创作者变现与加热
最近一段时间都在做一些跟创作者相关的业务,相较于商业传统的三方(平台、用户、广告主),创作者是随着内容平台崛起而诞生的第四方,与其他三方的关系可以参考笔者之前文章 Yet Another Overview of an AD System
本文也是对之前的文章里创作者相关的部分做进一步的展开,主要是商机和加热两大块,前者主要是包括对商机部分中涉及到的各个链路的职责,以及各个链路之间的联动关系;加热中的自投与代投的产品形态,以及在流量上与广告流量的协同关系等。
最近一段时间都在做一些跟创作者相关的业务,相较于商业传统的三方(平台、用户、广告主),创作者是随着内容平台崛起而诞生的第四方,与其他三方的关系可以参考笔者之前文章 Yet Another Overview of an AD System
本文也是对之前的文章里创作者相关的部分做进一步的展开,主要是商机和加热两大块,前者主要是包括对商机部分中涉及到的各个链路的职责,以及各个链路之间的联动关系;加热中的自投与代投的产品形态,以及在流量上与广告流量的协同关系等。
My earlier article An Overview of an AD System introduced the basic responsibilities and principles of various modules (retrieval, ranking, bidding, cold start, etc.) from a technical perspective. Several years have passed, and while that understanding hasn’t become outdated, after experiencing more business operations, I’ve gained a more comprehensive view of the overall commercialization. This article attempts to understand an advertising system from another, more systematic perspective.
The traditional understanding of an ad system typically involves three parties: advertisers/agencies, the platform, and users. However, with the rapid development of content platforms (such as Douyin, Kuaishou, Xiaohongshu, Bilibili, etc.), more and more UGC content has emerged, making creators’ influence in commercial monetization increasingly difficult to ignore. Therefore, a fourth party representing creators has been added to the traditional three-party model, as shown below.
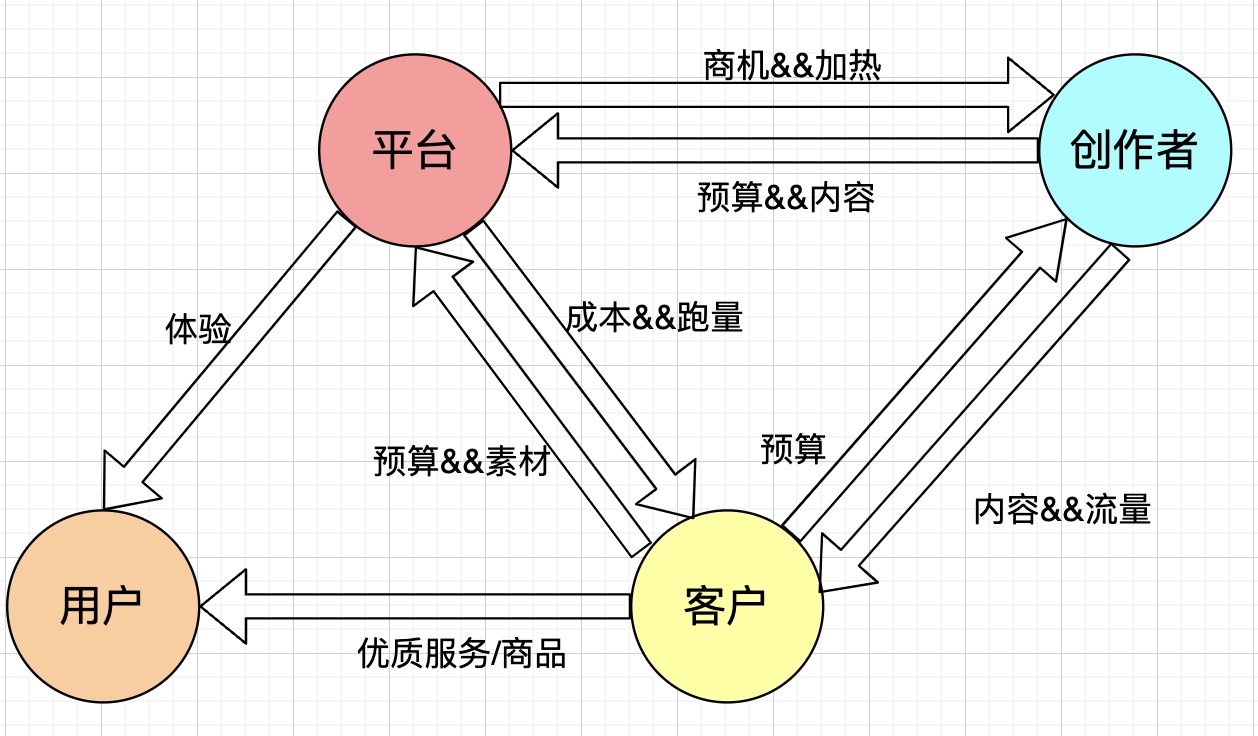
The complex relationships among these four parties generally exist on “first-party traffic” (borrowing the concept of first-party data), referring to platforms like Douyin/Kuaishou/Xiaohongshu/Bilibili that have the capability to build their own monetization teams and monetize on their own traffic. In contrast, “third-party traffic” scenarios generally only need to focus on the relationship between clients and the platform. A typical example is alliance scenarios (Chuanjia, Youlianghui, Kuaishou Alliance, etc.), where there are no strong user experience constraints on the user side because alliances are essentially traffic reselling businesses. The related technology is similar to first-party traffic, but there’s minimal attention to C-end user experience and creator aspects.
This article focuses on first-party traffic. The following content will discuss each party’s responsibilities and relationships with other parties according to the four parties mentioned above. The content will be somewhat scattered, but I hope you find it worthwhile.
之前写的 An Overview of an AD System, 从技术原理上介绍了各个模块(召回、精排、出价、冷启动等)的基本职责和原理,几年过去了,这部分的认知虽然还没过时,但是经历了更多业务后,对整体的商业化也有一个更全面认知,本文尝试从另一个更系统的角度去理解一个广告系统
传统认知中的 ad system 一般是三方:广告主 / 代理、平台、用户;但是随着内容平台(如抖音、快手、小红书、bilibili 等)的迅速发展,涌现了越来越多的 UGC 内容,创作者在商业变现中的影响也越来越难被忽视,所以这里基于三方增加了代表创作者的第四方,如下图所示
以上的四方比较复杂的关系,一般是存在于 “一方流量”(参考一方数据的概念)上,即抖音/快手/小红书/bilibili 这类有能力搭建自己的一方流量的变现团队,在自家的流量上变现;相较于 “一方流量”,“三方流量” 的场景一般只需要关注客户和平台的关系,典型的就是联盟的场景(穿山甲、优量汇、快手联盟等),对用户侧没有强体验约束,因为本质上联盟就是个倒卖流量的生意,相关技术与一方流量差不多,但是对 C 端的用户体验以及创作者部分基本不怎么关注。
本文重点在一方流量上,下面的内容会根据上图中提到四方依次讨论每一方本身的一些职责、与其他各方的关系,内容会比较发散,祝开卷有益~
《Systematic Trading: A unique new method for designing trading and investing systems》 is a comprehensive guide for traders and investors seeking a structured approach to the markets.
Aimed at both novices and experienced traders, the book offers practical insights and applications, making it a pretty good resource for anyone looking to enhance their trading methodology with a systematic approach.
This is not a book totally about automating trading strategies. It’s possible to trade systematically using an entirely manual process with just a spreadsheet to speed up calculations, so automation is not necessary, the key word if “systematic”. This passage mainly covers the first two chapters, providing a rough overview of this book. Hope you can enjoy it
最近半年经历了一些业务与组织上的变化,对于这部分也有了一些新的理解和体会,值得写一篇文章来梳理与总结。本文主要讲了对业务和组织的一些看法,包括如何看待 “矛盾” 的业务定位和观点、组织的进化过程、团队组建里的识人与用人等;以及在这个过程中,该如何调整自己的心态。文章比较发散,纯属个人碎碎念,祝开卷有益
“Quantitative Trading: How to Build Your Own Algorithmic Trading Business” by Ernie Chan is a comprehensive guide that explores the world of quantitative trading and provides practical advice for building a algorithmic trading business, especially for individuals interested in quantitative trading.
It covers essential concepts, methodologies, and practical tips to help readers develop and implement their own algorithmic trading strategies while effectively managing risk and building a sustainable trading business.
Due to the significant benefits I received from reading this book, I want to write down some of the most important takeways I get from this book, with the hope that it can also be useful to you.
This passage is about the last four chapters, which introduces execution system in actual trading(automated and semi-automated), how to minimize transaction cost and determine the optimal leverage using the Kelly Criterion. It also talks about some special topics or common sense in trading. Finally, it lists some advantages of individuals investors over institutional investors.
“Quantitative Trading: How to Build Your Own Algorithmic Trading Business” by Ernie Chan is a comprehensive guide that explores the world of quantitative trading and provides practical advice for building a algorithmic trading business, especially for individuals interested in quantitative trading.
It covers essential concepts, methodologies, and practical tips to help readers develop and implement their own algorithmic trading strategies while effectively managing risk and building a sustainable trading business.
Due to the significant benefits I received from reading this book, I want to write down some of the most important takeways I get from this book, with the hope that it can also be useful to you.
This passage is about the first four chapters, which introduce basic requirements for independent traders, including search for ideas, perform backtest, and what we need before conducting real trading.
“The Almanack of Naval Ravikant” is a book that compiles the wisdom and insights of entrepreneur and investor Naval Ravikant. This book mainly talks about two topics, wealth and happiness. It offers practical advice on how to live a more fulfilling and purposeful life.
Through his own experiences and perspectives, Naval provides readers with valuable insights into topics like success, motivation, and personal growth, making the book a useful guide for anyone looking to improve their life and achieve their goals
I have benefited greatly from reading this book, and I want to write some important takeaways from this book. As this book was written in English, I want to give it a try to write it in English, too. Hoping it will be beneficial to you, this passage is about the second topic: Happiness
The passage about the first topic: wealth, can be found here
“The Almanack of Naval Ravikant” is a book that compiles the wisdom and insights of entrepreneur and investor Naval Ravikant. This book mainly talks about two topics, wealth and happiness. It offers practical advice on how to live a more fulfilling and purposeful life.
Through his own experiences and perspectives, Naval provides readers with valuable insights into topics like success, motivation, and personal growth, making the book a useful guide for anyone looking to improve their life and achieve their goals
I have benefited greatly from reading this book, and I want to write some important takeaways from this book. As this book was written in English, I want to give it a try to write it in English, too. Hoping it will be beneficial to you, this passage is about the first topic: Wealth
In search/recommendation/advertising related businesses, besides common binary classification tasks like CTR and CVR, there are a series of regression tasks estimating stay_duration, LTV, ECPM, GMV, etc.
CTR/CVR binary classification tasks commonly use cross-entropy loss, with the basic assumption that events follow Bernoulli distribution, ultimately learning the proportion of positive samples. But regression tasks have many optional loss functions, like MSE, MAE, Huber loss, log-normal, weighted logistics regression, softmax, etc.
Each loss function has its assumptions and applicable scope. If the real label distribution differs significantly from assumptions, results can be poor. Therefore, this article focuses on the derivation process and assumptions of these common losses.