who is similar,” Uplift Trees learn “who is more likely to be changed,” and Causal Forests learn “who is more likely to be changed, and I am confident that this judgment is correct.”
In uplift scenarios, Causal Forest is generally used more often than Uplift Tree, although both have their own appropriate use cases.
The strengths of Causal Forest are:
- Stronger engineering stability: a single Uplift Tree is prone to overfitting and instability, while Causal Forest is an ensemble method with better generalization
- More complete theoretical support: honest estimation supports confidence intervals, and asymptotic normality supports statistical inference
- Better at capturing complex heterogeneity: it handles feature interactions and nonlinear relationships better, so it is more suitable for businesses with many features and complex relationships
The strengths of Uplift Tree are:
- Better rule interpretability: a single tree can output clear split rules, which makes it easier for operations teams to understand and execute; suitable for audience-segmentation insights
- Fast prototyping: simple to implement and train, useful for quickly checking whether an uplift signal exists
- Rule-engine deployment: some business systems require explicit if-else rules, which Uplift Trees can directly provide
Common choices in real engineering practice:
| Stage | Common method | Why |
|---|---|---|
| Quickly validate whether uplift exists | S-Learner / Uplift Tree | Simple and fast |
| Pursue higher CATE accuracy | X-Learner / Causal Forest | More robust and theoretically stronger |
| Need interpretable rule output | Uplift Tree | Better interpretability |
| Production deployment | Causal Forest / Meta-Learner | Stability comes first |
In one sentence: Causal Forest is better suited to be the “main model” because it is stable, theoretically well grounded, and widely validated in industry; Uplift Tree is better suited as an “auxiliary tool” for rule insight, audience segmentation, and fast prototyping.
Method Selection
If we compare the methods discussed above together, the picture looks roughly like this:
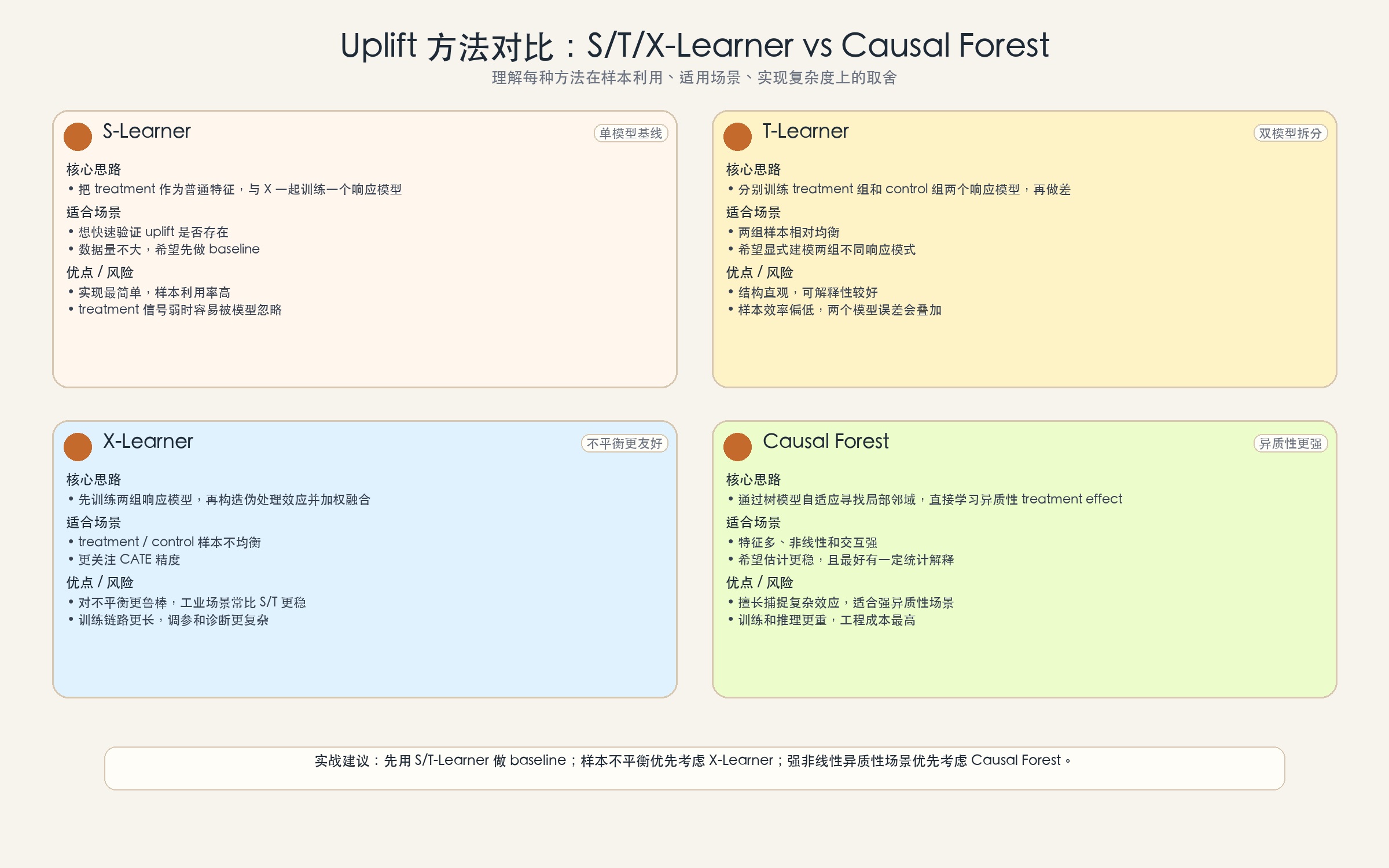
| Method | Suitable scenario | Pros | Cons |
|---|---|---|---|
| S-Learner | Quick validation, small data | Simple to implement, high sample efficiency | Easily fails when the treatment signal is weak |
| T-Learner | Balanced samples, clear effect | Intuitive structure | Low sample efficiency, error accumulation |
| X-Learner | Sample imbalance, higher precision | More robust, usually better performance | More complex pipeline |
| Uplift Tree | Need rule explanations, user segmentation | Good interpretability | Moderate stability |
| Causal Forest | Strong nonlinearity, need more stable estimates | Stronger theory, can capture complex effects | Higher computational cost |
There is no silver bullet in engineering. In many cases, the best approach is not to pursue the most complex model from the start, but rather:
- Use a simple baseline to quickly verify whether uplift really exists
- Then gradually move to a stronger effect learner
- Finally, focus on how the strategy is used, rather than only staring at offline scores
Evaluation Metrics
The evaluation of uplift differs from ordinary classification or regression. The reason is simple: the true individual causal effect is unobservable—we never get to see what the same user would have done in both the treated and untreated worlds.
So the focus of uplift evaluation is usually not “is the point prediction accurate,” but “is the ranking effective”—can the model rank the users who are truly worth treating near the top?
An analogy with classification helps: AUC measures the ability to rank positive samples ahead of negative ones; uplift is similar, and AUUC measures the ability to rank high-uplift users ahead of low-uplift users.
Before going into the formulas, let us first unify the definitions:
- AUUC: the total area between the uplift curve and the x-axis (the zero-increment line), after sorting users by predicted uplift from high to low
- Qini coefficient: the excess area of the uplift curve above the random baseline (whose height equals the ATE)
Both are based on the cumulative curve obtained after sorting users by predicted uplift from high to low; the only difference is the reference baseline.
AUUC
Imagine 1,000 users sorted from highest to lowest by predicted uplift.
- First, intervene only on the top 10% (100 users): among this group, how much higher is the response rate of the treatment group than that of the control group? That difference is the average uplift of this segment.
- Then extend to the top 20%, and recompute the average uplift of these 200 users.
- Continue in this way until 100% coverage (all 1,000 users).
If we plot “coverage ratio → average uplift of that covered population,” we obtain the uplift curve. And AUUC is simply the total area under that curve.
If the ranking is effective, the users at the top will have high uplift and those later in the ranking will have lower uplift. The curve will gradually decline from the upper-left and eventually converge to the ATE (the average treatment effect of the whole population). Once we cover 100%, that group is everybody, so the average uplift naturally equals the ATE.
Formally, for the top \(k\) users, the difference between treatment-group response rate and control-group response rate is the estimated average uplift of that subset:
\[ \hat{\tau}_k = \frac{\sum_{i=1}^{k} Y_i^T}{N_k^T} - \frac{\sum_{i=1}^{k} Y_i^C}{N_k^C} \]
where \(Y_i^T\) and \(Y_i^C\) are the response values in the treatment and control groups, and \(N_k^T\) and \(N_k^C\) are the corresponding sample counts.
AUUC is the discrete approximation to the area under this curve:
\[ AUUC = \int_0^1 U(p)\,dp \approx \frac{1}{N} \sum_{k=1}^{N} \hat{\tau}_k \]
A more intuitive explanation is: add up the average uplift at every coverage level and then take the average. This computation has a natural property: users ranked earlier contribute more weight to AUUC, which is exactly what rewards models that place high-uplift users near the top.
More rigorously, if the true effect of the user ranked at position \(j\) is denoted by \(\tau_{(j)}\), AUUC can be expanded as a weighted sum:
\[ AUUC = \sum_{j=1}^{N} w_j\,\tau_{(j)}, \qquad w_j = \frac{1}{N}\sum_{k=j}^{N}\frac{1}{k} \]
where \(w_1 > w_2 > \cdots > w_N\) (earlier users receive larger weights). By the rearrangement inequality, AUUC is maximized when the \(\tau_{(j)}\) are sorted in descending order—that is, a perfect ranking achieves the highest AUUC.
If the ranking is completely random, then the expected composition of any “top \(k\) users” matches the overall population, and the expected average uplift equals the ATE:
\[ \mathbb{E}[AUUC_{rand}] = ATE \]
This means the absolute value of AUUC is itself affected by the ATE: even under random ranking, the expected AUUC equals the ATE. So experiments with stronger intrinsic treatment effects naturally have higher AUUC, which does not imply better ranking quality by the model.

There is also an engineering detail for this metric: when the treatment/control ratio is highly imbalanced (for example 9:1), the estimate near some quantiles may fluctuate strongly due to too few samples. Common handling methods include using equal-frequency bins (so that each segment contains enough treatment/control samples), or smoothing the curve.
Qini Coefficient
The absolute value of AUUC is affected by the ATE—experiments with stronger intrinsic treatment effects naturally have higher AUUC, which can be misleading in cross-experiment comparisons.
The Qini coefficient switches the reference frame and answers a more direct question: compared with a random strategy, how much additional incrementality does the model ranking generate?
Assume that the expected uplift curve under random ranking is \(U_{rand}(p) = ATE\) (a horizontal line). Then Qini is the area by which the model curve exceeds that baseline:
\[ Qini = \int_0^1 \left(U(p) - U_{rand}(p)\right)dp = \int_0^1 \left(U(p) - ATE\right)dp \]
Since \(\int_0^1 ATE\,dp = ATE\), the relationship between the Qini coefficient and AUUC is very simple:
\[ \boxed{Qini = AUUC - ATE} \]
Qini is the area left after subtracting the part that would already be contributed by a random strategy from AUUC. It is the truly extra gain “earned” by the model ranking itself. A more intuitive interpretation is as follows:
| Situation | Curve position | Qini |
|---|---|---|
| Model is better than random | Curve stays above the ATE baseline overall | Positive |
| Model is the same as random | Curve is close to the ATE baseline | ≈ 0 |
| Model is worse than random | Curve stays below the ATE baseline overall | Negative |
Under random ranking, the expected Qini is 0:
\[ \mathbb{E}[Qini_{rand}] = 0 \]

AUUC vs Qini: when should you use which?
| Metric | Reference baseline | Meaning of the area | Best suited to answer |
|---|---|---|---|
| AUUC | x-axis (zero-increment line) | The absolute area under the model’s uplift curve | How much total incremental value can the overall strategy create? |
| Qini | Random baseline (height = ATE) | The excess area over a random strategy | How much better is the model ranking than random? |
Which one should you choose?
- If you care about absolute incremental ability (overall strategy value), use AUUC
- If you care about model quality and cross-experiment comparison (which model ranks better), Qini is more suitable because it has already removed the contribution of the ATE itself
- In practice, people often look at both, and their directional conclusions are usually consistent
Notes for cross-experiment comparison
Neither AUUC nor Qini has a universal unit, so comparisons should be made under the same definition:
- Different sample sizes: absolute values from 100k samples and 1M samples are not directly comparable
- Different label definitions: uplift curves for “7-day payment rate” and “7-day GMV” are on different scales
- Different business definitions: whether refunds are included, whether abnormal orders are filtered, etc., all affect uplift computation
- Different treatment-group ratios: Qini depends on the random baseline, so comparability decreases if treatment/control ratios differ significantly
Another Common Visualization: the Cumulative Gain Curve
Besides the “average uplift curve” above, engineering practice also often uses another equivalent but shape-reversed plot: the Cumulative Gain Curve, which is common in tools such as causalml and EconML.
The only difference is the definition of the y-axis. If we multiply the average uplift \(U(p)\) by the coverage ratio \(p\), we obtain the cumulative net increment generated by the top \(p\) fraction of users:
\[ G(p) = p \cdot U(p) \]
Since \(G(p)\) starts at 0 and increases with coverage, the curve extends from the lower left to the upper right. The random baseline is no longer horizontal, but a diagonal line from the origin to the full-population gain (\(G_{rand}(p) = p \cdot ATE\)); the two curves meet at 100% coverage, where both equal the ATE.

| Average uplift curve | Cumulative gain curve | |
|---|---|---|
| Meaning of y-axis | Average incremental effect among the top k% users \(U(p)\) | Total increment generated by the top k% users \(G(p) = p \cdot U(p)\) |
| Curve direction | From upper left to lower right | From lower left to upper right |
| Random baseline | Horizontal line (height = ATE) | Diagonal line (\(p \cdot\) ATE) |
| Qini area | Between the curve and the horizontal baseline | Between the curve and the diagonal baseline |
The two plots contain exactly the same information. The choice is a matter of preference: the average uplift curve is more intuitive for showing “whether the ranking works,” while the cumulative gain curve is more intuitive for showing “how much value is actually gained.” This article uses the former to stay consistent with the formulas above.
A Real Strategy Optimization Case
The previous sections mainly focused on theory and methods. Now let us shift the perspective from the model itself back to a more general strategy optimization framework.
Whether it is coupon distribution in e-commerce, advertising incentives, live-stream regulation, or traffic allocation in recommender systems, the underlying question is the same: for a given user, is it worthwhile to apply a certain intervention?
These problems can all be abstracted into a unified gain-cost trade-off framework:
- Gain: the core business value we hope to improve after intervention
- Cost: the resource consumption, side effects, or local business loss caused by the intervention
The method itself does not depend on any particular vertical. What really changes across businesses is only how the gain metric and the cost metric are defined.
| Scenario | Treatment | Gain metric | Cost metric |
|---|---|---|---|
| E-commerce marketing | Send coupons, add subsidies, increase touch frequency | Order rate, GMV, 7-day LT | Coupon cost, subsidy spending, gross-margin loss |
| Ad delivery | Raise bids, increase exposure, give incentives | Clicks, conversions, ad revenue | Traffic occupancy, subsidy cost, UX degradation |
| Content / live-stream distribution | Increase or decrease exposure of certain content types, adjust traffic share | Retention, sessions, duration, long-term value | Revenue decline in sub-businesses, ecosystem metric fluctuations |
If we only stare at a single gain metric, the strategy is easy to distort. Only when gain and cost are modeled and decided together does the strategy become meaningful for online deployment.
Overall Pipeline
A complete uplift strategy pipeline can usually be abstracted as follows:
- Construct treatment / control data through randomized experiments
- Train uplift models to estimate each user’s incremental gain and incremental cost
- Under budget or other constraints, convert model scores into executable decisions
- Continuously monitor online and update the strategy dynamically

Data Construction
RCT / Switchback experiment design
There is no single form of experiment. Common designs include:
- User-level randomized experiments: suitable for independently applied interventions such as coupons and ad incentives
- Switchback Experiments: suitable for interventions at the supply, traffic, or time-window level
- Bucketed gray-release experiments: suitable for gradually scaling online strategies
All of them share the same goal: make treatment assignment as random as possible, thereby reducing selection bias and improving the credibility of uplift estimation.
When running these experiments, there are at least three points that require special attention:
- Whether the randomization truly covers key user segments evenly
- Whether external traffic strategies or business campaigns interfere during the experiment
- Whether the sample size is large enough to support learning heterogeneous treatment effects
Many uplift projects fail not because of the model, but because the experiment design is not clean enough.
Feature and Label Design
In a general uplift project, features usually cover multiple categories such as users, behaviors, and context. For example:
| Feature category | Example features | Business meaning |
|---|---|---|
| Basic user features | Age, gender, registration age | Basic user attributes |
| Historical transaction features | Number of orders, AOV, repurchase interval | Commercial value and purchase habits |
| Ad interaction features | Impressions, clicks, conversions, incentive claims | Advertising sensitivity |
| Content consumption features | Duration, completion rate, number of interactions | Content preference and attention allocation |
| Price sensitivity features | Preferred price band, discount usage rate | Sensitivity to subsidies and promotions |
| Device and environment features | Device model, network, region, time period | External constraints and scenario differences |
| Traffic context features | Entry point, slot, slot competition | Current supply environment |
| User profile and segmentation | Interest tags, value tier, risk tags | User categorization |
| Social relationship features | Following, fans, mutual follows, sharing ties | Social diffusion potential |
| Trend features | 7d/30d differences, ratios, slopes | State changes |
There is an important practical lesson here: the key in uplift feature engineering is not only improving response prediction, but also exposing heterogeneity—i.e. “who is more sensitive to the intervention.” Therefore, features that reflect trends, state transitions, and differences in consumption structure are often more important than static user profiles.
Under this general framework, it is usually advisable to split labels into two types.
1. Gain Label
Represents the incremental benefit on the business’s core objective after intervention.
Examples:
- E-commerce: 7-day order rate, GMV, repurchase, long-term value
- Advertising: CTR, conversion rate, ad revenue, advertiser ROI
- Content / live streaming: retention, effective sessions, watch time, long-term active value
2. Cost Label
Represents the resource consumption or side effects that must be paid after intervention.
Examples:
- E-commerce: coupon cost, subsidy consumption, gross-margin loss
- Advertising: traffic occupancy, subsidy cost, decline in user experience
- Content / live streaming: decline in revenue of a sub-business, supply-ecosystem volatility, duration migration loss
This is crucial: many strategies only predict gain and do not predict cost. As a result, once deployed online, they often run into the problem that “the primary metric improved, but the business side effects were too large.” Modeling gain and cost separately is essentially preparation for constrained optimization downstream.
3. Multi-label scenarios
When there are multiple optimization targets, there are often multiple labels as well (for example, in LT optimization the cost label may simultaneously affect both watch time and revenue). In that case, we need to consider how to merge multiple labels into one so that the model can learn more easily and downstream planning can be solved more conveniently. A common approach is to directly use the raw labels and align their scales with manually chosen weights, as follows:
\[ y = w_1 y_1 + w_2 y_2 + w_3 y_3 \]
But this approach has several obvious problems:
- Hyperparameters are hard to tune
- Strongly affected by outliers
- Once the distribution drifts, stability becomes poor
In practice, a more common method is percentile normalization, i.e. use each sample’s relative position in the training set to replace the raw value itself:
\[ y = w_1 * \text{percentile\_rank}(y_1) + w_2 *\text{percentile\_rank}(y_2) + w_3 * \text{percentile\_rank}(y_3) \]
The advantages are quite clear:
- The \(\text{percentile\_rank}\) function maps raw labels with different units into a fixed range such as
[0, 1], making learning easier - The exchange rate among different objectives becomes more controllable. By keeping the values of \(w\) the same, the objectives can be given equal weight; or one can manually define an exchange rate, and it becomes less sensitive to score drift in any specific target (for example, if target A is uniformly overestimated by 10x)
- More robust to outliers
- Better aligned with downstream ranking-based decisions
This is a classic engineering trade-off: in real business settings, the model often does not need to estimate absolute returns perfectly; what matters more is ranking relative priority correctly.
Model Selection and Evaluation
If we want a relatively robust heterogeneous-effect learner across multiple business scenarios, Causal Forest is often a good starting point. The reasons were already discussed in the cross-method comparison above, so I will not repeat them here.
The offline evaluation metrics were also discussed earlier. In practice, what matters more is whether AUUC and Qini are consistent between the training and test sets, and whether uplift ranking is stable across different buckets.
There are two phenomena that occur frequently and are easy to misread:
1. The absolute AUUC of a sparse cost label may be very small
If a cost metric contains many zeros and is extremely sparse, then even if the model ranks correctly, the absolute AUUC may still be small. This does not necessarily mean the model is useless; it may simply reflect the low information density of the label itself.
2. AUUC for some cost-related metrics may be negative
This often appears in “suppressive interventions,” such as reducing exposure of a certain content type, compressing a certain subsidy, or lowering the traffic share of a certain format. In such cases, the purpose of the treatment is to sacrifice a local metric in exchange for overall gain, so a negative uplift on the cost dimension may actually mean the direction is working as intended.
Therefore, when evaluating uplift models, we should not look at any one gain or cost metric in isolation. Instead, we should interpret their directionality and trade-offs together with the strategic objective.
Online Decision-Making
At this point, we have trained two models to estimate \(\Delta \text{gain}\) and \(\Delta \text{cost}\) before and after applying treatment.
But what creates real business value is not simply assigning an uplift score to each user. The real problem is to make the optimal choice between Gain and Cost.
Optimization Problem Definition
We can naturally formulate the following constrained optimization problem.
Suppose there are \(n\) users, and after intervention on user \(i\):
- The estimated business gain is \(\text{gain}_i\)
- The estimated business cost is \(\text{cost}_i\)
Define the decision variable:
\[ x_i \in \{0, 1\} \]
where \(x_i = 1\) means applying the intervention to user \(i\).
If the budget or business-loss constraint is \(C\), then the optimization objective can be written as:
\[ \begin{aligned} \max_{x_i} \quad & \sum_{i=1}^{n} x_i \cdot \text{gain}_i \\ \text{s.t.} \quad & \sum_{i=1}^{n} x_i \cdot \text{cost}_i \le C \\ & x_i \in \{0, 1\} \end{aligned} \]
This is essentially: “under limited cost, choose the people most worth intervening on.”
To solve this directly, we can construct the following Lagrangian:
\[ L(x, \lambda) = \sum_{i=1}^n x_i (\text{gain}_i - \lambda \cdot \text{cost}_i) + \lambda C \]
To maximize \(L\), for each independent \(i\), the decision logic is:
- If \((\text{gain}_i - \lambda \cdot \text{cost}_i) > 0\), i.e. \(\frac{\text{gain}_i}{\text{cost}_i} > \lambda\), then choose \(x_i = 1\)
- If \(\frac{\text{gain}_i}{\text{cost}_i} < \lambda\), then choose \(x_i = 0\)
Here \(\lambda\) can be interpreted as the shadow price of cost.
This conclusion is important because it shows that under a given cost constraint, ranking by gain per unit cost (ROI) has an optimization foundation.
Approximate Solution: Greedy Strategy
Directly using the Lagrangian has two engineering inconveniences:
- It requires an explicit budget \(C\). But when cost is formed by fusing multiple metrics and then normalized, \(C\) often loses its physical meaning (unlike coupon scenarios, where the budget is explicit money), so one can only pick a value heuristically from the distribution
- The solution depends on the absolute accuracy of gain and cost. But after label normalization, sample-selection bias, and other adjustments, uplift model outputs often have systematic offsets. Once \(\lambda\) is fixed, if the model overestimates gain the system overspends; if it underestimates, the budget is left unused
In engineering practice, a greedy strategy is more common:
- Compute \(\text{ROI}_i = \dfrac{\text{gain}_i}{\text{cost}_i}\) for each user
- Sort users by ROI from high to low
- Accumulate cost from the top until budget \(C\) or a population-ratio threshold is reached
The greedy strategy and the Lagrangian are equivalent in solution: if we sort users by ROI and take them from highest to lowest, then the ROI of the last selected user is the implicit optimal shadow price \(\lambda^\star\). All users above that point satisfy the Lagrangian optimality condition \(\text{gain}_i - \lambda^\star\,\text{cost}_i > 0\). In other words, the greedy method uses ranking plus accumulation to implicitly perform dual ascent and find \(\lambda^\star\), avoiding the need to solve a nonlinear equation explicitly.
Compared with explicit Lagrangian solving, the greedy strategy has two engineering advantages:
1. More robust to estimation bias
Explicit Lagrangian solving requires the absolute values of gain and cost to be accurate; otherwise a fixed \(\lambda\) leads to overspend or budget underuse. By contrast, greedy selection only requires the relative ranking to be correct. If we truncate by user quantile or by a dynamic budget pool, then no matter how the scores drift, we still pick the users who are currently most worth treating.
2. More efficient online computation
Greedy solving reduces to “score + sort + threshold comparison,” which can be precomputed offline or nearline, and is much faster than solving nonlinear equations online.
Smooth Treatment: From Hard Thresholds to Soft Intensity
Whether we use the Lagrangian or a greedy strategy, the result so far is a hard-threshold decision: if \(\text{ROI} > \lambda^\star\), fully intervene; otherwise, do not intervene at all. In many businesses, this 0/1 decision is suboptimal for two reasons:
1. It removes room for exploration
If the treatment is a strong intervention such as “do not show a certain content genre,” then for high-ROI users, completely not showing it means the system will never observe those users’ true feedback to that genre. That permanently eliminates exploration for those users, which is often unacceptable for businesses that still want to expand penetration.
2. Integer solutions can waste budget
For example, suppose the budget is \(C = 2.5\) and there are two users:
- User A: \(\text{gain}=10\), \(\text{cost}=2\), \(\text{ROI}=5\)
- User B: \(\text{gain}=8\), \(\text{cost}=2\), \(\text{ROI}=4\)
Under a hard threshold (greedy or Lagrangian, same result): choose A first (cost = 2 ≤ 2.5); when considering B, the accumulated cost would become 4 > 2.5, so B must be discarded. The final gain is 10, and the remaining 0.5 budget is wasted.
If we allow the treatment intensity to be shared (continuous \(x_i \in [0,1]\), interpreted as a probability or intensity ratio), then we could allocate cost 1.5 to A (75% intensity) and 1 to B (50% intensity). Assuming gain and cost scale proportionally, the total gain becomes \(10 \times 0.75 + 8 \times 0.5 = 11.5 > 10\).
The form of the optimal LP-relaxed solution
LP Relaxation is one of the most classical approximate solving techniques in combinatorial optimization—it relaxes the integer constraint \(x_i \in \{0,1\}\) into the continuous constraint \(x_i \in [0,1]\). The original problem then becomes a linear program, which can be solved exactly by KKT conditions or the simplex method.
The problem we face here is a knapsack problem. For the fractional knapsack, the optimal solution is exactly the greedy solution that sorts by ROI; this is a classical result with a rigorous proof. For the LP relaxation of the 0/1 knapsack, the optimal solution contains at most one fractional variable, and the gap to the integer optimum is bounded.
By relaxing the integer constraint \(x_i \in \{0,1\}\) to the continuous range \(x_i \in [0,1]\), and introducing the dual variable \(\lambda \ge 0\) for the budget constraint, the KKT conditions yield the following optimal solution:
\[ x_i^\star = \begin{cases} 1, & \text{ROI}_i > \lambda^\star \\ \in [0,1], & \text{ROI}_i = \lambda^\star \\ 0, & \text{ROI}_i < \lambda^\star \end{cases} \]
That is, users with ROI higher than the shadow price \(\lambda^\star\) are fully turned on, while those below it are fully turned off. This is still a step function, but it gives a key structural property: the optimal treatment intensity is a monotone non-decreasing function of ROI.
LP relaxation is especially suitable for budget-constrained uplift problems for several reasons:
- The structure of the solution is clear: the step form above directly matches the business intuition of “sort by ROI and take the top-K,” so model scores can be directly converted into executable strategies
- It naturally supports smoothing: continuous \(x_i\) can be interpreted as “probability / intensity,” which maps perfectly to smooth treatments in engineering (coupon probability, recommendation-score weighting, ranking penalty intensity, etc.), instead of requiring an additional “rounding to 0/1” step like integer solutions do
- Equivalent to greedy: for fractional knapsack, the LP solution is exactly the greedy ROI-sorting solution, so the greedy strategy in the previous section is itself the exact LP-relaxation solution under the knapsack structure and does not require an additional solver
An inherent property of the LP optimum: monotonicity
The KKT form above already implies that \(x_i^\star\) is monotone non-decreasing in \(\text{ROI}_i\), but this property does not depend on any particular functional form. It is an inherent property of any continuous-allocation problem under a budget constraint, and it can be rigorously proved using an exchange argument.
Consider two users \(i, j\) (with \(\text{cost}_i, \text{cost}_j > 0\)). Suppose \(\text{ROI}_i > \text{ROI}_j\), but assume for contradiction that in the optimal solution \(x_i^\star < x_j^\star\). We make a small budget transfer: take back \(\varepsilon\) units of cost from \(j\) and give them to \(i\):
- Decrease \(x_j\) by \(\dfrac{\varepsilon}{\text{cost}_j}\), which frees \(\varepsilon\) units of cost
- Increase \(x_i\) by \(\dfrac{\varepsilon}{\text{cost}_i}\), which consumes the same \(\varepsilon\) units of cost
Total cost is unchanged, so the budget constraint is still satisfied. The change in the objective is:
\[ \Delta \text{Obj} = \frac{\varepsilon}{\text{cost}_i}\cdot\text{gain}_i - \frac{\varepsilon}{\text{cost}_j}\cdot\text{gain}_j = \varepsilon \cdot (\text{ROI}_i - \text{ROI}_j) > 0 \]
So we can strictly improve the objective, which contradicts the assumption that the original allocation was optimal. Therefore the optimum must satisfy \(x_i^\star \ge x_j^\star\).
This exchange argument does not assume any specific functional form. The conclusion is an objective fact: as long as budget can be allocated continuously and ROI is well-defined (cost > 0), the optimal allocation must be monotone non-decreasing in ROI. Fractional knapsack, network-flow allocation, and ad bidding all follow the same mechanism.
Choosing a mapping function
The KKT step form cannot be deployed directly (it is non-differentiable and leaves no exploration), so in engineering we look for a function \(f(\text{ROI})\) to approximate it. This function must satisfy:
- Monotone non-decreasing—this is forced by the exchange argument above; otherwise it is not a valid approximation to the LP optimum
- Smooth and differentiable—convenient for end-to-end training and gradient optimization
- Range \([0,1]\)—consistent with the semantics of a probability / intensity
- Transition around \(\text{ROI} = \lambda^\star\)—to preserve the shape of the step solution
Many function families satisfy these conditions:
| Function family | Form | Comment |
|---|---|---|
| Sigmoid | \(\sigma\!\big(\alpha(\text{ROI} - \lambda^\star)\big)\) | Most common; \(\alpha\) controls steepness |
| Hardsigmoid / piecewise linear | \(\text{clip}(\alpha(\text{ROI} - \lambda^\star) + 0.5,\,0,\,1)\) | Cheaper to compute |
| Any monotone distribution CDF | \(F(\text{ROI})\) | More natural probabilistic interpretation (e.g. truncated normal) |
| Softplus composition | \(1 - e^{-\text{softplus}(\alpha(\text{ROI}-\lambda^\star))}\) | More flexible for tail control |
In engineering, sigmoid is usually chosen mainly because the form is simple, differentiable everywhere, and easy to tune in practice—not because it is mathematically “more optimal.” Replacing it with any other monotone smooth function leads to the same underlying conclusion.
At the end of the day, what often takes effect online is a simple rule: “the higher the ROI, the stronger the treatment intensity.”
This also makes intuitive sense: under a budget constraint, allocate more resources to people with higher marginal returns. A high ROI means the intervention is more cost-effective for that user, so naturally that user should receive more treatment intensity. This is simply the law of resource allocation under constrained optimization, and it is the same principle by which higher bidders obtain more resources in an auction.
Therefore, the online advantages of smooth mappings are often:
1. Preserve exploration space and mitigate feedback loops
2. Use the budget more fully (avoiding waste caused by hard integer discard)
3. Allocate different treatment intensities to different users, enabling finer-grained intervention
Adaptive Distributions
After a strategy is deployed, the data distribution is very likely to change.
Common issues include:
1. Drift in the uplift ROI distribution
A common solution is to normalize the scores again and map them into a stable interval [a, b], so that thresholds and quantiles remain more controllable.
2. Long-term right-shift or left-shift in business metrics
For example, AOV, conversion value, watch time, ad bids, and similar metrics may keep shifting as the business evolves. In that case, the model score itself may still be fine, but the decision thresholds and the budget mapping gradually become distorted.
So after an uplift strategy goes online, we should not only ask whether the model has been updated. We should continuously monitor:
- Whether the score distribution has drifted
- Whether population coverage has become abnormal
- Whether the gain / cost ratio has changed
- Whether side effects of the strategy have expanded
The Feedback-Loop Trap
After a strategy goes online, the easiest trap to fall into is directly retraining the model on online data. This is a problem that is unique to uplift and more serious than in CTR/CVR modeling, so it is worth discussing separately.
Once an online uplift strategy is deployed, treatment assignment is no longer random: high-score users are almost always treated, while low-score users are almost never treated. This directly breaks two key assumptions behind uplift estimation:
- Overlap: \(0 < P(T=1 \mid X=x) < 1\) → high-score populations become almost all \(T=1\), low-score populations become almost all \(T=0\), and the overlap region disappears
- Unconfoundedness: \(T \perp (Y(1), Y(0)) \mid X\) → treatment assignment itself becomes a function of the model score, so confounding is introduced
If we directly retrain on this batch of “data already selected by the strategy,” the model will learn the strategy’s own selection bias as if it were a causal effect. In the next round, the scores become more extreme, interventions become more concentrated, and the bias gets amplified further—a classic feedback loop.
CTR and CVR models have a related issue as well, but for uplift it is much more severe:
| Dimension | CTR / CVR | Uplift |
|---|---|---|
| Learning target | \(P(Y \mid X)\), a single conditional distribution | \(E[Y(1) - Y(0) \mid X]\), which requires two counterfactual distributions |
| Type of bias | Even with exposure bias, the model can still learn; it mainly increases variance | Once overlap is broken, the effect becomes directly unidentifiable; this is bias, not variance |
| Signal strength | Labels are dense and signal is strong | Uplift is the difference of two numbers; the signal itself is 1–2 orders of magnitude weaker |
| Error accumulation | One-directional accumulation in \(P(Y \mid X)\) | Two-directional accumulation in \(\hat{\mu}_1 - \hat{\mu}_0\), and strategy drift accelerates it |
Intuitively: even with selection bias, a CTR model is at least still learning “will this group click?” But once an uplift model loses overlap, what it learns is not the causal effect at all, but the strategy selection rule itself.
Common engineering corrections include the following:
| Method | Idea | Cost |
|---|---|---|
| Keep a random holdout bucket | Always reserve 5%–10% of traffic for random assignment online; use only this part to retrain or calibrate | Sacrifice a small amount of online revenue in exchange for continued identifiability. The most common industrial solution |
| IPW (Inverse Probability Weighting) | Weight samples by the actual online assignment probability \(\hat{e}(x)\) to correct selection bias | Requires \(\hat{e}(x)\) to stay away from 0/1, otherwise variance explodes |
| Doubly Robust | Use both the response model and the propensity score; if one is biased, the other can still compensate | More complex to implement, but the best robustness |
| Periodic full RCT | Periodically pause the strategy and collect a fully randomized dataset | Larger short-term business volatility; often used in early stages or periodic recalibration |
In practice, the holdout random bucket is usually the most cost-effective solution: it preserves the identifiability of an RCT without requiring frequent pauses to the strategy. At the same time, the holdout bucket can also naturally be used for model A/B comparisons, Qini-curve evaluation, threshold calibration, and more.
The simplest rule to remember is: the training data for uplift models must preserve randomness in treatment assignment. The model cannot directly train on its own policy-generated data, otherwise it is reinforcing bias rather than learning causality.
Multiple Treatments and Continuous Treatments
Everything discussed so far has focused mainly on a single binary treatment. But in real business settings, more complex forms are common:
- Multiple Treatments: multiple discrete intervention types exist (such as coupons with different face values, or different ad creatives)
- Continuous Treatment: the intervention differs in strength or dosage (such as discount size, subsidy amount, or exposure frequency)
These two classes of scenarios differ substantially from the binary case in identification assumptions, modeling methods, and decision solving, so we discuss them separately below.
Shared Causal Identification Assumptions
The three assumptions for binary treatment (unconfoundedness, overlap, SUTVA) need corresponding extensions:
Unconfoundedness: must hold for all \(t\)
\[\{Y(t)\}_{t \in \mathcal{T}} \;\perp\; T \;\big|\; X\]
That is, conditional on \(X\), treatment assignment \(T\) must be independent of all possible potential outcomes. In practice, this usually requires multi-arm RCTs (for multiple treatments) or dose randomization (for continuous treatment).
Overlap: extends to requiring observed samples for every \(t\)
- Multiple treatments: \(P(T=t \mid X=x) > 0, \quad \forall t \in \{0, 1, \dots, K\}\)
- Continuous treatment: conditional density \(f_{T \mid X}(t \mid x) > 0, \quad \forall t \in \mathcal{T}\)
This is one of the easiest assumptions to violate in real business settings. For example, if some treatment is only assigned to specific populations by the online strategy, then \(P(T=t \mid X=x)\) is 0 for all other populations, and the model cannot identify \(\tau(x, t)\) on those populations.
Generalized Propensity Score (GPS): this is the extension of the binary propensity score \(P(T=1 \mid X)\)
- Multiple treatments: \(e_t(x) = P(T=t \mid X=x)\), one for each \(t\)
- Continuous treatment: \(e(t, x) = f_{T \mid X}(t \mid x)\), a conditional density
GPS is the basis for later estimators such as IPW, DR, and weighted regression (Imbens 2000; Hirano & Imbens 2004).
Multiple-Treatment Scenarios
When multiple intervention choices exist, the problem changes from “whether to intervene” to “which intervention should be used.”
Problem Definition
Suppose there are \(K+1\) treatment values \(t \in \{0, 1, \dots, K\}\), where \(t=0\) means no intervention. Each treatment corresponds to one potential outcome \(Y_i(t)\), and the individual treatment effect relative to no intervention is \(\tau_i(t) = Y_i(t) - Y_i(0)\).
Since the ITE \(\tau_i(t)\) is unobservable, the actual modeling target is the CATE:
\[\tau(x, t) = E[Y(t) - Y(0) \mid X = x], \quad t \in \{1, \dots, K\}\]
The optimal treatment decision is defined on top of the estimated CATE:
\[\hat{t}^\star(x) = \arg\max_{t \in \{0, 1, \dots, K\}} \hat{\tau}(x, t)\]
where \(\hat{\tau}(x, 0) \equiv 0\).
Common Modeling Methods
1. One-vs-All (OVA)
Decompose the multiple-treatment problem into \(K\) binary uplift subproblems, each estimated independently:
\[\hat{\tau}_k(x) = \hat{E}[Y(k) - Y(0) \mid X=x], \quad k=1,\dots,K\]
Then choose the treatment with the largest estimated increment: \(\hat{t}^\star(x) = \arg\max_k \hat{\tau}_k(x)\).
The advantage is that it can directly reuse existing binary uplift models. But the disadvantages are deeper than merely “training \(K\) models”:
- Low sample efficiency: when training \(\hat{\tau}_k\), only treatment \(k\) and control samples are used; data from other treatment groups are discarded
- Biases are not comparable in the final horse race: the \(K\) independent models may each have biases of different directions and scales, and the argmax is polluted by those relative biases—if one \(\hat{\tau}_k\) is systematically overestimated, it may always be selected
- It does not enforce \(\hat{\tau}(x, 0) = 0\)
2. Multivalued S-Learner
Feed the treatment as a multi-valued categorical feature into a single model:
\[\hat{\mu}(x, t) = \hat{E}[Y \mid X=x, T=t]\]
At prediction time, enumerate all \(t\) and choose the largest uplift:
\[\hat{t}^\star(x) = \arg\max_t \big(\hat{\mu}(x, t) - \hat{\mu}(x, 0)\big)\]
This is the multivalued version of the S-Learner. It requires unconfoundedness for all \(t\) and the extended overlap assumption. Its advantage is that it can learn shared structure across treatments and use all samples for training; its disadvantage is inherited from the S-Learner—the treatment signal may be washed out by strong regularization.
3. Pairwise Comparison
Estimate the relative advantage for every pair \((j, k)\):
\[\hat{\tau}_{jk}(x) = \hat{E}[Y(j) - Y(k) \mid X=x]\]
This requires \(\binom{K+1}{2} = O(K^2)\) models. The pairwise results can then be aggregated using methods such as Borda count or Bradley-Terry.
The main risk is broken transitivity: one may get a cycle such as \(\hat{\tau}_{12} > 0\), \(\hat{\tau}_{23} > 0\), but \(\hat{\tau}_{13} < 0\), due to inconsistencies from independent estimation. So when \(K \ge 4\), pairwise modeling is usually not used directly.
4. DR-Learner / GPS-weighted methods (more modern approaches)
Directly construct a doubly robust pseudo-outcome for each treatment:
\[\tilde{Y}_i(t) = \hat{\mu}(X_i, t) + \frac{\mathbb{1}\{T_i=t\}}{\hat{e}_t(X_i)} \big(Y_i - \hat{\mu}(X_i, t)\big)\]
Then regress \(\tilde{Y}_i(t) - \tilde{Y}_i(0)\) to obtain \(\hat{\tau}(x, t)\). The advantage is that consistency is guaranteed as long as either \(\hat{\mu}\) or \(\hat{e}_t\) is estimated well, and sample efficiency is higher than OVA. Causal Forest and EconML both provide multiple-treatment variants.
Joint decision under a budget constraint
A more realistic business problem is: under a budget constraint, decide both “which users should be treated” and “which treatment each user should receive.” Let the decision variable \(x_{it} \in \{0,1\}\) indicate whether treatment \(t\) is applied to user \(i\) (\(t=0\) means no treatment, and \(\text{gain}_i(0) = \text{cost}_i(0) = 0\)):
\[ \begin{aligned} \max_{\{x_{it}\}} \quad & \sum_{i=1}^n \sum_{t=1}^K x_{it} \cdot \text{gain}_i(t) \\ \text{s.t.} \quad & \sum_{i=1}^n \sum_{t=1}^K x_{it} \cdot \text{cost}_i(t) \le C \\ & \sum_{t=0}^K x_{it} = 1, \quad \forall i \\ & x_{it} \in \{0, 1\} \end{aligned} \]
The second constraint enforces that each user can receive at most one treatment (including “no treatment”). This is a Multiple Choice Knapsack Problem (MCKP), which is NP-hard.
A practical approximate greedy solution is:
- Enumerate all \((i, t)\) pairs (with \(t \ne 0\)), and compute \(\text{ROI}_{it} = \text{gain}_i(t) / \text{cost}_i(t)\)
- Sort all pairs globally in descending ROI order
- Select pairs in that order, keeping only the first selected treatment per user (per-user dedup), until accumulated cost reaches \(C\)
The simple “per-user argmax + global sort” approach (first choose each user’s highest-ROI treatment, then sort users globally) is not optimal for MCKP—it throws away the alternatives that have slightly lower ROI but much smaller cost. A more standard solution is to solve the LP relaxation for \(\lambda^\star\), then let each user independently choose \(\arg\max_t (\text{gain}_i(t) - \lambda^\star \cdot \text{cost}_i(t))\), and finally use binary search on \(\lambda^\star\) so that total cost approaches \(C\).
Continuous-Treatment Scenarios
When the treatment is a continuous variable like “how much to do” (discount size, bid, exposure frequency), the target becomes estimating a Dose-Response Curve (DRC).
Problem Definition
Treatment \(t\) takes values in \(\mathcal{T} \subseteq \mathbb{R}\). In the continuous setting, uplift has two reasonable definitions:
Absolute uplift (relative to no treatment or a baseline dose \(t_0\))
\[\tau(x, t) = E[Y(t) - Y(t_0) \mid X = x]\]
This is suitable for decisions such as “on vs. off” or “increase vs. not increase.”
Marginal uplift (the gain change brought by one additional unit of dose)
\[\partial_t \mu(x, t) = \frac{\partial}{\partial t} E[Y(t) \mid X = x]\]
This is suitable for dose optimization and finding the optimal turning point.
Both are derived from the same DRC \(\mu(x, t) = E[Y(t) \mid X=x]\); the only difference is whether we care about the integral or the derivative.
Common Modeling Methods
1. Dose-Response Network (DRNet, Schwab et al. 2020)
A neural-network structure with a shared representation and multiple heads: partition the dose space into \(M\) sub-intervals \([t_m, t_{m+1}]\), and assign one head to each interval, while all heads share the first few encoder layers:
\[\hat{\mu}(x, t) = \sum_{m=1}^M \mathbb{1}\{t \in [t_m, t_{m+1}]\} \cdot h_m(\phi(x), t)\]
The shared \(\phi(x)\) greatly improves sample efficiency relative to independent models; within each interval, \(h_m(\cdot, t)\) can use linear or spline interpolation to avoid boundary jumps.
2. Continuous Meta-Learners
Extend the Meta-Learner framework to continuous \(T\). Common approaches include:
- Treat \(t\) as an input feature in an extended S-Learner: \(\hat{\mu}(x, t) = f(x, t)\)
- Train T-Learners at each dose quantile, then interpolate
- Continuous X-Learners combined with GPS weighting
At prediction time, search over \(t\) using either a grid search or gradient ascent to find the optimal dose.
3. GPS weighting and IPW estimation
Use the generalized propensity score \(\hat{e}(t, x) = \hat{f}_{T \mid X}(t \mid x)\) to perform kernel-weighted IPW estimation:
\[\hat{\mu}(x, t) = \frac{\sum_i K_h(t - T_i) \cdot \frac{1}{\hat{e}(T_i, X_i)} \cdot Y_i}{\sum_i K_h(t - T_i) \cdot \frac{1}{\hat{e}(T_i, X_i)}}\]
where \(K_h\) is a kernel with bandwidth \(h\). Direct IPW can suffer exploding variance when the estimated density is small, so in engineering practice people often use:
- Stabilized weights: \(w_i = \hat{f}_T(T_i) / \hat{e}(T_i, X_i)\), where the numerator is the marginal density of \(T\), which can substantially control variance
- Weight clipping: clip weights into a range such as \([0.01, 100]\)
- Doubly robust variants (such as DR-DRC in Kennedy et al. 2017)
4. Modern neural-network methods
VCNet (Variational Counterfactual Networks), SCIGAN, and other architectures are specifically designed for continuous treatment. They further combine representation learning with GPS adjustment, and have become a mainstream direction in recent research.
Choosing the optimal dose
Given user features \(x\), the optimal dose under a budget constraint can be written as the following Lagrangian problem with \(\lambda\):
\[t^\star(x) = \arg\max_{t \in \mathcal{T}} \big(\text{gain}(x, t) - \lambda \cdot \text{cost}(x, t)\big)\]
When \(t\) is continuously differentiable, the first-order condition gives:
\[\partial_t \text{gain}(x, t) = \lambda \cdot \partial_t \text{cost}(x, t)\]
That is, marginal gain equals the shadow price times marginal cost—each additional unit of dose should bring exactly enough extra benefit to offset its extra cost. The value of \(\lambda\) is recovered from the global budget constraint \(\int t^\star(x) \, dF(x) \le C\).
In practice, this is often approximated by grid search:
- Sample a discrete set \(\{t_1, \dots, t_M\}\) on \(\mathcal{T}\)
- For each user and each \(t_m\), predict \(\hat{\text{gain}}\) and \(\hat{\text{cost}}\)
- Choose \(\arg\max_m (\hat{\text{gain}}(x, t_m) - \lambda \cdot \hat{\text{cost}}(x, t_m))\)
- Use binary search on \(\lambda\) so that the global cost hits the budget
Note that here we cannot simply rank by ROI = gain / cost: under continuous dose, the optimum is characterized by the first-order condition (matching marginal gain to marginal cost), which is not equivalent to maximizing ROI. Only when cost is linear in \(t\) (i.e. \(\text{cost}(x,t) = c(x) \cdot t\)) does ROI ranking coincide with the Lagrangian optimum.
Engineering Challenges
| Challenge | Multiple Treatments | Continuous Treatment |
|---|---|---|
| Causal identification | Need unconfoundedness for all \(t\); every \(t\) must satisfy overlap \(P(T=t\|X) > 0\) | Same, but overlap becomes a density condition \(f_{T\|X}(t\|x) > 0\), which makes density estimation harder |
| Experiment design | Multi-arm RCT or stratified switchback; sample size grows roughly linearly with \(K\) | Dose randomization (e.g. uniform dose sampling, or a fixed dose set with random assignment); density coverage must be adequate |
| Model complexity | OVA is \(O(K)\), pairwise is \(O(K^2)\); joint modeling can mitigate this | Need to learn a continuous function; GPS estimation itself is already a nontrivial density-estimation problem |
| GPS-estimation stability | Discrete GPS only needs a multiclass model | Conditional density estimation (normalizing flow, kernel) is unstable in the tails; stabilized weights / clipping are often needed |
| Decision solving | MCKP, NP-hard; approximated via LP relaxation + binary search on \(\lambda\) | Lagrangian first-order condition + grid search; cannot directly use ROI ranking |
| Feedback loop | More severe than in the binary case—online strategies can cause some \((X, t)\) combinations to lack samples for a long time, so overlap keeps deteriorating | Same, and the bias in density estimation is further amplified by IPW |
From an engineering perspective, these two types of scenarios are clearly harder to deploy than the binary-treatment case. A common practical approach is to first use a binary RCT to verify the existence of an uplift signal, and only then extend to multiple or continuous treatments, so that we do not start with the hardest possible setup and step into multiple traps at once.
Summary and Outlook
The core of Uplift Modeling is not predicting “who will convert,” but estimating “whose behavior will change in net terms because of the intervention.” That is why it addresses a problem much closer to business decision-making: under limited budget and side-effect constraints, reserve intervention resources for the people most worth influencing.
With that goal in mind, this article discussed the following issues in sequence:
First, why traditional prediction can only answer correlation and not counterfactuals;
Second, how potential outcomes, CATE, unconfoundedness, overlap, and SUTVA form the causal foundation of uplift;
Third, how S/T/X-Learners, Uplift Trees, and Causal Forests correspond to different modeling trade-offs;
Fourth, how AUUC, Qini, and cumulative gain curves are used to evaluate whether the ranking is effective;
Fifth, how real-world deployment requires stitching together gain-cost modeling, budget constraints, smooth treatment, and feedback-loop correction into a full strategy pipeline;
Sixth, how modeling methods should be adapted in multiple-treatment and continuous-treatment scenarios
Precisely because of this, the real difficulty of uplift often lies not only in the model, but in whether the experiment design is clean enough, whether gain and cost are defined completely, whether the online strategy preserves exploration, and whether retraining can avoid the continuous accumulation of selection bias. The model is only a middle link; strategy optimization is the final objective.
Looking further ahead, the directions most worth deeper exploration include causal identification under network effects, joint decision-making for multiple and continuous treatments, and combining uplift with contextual bandits or reinforcement learning. Binary uplift is often only the starting point; real production problems are usually more complex.
If I continue expanding this topic later, the engineering details I would most like to write separately about are: pitfalls in AUUC / Qini implementation, sample and feature design for Causal Forest / DR-Learner, and online usage patterns for smooth treatment and random holdout.
References
- Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies (Source). Journal of Educational Psychology, 66(5), 688–701.
- Künzel, S. R., Sekhon, J. S., Bickel, P. J., & Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning (PDF). Proceedings of the National Academy of Sciences, 116(10), 4156–4165.
- Wager, S., & Athey, S. (2018). Estimation and inference of heterogeneous treatment effects using random forests (PDF). Journal of the American Statistical Association, 113(523), 1228–1242.
- Athey, S., & Wager, S. (2019). Estimating treatment effects with causal forests: An application (PDF). Observational Studies, 5(2), 37–51.
- Athey, S., & Imbens, G. W. (2016). Recursive partitioning for heterogeneous causal effects (PDF). Proceedings of the National Academy of Sciences, 113(27), 7353–7360.
- Radcliffe, N. J., & Surry, P. D. (2011). Real-world uplift modelling with significance-based uplift trees (PDF). Stochastic Solutions White Paper TR-2011-1.
- Gutierrez, P., & Gérardy, J.-Y. (2017). Causal inference and uplift modelling: A review of the literature (PDF). In Proceedings of the 3rd International Conference on Predictive Applications and APIs (PMLR, Vol. 67, pp. 1–13).
- Hirano, K., & Imbens, G. W. (2004). The propensity score with continuous treatments (Source). In A. Gelman & X.-L. Meng (Eds.), Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives (pp. 73–84). Wiley.
- Kennedy, E. H., Ma, Z., McHugh, M. D., & Small, D. S. (2017). Non-parametric methods for doubly robust estimation of continuous treatment effects (PDF). Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(4), 1229–1245.
- Schwab, P., Linhardt, L., Bauer, S., Buhmann, J. M., & Karlen, W. (2020). Learning counterfactual representations for estimating individual dose-response curves (PDF). Proceedings of the AAAI Conference on Artificial Intelligence, 34(4), 5612–5619.