Uplift 建模与策略优化实践
很多业务问题表面上看是在做预测,真正要解决的却是干预决策。比如发优惠券、投广告、调整流量分发,真正的问题通常不是 “谁最可能转化”,而是对谁做干预,才能带来最大的净增量?
这两类问题的差异,决定了建模方式也完全不同。
传统预测模型擅长回答 “这个用户会不会买”、“这个用户会不会留存”;但它很难回答 “如果我发券,他会不会因此多买”“如果我减少直播曝光,他的长期价值会不会提升”。前者是相关性问题,后者是因果性问题。
Uplift Modeling 的价值,就在于把优化目标从结果预测,转向对干预增量的估计。相比 “找高概率用户”,它更关注 “找高增量用户”,从而实现在资源约束下的优化目标价值最大化。
本文尝试介绍 uplift 的基本原理和一个实际落地的应用场景,基本内容如下
- 为什么传统预测模型不适合直接指导干预策略
- Uplift Modeling 背后的因果推断理论基础与常见建模方法
- AUUC、Qini 等离线评估指标应该怎么理解
- 在通用业务策略优化场景里,如何从实验设计一路走到线上策略落地
- 多 Treatment 与连续 Treatment 等扩展场景的建模思路
问题定义
相关性 ≠ 因果
“相关性不等于因果” 在数据分析里几乎是一句常识,但落到具体业务里,往往最容易被忽略。可以看几个经典例子。
- 冰淇淋与溺水事故
数据上看,冰淇淋销量和溺水事故数量往往高度正相关。但显然,禁止卖冰淇淋并不能减少溺水。真正的共同原因是气温:天气热时,人们更愿意吃冰淇淋,也更愿意去游泳。
- 教育年限与收入水平
教育年限更长的人通常收入也更高,但这并不自动意味着 “多读几年书” 一定会让整体收入同比例上升。因为 “能力”“家庭背景” 等因素,可能同时影响教育选择和收入结果。
- 收到优惠券的用户消费更高
这类结论在营销场景中极常见。但问题是,优惠券可能本来就是定向发给高价值用户的。于是 “收到券” 和 “高消费” 之间的关系,未必是优惠券造成的,而可能只是投放策略筛出来的相关性。
这几个例子背后,其实是同一个问题:业务需要的是 “干预带来了什么变化”,而不是 “干预和结果看起来一起出现了”。
传统预测的局限性
传统机器学习模型通常以预测结果 \(Y\) 为目标:
\[ \hat{Y} = f(X) \]
它擅长做的是:给定用户特征 \(X\),预测用户最终会不会发生某个行为。这在很多任务上是有效的,但一旦问题变成 “要不要对用户施加干预”,就会暴露出三个局限。
(1)高概率用户不等于高增量用户
假设我们要优化 “发券后购买” 的结果。传统模型通常会找出购买概率最高的人群,但这些人未必值得发券。
| 用户类型 | 不发券 | 发券后 | 是否值得干预 |
|---|---|---|---|
| 铁粉用户 | 会买 | 会买 | 不值得 |
| 可说服用户 | 不买 | 会买 | 值得 |
| 无望用户 | 不买 | 不买 | 不值得 |
| 反感用户 | 会买 | 不买 | 应避免 |
传统模型只能识别 “谁更可能买”,却无法区分这些人究竟是铁粉、可说服用户,还是反感用户。而真正值得投放资源的,往往只有第二类:因为干预才发生正向变化的人。
(2)无法分辨因果方向
在广告场景中,如果观察到 “看过广告的用户转化率更高”,这并不能说明广告提升了转化。也可能是本来就更容易转化的人,更容易被投到广告,或者更容易被系统分配到广告曝光机会。
(3)看不到反事实
做决策时,我们真正关心的是:
- 干预后会怎样
- 不干预会怎样
- 两者差多少
但传统预测模型通常只能看到一个已经发生的世界,而看不到 “如果当时不做这件事,会发生什么”。
而因果估计最关键的,恰恰就是这个反事实。
Uplift 在做什么
Uplift Modeling 关注的不是结果本身,而是干预带来的净变化。
对单个用户 \(i\) 来说,我们希望估计:
\[ \tau_i = Y_i(1) - Y_i(0) \]
其中:
- \(Y_i(1)\) 表示该用户接受干预(treatment)时的结果
- \(Y_i(0)\) 表示该用户不接受干预(treatment)时的结果
- \(\tau_i\) 表示干预对该用户造成的增量
于是,传统预测和 Uplift Modeling 的差别就很清晰了:
| 维度 | 传统预测模型 | Uplift Modeling |
|---|---|---|
| 核心问题 | 用户会不会转化? | 干预能不能让用户多转化? |
| 学习对象 | 结果概率 | 因果增量 |
| 识别目标 | 高概率用户 | 高增量用户 |
| 策略结果 | 可能浪费资源 | 更适合精细化投放 |
理论基础
潜在结果
从理论上看,Uplift 建模最常用的基础是因果推断里的潜在结果框架(Potential Outcomes Framework)。
对任意用户 \(i\),理论上都存在两个潜在结果:
- \(Y_i(1)\):接受干预后的结果
- \(Y_i(0)\):不接受干预时的结果
个体处理效应(ITE)定义为:
\[ \tau_i = Y_i(1) - Y_i(0) \]
但这里有一个经典困难:对同一个用户,我们永远不可能同时观察到 “既干预又不干预” 两种状态。这就是因果推断里的 Fundamental Problem of Causal Inference。
因此在实际中,我们通常不直接估计单个用户的真实 ITE,而是估计条件平均处理效应(CATE):
\[ \tau(x) = E[Y(1) - Y(0) \mid X = x] \]
也就是:在特征相似的人群里,干预平均会带来多大变化。这是大多数 Uplift 模型真正想学到的东西。
四类用户
从业务视角看,Uplift 最大的价值之一,是帮助我们把用户从 “按结果分层” 切换成 “按干预响应分层”。常见的四象限划分如下:
| 用户类型 | 干预后行为 | 不干预行为 | 干预效果 | 策略建议 |
|---|---|---|---|---|
| Persuadables | 正向 | 负向 | 正向 | 值得干预 |
| Sure Things | 正向 | 正向 | 接近 0 | 无需干预 |
| Lost Causes | 负向 | 负向 | 接近 0 | 无需干预 |
| Sleeping Dogs | 负向 | 正向 | 负向 | 避免干预 |
这里最值得关注的,是 Persuadables;最需要规避的,是 Sleeping Dogs。
很多业务策略表面上 “模型分高、投放更积极”,但如果高分用户里大量是 Sure Things,资源就会被浪费;如果误伤了 Sleeping Dogs,策略甚至会出现负收益。
三个假设
要让 uplift 估计具备可信度,通常至少依赖以下三个假设。
1. 无混淆性
\[ (Y(1), Y(0)) \perp T \mid X \]
也就是说,在给定特征 \(X\) 的前提下,干预分配 \(T\) 与潜在结果独立。
说人话就是:如果 treatment 是按线上策略定向施加的,而这个策略本身又和转化倾向强相关,就很容易引入混淆,导致我们分不清 “是 treatment 起作用”,还是 “被施加 treatment 的人本来就更容易转化”。
所以在 uplift 场景里,通常会通过 RCT 来尽量随机化 treatment assignment,从而降低混淆、提升可识别性。。
2. 重叠性
\[ 0 < P(T=1 \mid X=x) < 1 \]
即对任意一类用户,都应该有机会进入实验组或对照组。每个人群都得同时有 treatment 和 control 的样本,这样模型才能学得到相似人群施加 treatment 前后的效用的 diff 即 CATE
3. Stable Unit Treatment Value Assumption
一个用户的潜在结果,只受自己的干预状态影响,而不受其他用户干预状态影响。
大白话说就是用的某个用户的 treatment effect,应该只受到这个用户本身的 treatment 的影响
但如果别人的 treatment 也会影响他,那问题就变复杂了。因为这时他的结果不再只取决于 “我有没有被干预”,还取决于如下的可能因素:我朋友有没有被干预、别的商家有没有被补贴、同一个流量池里别人有没有被干预等等
实际业务中,如果用户之间有强社交传播、资源竞争或系统级联动,这个假设可能会被破坏。
比如说研究某个人打疫苗,能不能降低他感染风险?如果只有 “自己打没打” 在起作用,那比较简单。但现实里,别人打疫苗也会影响你:你周围很多人都打了 -> 病毒传播整体变弱了 -> 即使你没打,你感染风险也下降了. 这就是 SUTVA 不成立。
但实际上,SUTVA 在真实业务里常常不完全成立。因为很多业务天然就有联动:社交传播、资源竞争、库存约束等,以 LT 优化为例,不出某种体裁的内容会导致用户其他体裁的内容增加,那最终用户的 LT 变化其实是受这两种体裁的变化共同影响的
所以 SUTVA 往往不是 “完全成立” 或 “完全不成立”,而是:这个干扰强不强,能不能忽略。
如果干扰很弱,工程上可以近似接受;如果干扰很强,就要重新设计实验,比如说:
- 按群组随机而不是按个人随机,比如说对同一个好友圈的人同时发券,而不是一部分人发,一部分人不发
- 从” 按用户随机” 改成” 按时间随机”,即不要同一时刻一部分人开 treatment、一部分人不开;而是在某些时间段全量开,另一些时间段全量关
建模方法
Uplift Modeling 并没有唯一标准答案。工程上更常见的是两类方法:
- Meta-Learners:把因果效应估计拆成几个监督学习子问题。如常见的各种 xx-Learner
- Direct Uplift Models:直接围绕 treatment effect 设计模型或分裂准则。常见的是 Casual Froest 这一类方法
下面简单介绍
Meta-Learners
1. S-Learner
S-Learner 的思路最直接:把干预变量 \(T\) 当成一个普通特征,和其他用户特征一起喂给模型。
\[ \mu(x, t) = E[Y \mid X=x, T=t] \]
线上 serving 时,对同一个用户分别输入 \(t=1\) 和 \(t=0\),两次预测的差值就是 uplift 估计:
\[ \hat{\tau}(x) = \hat{\mu}(x, 1) - \hat{\mu}(x, 0) \]
优点:
- 实现简单
- 所有样本都用于训练一个模型
- 适合作为 baseline 快速验证
缺点:
- 如果 treatment 信号弱,模型容易忽略 \(T\)
- 在强正则下容易出现 regularization bias
如果只是想快速判断 uplift 方法在业务里有没有潜力,S-Learner 往往是很实用的起点;但如果真要追求更高质量的 CATE 估计,它通常不是终点。
2. T-Learner
T-Learner 的想法是把实验组和对照组彻底分开,分别训练两个模型:
\[ \mu_1(x) = E[Y \mid X=x, T=1] \]
\[ \mu_0(x) = E[Y \mid X=x, T=0] \]
两者差值就是 uplift:
\[ \hat{\tau}(x) = \hat{\mu}_1(x) - \hat{\mu}_0(x) \]
优点:
- 可以独立拟合干预组和对照组的不同模式
- 不容易像 S-Learner 一样把 treatment 信号 “抹平”
缺点:
- 每个模型只用到部分样本,样本利用率较低
- 样本不平衡时效果容易变差
- 两个模型误差会相互叠加
3. X-Learner
X-Learner 可以理解为在 T-Learner 的基础上,进一步提高样本利用效率,尤其适合 treatment / control 样本不平衡的场景。
它的核心步骤可以概括为三阶段:
3.1 训练两个响应模型
\[ \hat{\mu}_1(x) = E[Y \mid X=x, T=1] \]
\[ \hat{\mu}_0(x) = E[Y \mid X=x, T=0] \]
3.2 构造伪因果效应
对实验组样本:
\[ D_i^1 = Y_i^1 - \hat{\mu}_0(X_i) \]
对对照组样本:
\[ D_i^0 = \hat{\mu}_1(X_i) - Y_i^0 \]
再分别训练两个 effect model:
\[ \hat{\tau}_1(x) = E[D^1 \mid X=x] \]
\[ \hat{\tau}_0(x) = E[D^0 \mid X=x] \]
3.3 按倾向性得分加权组合
\[ \hat{\tau}(x) = g(x) \cdot \hat{\tau}_0(x) + (1-g(x)) \cdot \hat{\tau}_1(x) \]
其中 \(g(x)\) 通常取倾向性得分 \(P(T=1 \mid X=x)\)。
优点:
- 对样本不平衡更鲁棒
- 往往比 S-Learner、T-Learner 有更好的 CATE 精度
- 对业务中的非对称实验设计更友好
缺点:
- 实现与调参复杂度更高
- 训练链路更长,诊断难度更大
Direct Uplift Models
Direct Uplift Models 指的是直接围绕 treatment effect 设计分裂准则或损失函数的模型。常见的方法包括:
- Uplift Tree:决策树在 uplift 场景下的改造版,用 KL/欧式/卡方距离等准则分裂,目标是最大化 treatment 和 control 组的分布差异
- Causal Forest:Causal Tree 的集成版本,分裂准则更偏统计严谨(如 CMSE、SFT),常配合 honest estimation 使用
它们和普通决策树的本质区别在于:
- 普通树:分裂目标围绕预测误差或分类纯度
- Uplift 里的树:分裂目标围绕 treatment effect 的异质性
下面分开讲。
1. 普通决策树在分裂时在干什么
普通决策树(分类或回归)的分裂逻辑,本质上都是想让节点变得更” 纯”。常见准则有:
Gini 不纯度
\[ G = \sum_{k=1}^{K} p_k (1 - p_k) \]
其中 \(p_k\) 是节点中属于类别 \(k\) 的样本比例。Gini 越小,说明节点里类别越单一。
信息增益(基于熵)
\[ H = -\sum_{k=1}^{K} p_k \log p_k \]
分裂前后熵下降越多,说明这个切分把类别” 分得更开”。
回归树常用均方误差(MSE)
\[ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \bar{y})^2 \]
分裂目标是让左右子节点内的方差尽量小,预测更集中。
从上面按个指标可以看到普通决策树在分裂时只关心一件事:把结果相似的人分到一起。它压根不关心 treatment,也不关心” 干预和不干预的差异”。所以使用普通树预测” 发券后会不会买”,其实是在学” 谁更可能买”,而不是” 谁因为发券才更可能买”。
2. Uplift Tree 在分裂时在干什么
Uplift Tree 不再围绕” 结果纯度” 来分裂,而是围绕 ” 实验组和对照组之间的差异” 来分裂。
它的直觉是:如果一个切分能让左右两边的 treatment effect 明显不同,那这个特征大概率捕捉到了” 谁对干预更敏感”。
常见的分裂准则有:
KL 散度
\[ D_{KL}(P^T || P^C) = \sum_y P^T(y) \log \frac{P^T(y)}{P^C(y)} \]
欧式距离
\[ D_E = \sum_y (P^T(y) - P^C(y))^2 \]
卡方距离
\[ D_{\chi^2} = \sum_y \frac{(P^T(y) - P^C(y))^2}{P^C(y)} \]
这三个公式看着不同,但核心逻辑是一样的:
- \(P^T(y)\) 是当前候选节点内部,实验组在结果 \(y\) 上的分布
- \(P^C(y)\) 是当前候选节点内部,对照组在结果 \(y\) 上的分布
- 分裂目标是让这两个分布差异越大越好
这里的分布不是全局统计,而是节点内的经验分布。比如在二分类购买问题里:
- \(P^T(1)\) 表示 “当前节点中,实验组用户购买的比例”
- \(P^T(0)\) 表示 “当前节点中,实验组用户未购买的比例”
- \(P^C(1)\) 表示 “当前节点中,对照组用户购买的比例”
- \(P^C(0)\) 表示 “当前节点中,对照组用户未购买的比例”
为什么分布差异能反映 uplift?
这背后有一个关键的数学联系。对于二分类问题(如用户是否购买),uplift 定义为:
\[ \hat{\tau} = P^T(Y=1) - P^C(Y=1) \]
也就是说,uplift 本质上就是两个分布在 \(Y=1\) 这一点上的差值。
举个可以直接代入公式的例子。假设当前节点里有 200 个用户,其中:
- 实验组 100 人:30 人购买,70 人未购买
- 对照组 100 人:10 人购买,90 人未购买
那么:
\[ P^T(1)=0.3, \quad P^T(0)=0.7 \]
\[ P^C(1)=0.1, \quad P^C(0)=0.9 \]
于是这个节点的 uplift 就是:
\[ \hat{\tau} = P^T(1) - P^C(1) = 0.3 - 0.1 = 0.2 \]
也就是说,在这个节点里,干预让购买概率提升了 20 个百分点。
那 KL/Euclidean/Chi-square 距离和 uplift 有什么关系?以欧式距离为例:
\[ D_E = \sum_y (P^T(y) - P^C(y))^2 = (P^T(1) - P^C(1))^2 + (P^T(0) - P^C(0))^2 \]
把上面的数字代进去就是:
\[ D_E = (0.3 - 0.1)^2 + (0.7 - 0.9)^2 = 0.2^2 + (-0.2)^2 = 0.08 \]
由于 \(P(1) + P(0) = 1\),所以 \(P^T(1) - P^C(1) = -(P^T(0) - P^C(0))\),因此:
\[ D_E = 2 \times (P^T(1) - P^C(1))^2 = 2 \times \hat{\tau}^2 \]
在这个例子里也能直接看到:
\[ D_E = 2 \times 0.2^2 = 0.08 \]
因此,最大化欧式距离等价于最大化 uplift 的平方。
KL 散度和卡方距离可以理解为 uplift 的” 加权放大版”—— 它们不仅看差值大小,还考虑分布的相对位置。当 \(P^C\) 接近 0 或 1 时,相同的 uplift 会被赋予更大的权重。
所以这三个距离的共同逻辑是:当 \(P^T\) 和 \(P^C\) 差异大时,意味着 treatment 对结果有更强影响,即 uplift 绝对值更大。
但要注意,这里说的是单个节点内部的差异,还不是 “一个候选切分到底好不好”。真正选切分时,比较的不是左节点或右节点谁的 uplift 更大,而是:切分后左右子节点的加权得分,相比父节点提升了多少。
以二分类 + 欧式距离为例,节点分数可以写成:
\[ \phi(node)=D_E(node)=2\hat{\tau}_{node}^2 \]
如果一个候选切分把父节点分成左右两个子节点,那么它的 split gain 可以写成:
\[ \text{Gain}(s)=\frac{n_L}{n}\phi(L)+\frac{n_R}{n}\phi(R)-\phi(P) \]
把上面的 \(\phi(node)=2\hat{\tau}_{node}^2\) 代进去,可以得到:
\[ \text{Gain}(s) \propto \frac{n_L n_R}{n^2}(\hat{\tau}_L-\hat{\tau}_R)^2 \]
这说明:在这个设定下,真正被最大化的不是某个节点自己的 uplift,而是左右子节点 uplift 差异的平方。
所以更准确地说,Uplift Tree 在分裂时问的问题是:这个切分能不能把 “干预特别有用的人” 和 “干预基本没用的人” 分开,从而让左右子节点的 treatment effect 尽可能不同。
举个例子来说明。假设两个候选切分产生的左右子节点样本量接近,现在要判断哪个特征更适合作为分裂点。
候选特征 A 切分后:
| 分组 | 发券组购买率 | 不发券组购买率 | Uplift |
|---|---|---|---|
| 左边 | 30% | 10% | +20% |
| 右边 | 25% | 20% | +5% |
候选特征 B 切分后:
| 分组 | 发券组购买率 | 不发券组购买率 | Uplift |
|---|---|---|---|
| 左边 | 28% | 18% | +10% |
| 右边 | 27% | 17% | +10% |
特征 A 的左右 uplift 差异达到了 15%(20% - 5%),而特征 B 的左右 uplift 几乎一样(都是 10%)。如果左右样本量相近,那么 split gain 近似正比于 \((\hat{\tau}_L-\hat{\tau}_R)^2\),于是:
- 特征 A 的 split gain 更大,因为它真的把人群分成了 “对券敏感” 和 “对券不太敏感” 两类
- 特征 B 虽然两个子节点内部都存在正 uplift,但左右几乎没有差异,因此它没有真正把异质性切出来
所以 Uplift Tree 会偏好特征 A。它偏好的不是 “某个节点 uplift 尽量大”,而是 “这个切分之后,左右子节点的 uplift 尽量不一样”。
如果换成普通决策树,treatment 信息会被直接混进总体购买率里。这样即使某个切分明显拉开了 uplift,它也未必会被识别出来。比如上面两个切分只看总体购买率时:
- 特征 A 左边购买率:(30%+10%)/2 = 20%
- 特征 A 右边购买率:(25%+20%)/2 = 22.5%
- 特征 B 左边购买率:(28%+18%)/2 = 23%
- 特征 B 右边购买率:(27%+17%)/2 = 22%
这些总体购买率只能反映 “谁更容易买”,却不能直接回答 “谁更会因为发券而改变”。
一句话总结就是:普通树让节点里的结果更纯(谁更可能买);Uplift 树让左右子节点的 treatment effect 更不一样(谁更会被改变)
3. Causal Forest 在分裂时在干什么
Causal Forest 可以理解为 Causal Tree 的集成版本,也是很多真实业务里比较常用的一类方法。它的核心思想不是简单地” 给用户打分”,而是:对于目标用户 \(x\),自动找到一批和他在 treatment effect 上更相似的邻域样本,再在这个局部邻域里估计 CATE。
理论背景:CMSE 和 SFT
上面讨论的 KL / Euclidean / Chi-square,主要是在讲 Uplift Tree 这一路方法:它从 “实验组与对照组的结果分布差了多少” 这个角度来评价节点和切分。
但在另一条更偏统计学习的路线里 —— 也就是 Causal Tree / Causal Forest—— 研究者更关心的问题是:怎样让 treatment effect 的估计误差更小,而且这个差异是稳定可信的。 这就引出了下面两个理论视角:CMSE 和 SFT。
CMSE(Causal Mean Squared Error)
理论上,我们希望最小化因果效应估计的误差:
\[ \text{CMSE} = E\left[(\tau(X) - \hat{\tau}(X))^2\right] \]
其中 \(\tau(X)\) 是真实的 CATE,\(\hat{\tau}(X)\) 是模型估计值。
但问题是:真实的 \(\tau\) 无法观测,所以 CMSE 无法直接计算。它更像是一个理论目标,告诉我们 “理想情况下希望优化什么”,而实际算法必须用可计算的 proxy 去近似它。
一个常见的近似思路是:如果某个切分能让左右子节点的真实 treatment effect 明显不同,那么每个叶子内部的 treatment effect 往往会更一致。叶子内部越一致,用同一个 \(\hat{\tau}\) 去代表这个叶子的样本,误差通常就越小。
也就是说,CMSE 背后的直觉不是 “直接算误差”,而是:
尽量把 treatment effect 不同的人分到不同叶子里,让每个叶子内部更同质。
这可以用一个熟悉的方差分解来理解:
\[ \text {总方差} = \text {叶间方差} + \text {叶内方差} \]
在总方差给定时,如果切分让叶间差异变大,那么叶内差异通常会变小。叶内差异小,就意味着每个叶子里的真实 \(\tau\) 更一致,从而更有利于降低估计误差。
当然,这里要特别小心:上面这套逻辑是理论动机和近似直觉,不是说任何分裂准则都和 CMSE 严格等价。真正落到算法上,还需要选择一个可计算的切分目标。
SFT(Signal-to-Noise Ratio / 稳定性考虑)
仅仅看到 “左右子节点的效应差异大” 还不够,因为这个差异可能只是噪声。于是另一个自然问题是:
这个差异到底是异质性信号,还是小样本波动造成的假象?
这就是 SFT / 信噪比视角想回答的问题:不仅要看差异大不大,还要看这个差异稳不稳。
如果一个切分让左边 uplift = 30%,右边 uplift = 5%,但左边只有 10 个样本,那这个差异很可能并不可靠;如果左右都有足够样本,而且差异稳定复现,那么它更可能是真实异质性。
所以,CMSE 更强调 “估计误差要小”,SFT 更强调 “差异要稳定可信”。两者共同指向的是同一个目标:找到既有异质性、又能稳定估计的切分。
从统一目标到两类分裂准则
到这里可以把前后内容统一起来:不管是 Uplift Tree,还是 Causal Tree / Causal Forest,本质上都在做同一件事 —— 寻找 treatment effect 异质性最大的切分。只是它们给 “切分质量” 打分的方式不同。
1. Uplift Tree:从分布差异出发
Uplift Tree 更常见的做法,是先比较一个节点内实验组与对照组的结果分布差异,比如用 KL / Euclidean / Chi-square 距离打分。
在二分类场景下,如果用欧式距离作为节点分数,那么:
\[ \phi(node)=D_E(node)=2\hat{\tau}_{node}^2 \]
再把它写成 split gain:
\[ \text{Gain}(s)=\frac{n_L}{n}\phi(L)+\frac{n_R}{n}\phi(R)-\phi(P) \]
可以推出:
\[ \text{Gain}(s) \propto \frac{n_L n_R}{n^2}(\hat{\tau}_L-\hat{\tau}_R)^2 \]
这说明在二分类 + 欧式距离设定下,Uplift Tree 虽然表面上是在看 “节点里的分布差异”,但它最终偏好的,依然是左右子节点 treatment effect 差异大的切分。
2. Causal Tree / Causal Forest:从效应差异与估计误差出发
Causal Tree / Causal Forest 则更直接一些:它通常不先绕到分布距离,而是直接围绕 treatment effect 点估计 \(\hat{\tau}\) 及其稳定性来构造切分准则。
最直接的一类准则是:选择让左右子节点 treatment effect 差异最大的切分:
\[ \max_{j,s} \left( \hat{\tau}^{left}(j,s) - \hat{\tau}^{right}(j,s) \right)^2 \]
其中,在某一个节点内:
- 实验组平均结果是 \(\bar{Y}^T\)
- 对照组平均结果是 \(\bar{Y}^C\)
- 估计的 treatment effect 是 \(\hat{\tau} = \bar{Y}^T - \bar{Y}^C\)
这个准则的直觉很直接:如果一个切分让左右两边的 uplift 明显不一样(比如左边 15%,右边 -5%),那它就捕捉到了异质性。
在此基础上,还可以进一步把稳定性也纳入准则,例如使用类似 t-statistic 的形式:
\[ \frac{\left(\hat{\tau}^{left} - \hat{\tau}^{right}\right)^2}{\widehat{Var}(\hat{\tau}^{left}) + \widehat{Var}(\hat{\tau}^{right})} \]
这里分子是效应差异的平方,分母是估计方差之和。它在问的是:
左右 uplift 差这么多,到底是因为真的有异质性,还是因为样本太少、噪声太大?
这类方差调整后的准则,正好对应了前面提到的 SFT / 稳定性视角。
关键技巧:Honest Estimation
无论使用哪一类基于 \(\hat{\tau}\) 的切分准则,都会遇到一个共同问题:分裂时用的是估计值 \(\hat{\tau}\),不是真实的 \(\tau\)。如果同一批数据既用来找切分、又用来估叶子效应,模型就很容易偏好那些 “在这批数据上碰巧差异大” 的切分。
这就是为什么 Causal Tree / Causal Forest 通常会配合 Honest Estimation:
| 样本 | 用途 |
|---|---|
| 样本 A | 决定怎么切(找异质性结构) |
| 样本 B | 估计切完后的 treatment effect |
把切分和估计分开后,样本 B 负责做 “公正” 的叶子效应估计,可以显著降低过拟合偏误。更严格地说,这也是后续渐近正态性和置信区间推断的重要基础。
Uplift Tree 与 Causal Tree / Forest:到底是什么关系?
现在可以把前面几段放到一张图里理解:
- 共同目标:都在寻找 treatment effect 异质性最大的切分
- Uplift Tree 的角度:从实验组 / 对照组的结果分布差异出发
- Causal Tree / Forest 的角度:从 treatment effect 点估计及其估计误差出发
它们并不是完全相同的一套准则,只是服务于同一个目标的两条方法路线。
两者的联系在二分类问题里尤其明显:
\[ P^T(1) - P^C(1) = \hat{\tau} \]
所以在二分类场景下,“分布差异” 和 “uplift 差异” 本质上是在衡量同一件事;区别主要在于:前者更强调整个结果分布,后者更强调 treatment effect 点估计及其稳定性。
选择哪种方法?取决于业务需求:
- 需要考虑整个结果分布的变化 → Uplift Tree 的距离度量更全面
- 需要简洁的 uplift 点估计和置信区间 → Causal Tree / Forest 更直接
- 样本量有限、需要稳定性 → 带方差调整的 Causal Tree / Forest 准则更稳健
4. 小结:三种树的分裂目标对比
| 方法 | 分裂目标 | 通俗一句话 |
|---|---|---|
| 普通决策树 | 最小化预测误差或分类不纯度 | 把结果相似的人分到一起 |
| Uplift Tree | 最大化实验组 vs 对照组的分布差异 | 把 treatment effect 不同的人区分开 |
| Causal Tree / Forest | 最大化 treatment effect 异质性,同时控制估计误差 | 把 treatment effect 不一样的人分到一起,还要确信这个差异是靠谱的 |
更通俗地说,普通树学的是 “谁更像”,Uplift Tree 学的是 “谁更会被改变”,Causal Tree / Forest 学的是 “谁更会被改变,而且这个判断在统计上更站得住”。
在 uplift 场景中,相较于 uplift tree,Causal Forest 更常用一些,但两者各有适用场景
Causal Forest 的优势是
- 工程稳定性更强:单棵 Uplift Tree 容易过拟合、不稳定,Causal Forest 是集成方法,泛化能力更好
- 理论支撑更完善:Honest estimation 可以给出置信区间,渐近正态性支持统计推断
- 能捕捉更复杂的异质性:特征交互、非线性关系处理更强,适合特征多、关系复杂的业务场景
Uplift Tree 的优势是
- 需要规则解释:单棵树可以输出清晰的分裂规则,方便运营理解和执行,适合做人群切分洞察
- 快速原型验证:实现简单、训练快,可以快速判断 uplift 信号是否存在
- 规则引擎落地:有些业务系统需要 if-else 规则,Uplift Tree 可以直接转成规则
实际工程中的常见选择:
| 阶段 | 常用方法 | 原因 |
|---|---|---|
| 快速验证 uplift 是否存在 | S-Learner / Uplift Tree | 简单、快 |
| 追求 CATE 精度 | X-Learner / Causal Forest | 更鲁棒、理论支撑强 |
| 需要规则输出 | Uplift Tree | 解释性好 |
| 生产环境部署 | Causal Forest / Meta-Learner | 稳定性优先 |
一句话总结:Causal Forest 更适合作为” 主力模型”,因为它稳定、理论完善、工业界验证多;Uplift Tree 更适合作为” 辅助工具”,用来做规则洞察、人群切分、快速原型。
方法选择
如果把上面讨论的几类方法放在一起对比,大致可以这样理解:
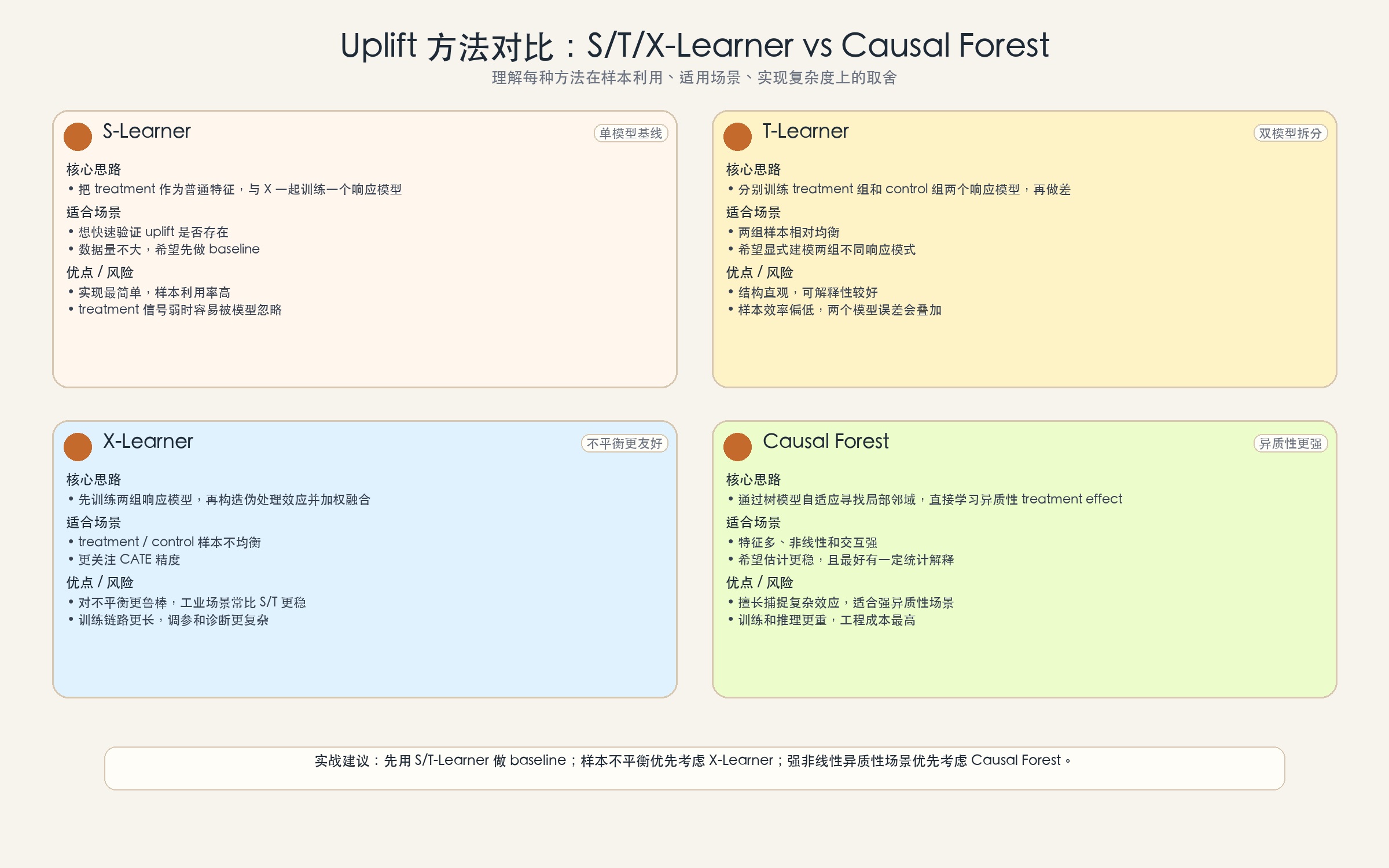
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| S-Learner | 快速验证、小数据 | 实现简单、样本利用率高 | 弱 treatment 时容易失效 |
| T-Learner | 样本均衡、效应较明显 | 结构直观 | 样本效率低、误差叠加 |
| X-Learner | 样本不平衡、追求精度 | 更鲁棒、效果通常更好 | 链路复杂 |
| Uplift Tree | 需要规则解释、人群切分 | 可解释性好 | 稳定性一般 |
| Causal Forest | 非线性强、希望估计更稳 | 理论支撑更强、能捕捉复杂效应 | 计算成本高 |
工程里没有银弹。很多时候,最好的方式不是一开始就追求最复杂模型,而是:
- 用简单 baseline 快速验证 uplift 是否真的存在
- 再逐步切到更强的 effect learner
- 最后把重心放在策略使用方式,而不是只盯着离线分数
评估指标
Uplift 的评估方式和普通分类 / 回归不同。原因很简单:真实的个体因果效应不可观测 —— 我们永远看不到” 同一个用户在干预和未干预两个世界里分别会怎样”。
所以,uplift 模型的评估重点通常不是” 单点预测准不准”,而是” 排序是否有效”—— 能不能把真正值得干预的用户排在前面。
类比分类任务:AUC 评估的是” 把正样本排在负样本前面” 的能力;uplift 任务类似,AUUC 评估的是” 把高 uplift 用户排在低 uplift 用户前面” 的能力。
在进入公式前,先统一口径:
- AUUC:按预测 uplift 从高到低排序后,uplift 曲线与横轴(0 增量线)之间的整块面积
- Qini 系数:uplift 曲线超出随机基线(高度 = ATE)的超额面积
二者都基于” 按预测 uplift 从高到低排序后” 的前缀累计曲线,只是参照系不同。本文这里采用的是 “前缀平均 uplift 曲线” 的定义,后文的 AUUC / Qini 关系都基于这一口径。
AUUC
想象有 1000 个用户,按模型预测的 uplift 从高到低排好队。
- 先只对前 10%(100 人)施加干预 —— 这批人里,实验组响应率比对照组高多少?差值就是这批人的平均 uplift。
- 再扩展到前 20%,重新算这 200 人的平均 uplift。
- 依此类推,一直扩展到 100%(全部 1000 人)。
把” 覆盖比例 → 这批人的平均 uplift” 画成曲线,就是 uplift 曲线。而 AUUC 就是这条曲线下的整块面积。严格来说,经验 uplift 曲线本质上是按排序前缀得到的一组离散点;图里通常按更细的分位点把这些点连成折线,样本量足够大时视觉上就近似成一条连续曲线。
如果模型排序有效,前面的人 uplift 高,后面的低,曲线会从左上角逐渐下降,最终收敛到 ATE(全体用户的平均处理效应)—— 覆盖到 100% 时,这批人就是所有人,平均 uplift 自然等于 ATE
公式化表达如下。
对前 \(k\) 个用户,实验组响应率和对照组响应率之差,就是这批人的平均 uplift 估计:
\[ \hat{\tau}_k = \frac{1}{N_k^T} \sum_{i \le k,\, T_i = 1} Y_i - \frac{1}{N_k^C} \sum_{i \le k,\, T_i = 0} Y_i \]
其中 \(T_i \in \{0,1\}\) 表示第 \(i\) 个样本属于实验组还是对照组,\(Y_i\) 是观测到的响应值,\(N_k^T, N_k^C\) 分别是前 \(k\) 个样本中实验组和对照组的样本数。
AUUC 就是这条曲线下面积的离散近似:
\[ AUUC = \int_0^1 U(p)\,dp \approx \frac{1}{N} \sum_{k=1}^{N} \hat{\tau}_k \]
要注意,这里求和的是 “各个前缀的平均 uplift”,不是对每个用户的预测 uplift 直接取均值。通俗理解就是,把每个覆盖比例下的平均 uplift 全加起来取均值。这个计算方式有个天然性质:排在前面的用户对 AUUC 的贡献权重更大,这恰好奖励了” 把高 uplift 用户排在前面” 的模型。
严格来说,若设第 \(j\) 位用户的真实效应为 \(\tau_{(j)}\),AUUC 可展开为加权和:
\[ AUUC = \sum_{j=1}^{N} w_j\,\tau_{(j)}, \qquad w_j = \frac{1}{N}\sum_{k=j}^{N}\frac{1}{k} \]
其中 \(w_1 > w_2 > \cdots > w_N\)(越靠前权重越大),由重排不等式可知 \(\tau_{(j)}\) 按降序排列时 AUUC 取最大值 —— 即完美排序下 AUUC 最高。
在本文采用的 “平均 uplift 曲线” 定义下,如果排序完全随机,任意” 前 \(k\) 人” 的构成和整体样本一致,平均 uplift 的期望就等于 ATE,因此:
\[ \mathbb{E}[AUUC_{rand}] = ATE \]
这意味着 AUUC 的绝对值本身受 ATE 影响:即使随机排序,AUUC 期望也等于 ATE;干预本身效果强的实验,AUUC 天然偏高,不代表模型排序更好。

关于这个指标还有一个工程细节,就是当实验组 / 对照组比例严重不均(如 9:1)时,某些分位点附近的估计因样本过少会出现明显抖动;更极端时,前缀内的 \(N_k^T\) 或 \(N_k^C\) 甚至可能非常小,导致简单均值差不稳定。常见处理方式包括:使用等分位数划分(确保每段都有足够的 T/C 样本)、对曲线做平滑处理,必要时使用 propensity reweighting / IPW 版本来降低不均衡带来的高方差。
Qini 系数
AUUC 的绝对值受 ATE 影响 —— 干预本身效果强的实验,AUUC 天然偏高,跨实验比较时容易产生误导。
Qini 系数换了一个参照系,回答的问题更直接:和随机策略相比,模型排序多带来了多少增量?
在本文采用的 “平均 uplift 曲线” 定义下,假设随机排序时的 uplift 曲线期望为 \(U_{rand}(p) = ATE\)(一条水平线),则 Qini 是模型曲线超出这条基线的面积:
\[ Qini = \int_0^1 \left(U(p) - U_{rand}(p)\right)dp = \int_0^1 \left(U(p) - ATE\right)dp \]
由于 \(\int_0^1 ATE\,dp = ATE\),Qini 系数和 AUUC 的关系很简洁:
\[ \boxed{Qini = AUUC - ATE} \]
Qini 就是 AUUC 扣掉随机策略本身贡献的那部分面积后剩下的,是真正靠模型排序额外” 赚” 到的增量。更直观理解如下
| 情况 | 曲线位置 | Qini |
|---|---|---|
| 模型比随机好 | 曲线整体在 ATE 基线上方 | 正值 |
| 模型和随机一样 | 曲线贴近 ATE 基线 | ≈ 0 |
| 模型比随机差 | 曲线整体在 ATE 基线下方 | 负值 |
随机排序时,Qini 的期望值为 0:
\[ \mathbb{E}[Qini_{rand}] = 0 \]

AUUC vs Qini:什么时候用哪个?
| 指标 | 参照系 | 面积含义 | 适合回答的问题 |
|---|---|---|---|
| AUUC | 横轴(0 增量线) | 模型 uplift 曲线下的绝对面积 | 整体策略能带来多大增量价值 |
| Qini | 随机基线(高度 = ATE) | 相对随机策略的超额面积 | 模型排序比随机好多少 |
选哪个?
- 关心绝对增量能力(评估整体策略价值)→ AUUC
- 关心模型好坏、跨实验比较(哪个模型排序更准)→ Qini 更合适,因为它已经剥离了 ATE 本身的贡献
- 两者通常一起看,结论方向一致
跨实验比较的注意事项
AUUC 和 Qini 都没有统一量纲,比较时要保持同一口径:
- 样本规模不同:10 万样本和 100 万样本的绝对值不可直接比较
- 标签定义不同:” 7 日付费率” 和” 7 日 GMV” 的 uplift 曲线量纲不同
- 业务口径不同:是否计入退款、是否过滤异常订单等,都会影响 uplift 计算
- 实验组占比不同:Qini 依赖随机基线,如果实验组 / 对照组比例差异大,可比性会下降
另一种常见画法:累计增益曲线
除了上面的” 平均 uplift 曲线”,工程中还有一种等价但形状相反的画法 —— 累计增益曲线(Cumulative Gain Curve),在 causalml、EconML 等工具库中较为常见。
区别只在 Y 轴的定义。把平均 uplift \(U(p)\) 乘以覆盖比例 \(p\),得到的就是前 \(p\) 比例用户带来的累计净增量:
\[ G(p) = p \cdot U(p) \]
由于 \(G(p)\) 从 0 开始随覆盖增加,曲线从左下角向右上方延伸。随机基线也不再是水平线,而是从原点到全量增益的斜线(\(G_{rand}(p) = p \cdot ATE\));两条线在 100% 覆盖处汇合于同一点(均等于 ATE)。

| 平均 uplift 曲线 | 累计增益曲线 | |
|---|---|---|
| Y 轴含义 | 前 k% 人的平均增量 \(U(p)\) | 前 k% 人带来的总增量 \(G(p) = p \cdot U(p)\) |
| 曲线方向 | 从左上到右下 | 从左下到右上 |
| 随机基线 | 水平线(高度 = ATE) | 斜线(\(p \cdot\) ATE) |
| Qini 面积 | 曲线与水平基线之间 | 曲线与斜线之间 |
两者包含完全相同的信息,选哪种是偏好问题。平均 uplift 曲线更直观体现” 排序是否有效”,累计增益曲线更直观呈现” 到底赚了多少”。本文采用前者,与文中公式口径一致。
实际优化落地案例
前面的内容主要讨论理论与方法。接下来把视角从模型本身拉回到更通用的策略优化框架。
无论是电商发券、广告激励、直播调控,还是推荐系统里的流量分发,本质上都在回答同一个问题:对这个用户施加某种干预,到底值不值得?
这类问题都可以抽象成一个统一的 gain-cost 权衡框架:
- Gain:干预后希望提升的核心业务价值
- Cost:干预带来的资源消耗、副作用或局部业务损失
方法本身并不依赖某个垂直场景,真正变化的只是不同业务下 gain 指标和 cost 指标的定义。
| 场景 | Treatment | Gain 指标 | Cost 指标 |
|---|---|---|---|
| 电商营销 | 发券、加补贴、提高触达频次 | 下单率、GMV、7 日 LT | 券成本、补贴消耗、毛利损失 |
| 广告投放 | 提高出价、增加曝光、发放激励 | 点击、转化、广告收入 | 流量占用、补贴成本、体验损耗 |
| 内容 / 直播分发 | 增减某类内容曝光、调整流量占比 | 留存、会话、时长、长期价值 | 子业务收入下滑、生态指标波动 |
如果只盯着单一 gain,很容易把策略做偏;只有把 gain 和 cost 同时纳入建模与决策,策略才真正有上线意义。
整体链路
一个完整的 uplift 策略链路,通常可以抽象为:
- 通过随机实验构造 treatment / control 数据
- 训练 uplift 模型,估计用户的增量收益与增量成本
- 在预算或约束条件下,把模型分转换成可执行决策
- 在线持续监控并动态更新策略

数据构造
RCT / Switchback 实验设计
实验形式并不唯一,常见的设计包括:
- 用户级随机实验:适合电商发券、广告激励等用户独立干预场景
- Switchback Experiment:适合供给、流量、时段级干预场景
- 分桶灰度实验:适合线上策略逐步放量验证
共同目标只有一个:让 treatment assignment 尽量随机,从而降低选择偏差,提升 uplift 估计的可信度。
做这类实验时,至少有三点要特别关注:
- 随机化是否真的均匀覆盖关键人群
- 实验期间是否有外部流量策略或业务活动干扰
- 样本量是否足够支撑异质性效应学习
很多 uplift 项目不是死在模型,而是死在实验设计不够干净
Feature 与 Label 设计
在一个通用的 uplift 项目里,特征通常会覆盖用户、行为和上下文等多类信息,例如:
| 特征类别 | 示例特征 | 业务含义 |
|---|---|---|
| 基础用户特征 | 年龄、性别、注册时长 | 用户基本属性 |
| 历史交易特征 | 下单次数、客单价、复购间隔 | 商业价值与购买习惯 |
| 广告交互特征 | 曝光、点击、转化、激励领取 | 广告敏感度 |
| 内容消费特征 | 时长、完播率、互动次数 | 内容偏好与注意力分布 |
| 价格敏感特征 | 价格带偏好、折扣使用率 | 对补贴和优惠的敏感程度 |
| 设备与环境特征 | 机型、网络、地域、时段 | 外部约束与场景差异 |
| 流量上下文特征 | 入口、版位、资源位竞争情况 | 当前供给环境 |
| 用户画像与分层 | 兴趣标签、价值层级、风险标签 | 用户分类 |
| 社交关系特征 | 关注、粉丝、互关、分享关系 | 社交传播潜力 |
| 趋势特征 | 7d / 30d 行为差值、比值、斜率 | 状态变化 |
这里有一个很重要的实践经验:Uplift 特征工程的重点,不只是提升 response prediction,而是尽量暴露 “谁对干预更敏感” 的异质性。因此,能体现趋势、状态切换、消费结构差异的特征,往往比静态画像更重要
在这个通用框架下,一般会建议把 label 拆成两类。
1、Gain Label
表示 “施加干预后,业务核心目标获得的增量收益”。
例如:
- 电商:7 日下单率、GMV、复购、长期价值
- 广告:点击率、转化率、广告收入、广告主 ROI
- 内容 / 直播:留存、有效会话、消费时长、长期活跃价值
2、Cost Label
表示 “施加干预后,需要付出的资源消耗或副作用”。
例如:
- 电商:优惠券成本、补贴消耗、毛利损失
- 广告:流量占用、补贴成本、用户体验下降
- 内容 / 直播:某子业务收入下降、供给生态波动、时长迁移损失
这一点很关键:很多策略只预测 gain,不预测 cost,最后上线时容易出现 “主指标提升了,但业务副作用太大” 的问题。把 gain 和 cost 拆开建模,本质上是在为后续约束优化做准备。
3、多 Label 场景
当我们优化目标有多个时,Label 往往也会有多个(比如说 LT 优化阶段 cost label,可能会同时影响时长和营收)。这个时候时候需要考虑如何将多个 label 合并成一个,方便模型的学习和后续规划问题的求解。常见做法是直接使用原始 label,并通过人工权重去对齐不同指标的量纲,如下所示:
\[ y = w_1 y_1 + w_2 y_2 + w_3 y_3 \]
但这种方式有几个明显问题:
- 超参数很难调
- 极端值影响大
- 一旦分布漂移,稳定性差
实际中一种更常用的方法是百分位归一化方案, 也就是用样本在训练集中的相对位置,替代原始值本身
\[ y = w_1 * \text{percentile\_rank}(y_1) + w_2 *\text{percentile\_rank}(y_2) + w_3 * \text{percentile\_rank}(y_3) \]
这么做的优点很明显:
- 通过 \(\text{percentile\_rank}\) 函数将原始量纲不一致的 label,都固定在特定范围内如
[0, 1],便于模型学习 - 不同的目标的兑换关系更可控,可通过让 \(w\) 的值保持一致,来让各目标的权重都保持一致,也可人工拍一个兑换关系,并且不容易收到不同目标的预估漂移的影响(如目标 A 统一高估 10 倍)
- 对极端值更鲁棒
- 更贴近后续排序型决策的使用方式
这也是一个很典型的工程取舍:真实业务中,很多时候不需要模型把绝对收益估得极准,而是更需要它把相对优先级排对。
模型选择与评估
如果要在多类业务场景里选择一个相对稳妥的异质性效应学习器,Causal Forest 往往是一个不错的起点,具体原因上面做模型横向对比分析时提过了,这里就不在赘述
离线评估指标这部分在前面也提到了。实际中,更值得关注的是训练集与测试集上的 AUUC、Qini 是否一致,以及不同分桶上的 uplift 排序是否稳定。
这里有两个经常出现、但容易被误读的现象:
1、稀疏 cost label 的 AUUC 绝对值可能很小
如果某个 cost 指标本身零值很多、分布非常稀疏,那么即使模型把排序做对了,AUUC 的绝对值也未必会特别大。这并不一定意味着模型无效,更可能只是标签本身的信息密度较低。
2、某些 cost 相关指标的 AUUC 可能为负
这通常出现在 “抑制型干预” 里,比如减少某类曝光、压缩某类补贴、降低某类流量占比。此时 treatment 的目标,本来就是牺牲局部指标去换取整体收益,所以 cost 维度出现负向 uplift,往往反而说明方向符合预期。
因此,评估 uplift 模型时,不应该孤立地看某一个 gain 或 cost 指标,而应该结合策略目标去理解其方向性和 trade-off。
线上决策
至此我们训练了两个模型,用来预估模型施加 treatment 前后的 \(\Delta \text{gain}\) 和 \(\Delta \text{cost}\)
但真正有业务价值的,不是简单给用户打一列 uplift 分,而是要在 Gain 与 Cost 之间做最优选择
最优化问题定义
首先我们可以很自然地定义如下的约束优化问题
设有 \(n\) 个用户,对用户 \(i\) 干预后:
- 业务收益预估值为 \(\text{gain}_i\)
- 业务损失预估值为 \(\text{cost}_i\)
定义决策变量:
\[ x_i \in \{0, 1\} \]
其中 \(x_i = 1\) 表示对用户施加干预。
如果预算或业务损失约束为 \(C\),优化目标可写成:
\[ \begin{aligned} \max_{x_i} \quad & \sum_{i=1}^{n} x_i \cdot \text{gain}_i \\ \text{s.t.} \quad & \sum_{i=1}^{n} x_i \cdot \text{cost}_i \le C \\ & x_i \in \{0, 1\} \end{aligned} \]
这其实就是 “在有限成本下,选出最值得干预的人”。
直接求解这个问题,可以构造如下拉格朗日函数:
\[ L(x, \lambda) = \sum_{i=1}^n x_i (\text{gain}_i - \lambda \cdot \text{cost}_i) + \lambda C \]
为了最大化 \(L\),对于每一个独立的 \(i\),我们的决策逻辑是:
- 如果 \((\text{gain}_i - \lambda \cdot \text{cost}_i) > 0\),即 \(\frac{\text{gain}_i}{\text{cost}_i} > \lambda\),则取 \(x_i = 1\)
- 如果 \(\frac{\text{gain}_i}{\text{cost}_i} < \lambda\),则取 \(x_i = 0\)
这里的 \(\lambda\) 可以理解为成本的影子价格。
这个结论很重要,因为它说明:在给定成本约束下,按单位成本收益(ROI)排序,本身是有优化基础的。
近似求解:贪心策略
直接套拉格朗日求解,工程上有两个不便:
- 需要一个明确的预算 \(C\),但在 cost 由多指标融合并经归一化后,\(C\) 已经丧失了物理含义(不像发券这类场景预算是显式的金额),只能凭分布拍一个数
- 求解依赖 gain 和 cost 的绝对值估准;而 uplift 模型的输出经过 label 归一化、样本选择偏差等处理后,绝对值常常存在系统性偏移。\(\lambda\) 一旦定死,模型若高估收益就会超支,若低估则预算结余
工程上更常用的是贪心策略:
- 计算每个用户的 \(\text{ROI}_i = \dfrac{\text{gain}_i}{\text{cost}_i}\)
- 按 ROI 从高到低排序
- 从前往后累加 cost,直到达到预算 \(C\) 或人数比例阈值
贪心和拉格朗日在解上是等价的:把人按 ROI 从高到低取,最后一个被选中用户的 ROI 就是隐式的最优影子价格 \(\lambda^\star\);前面所有 \(\text{ROI}_i > \lambda^\star\) 的用户都满足拉格朗日的最优性条件 \(\text{gain}_i - \lambda^\star\,\text{cost}_i > 0\)。换句话说,贪心是在用排序 + 累加,隐式地做对偶上升找到 \(\lambda^\star\),省掉了显式求解非线性方程。
贪心相较于显式拉格朗日求解的两个工程优势:
1. 对预估偏差更鲁棒
显式拉格朗日要求 gain / cost 的绝对值估得准,否则固定 \(\lambda\) 会导致超支或预算结余;而贪心只要相对排序对就行 —— 按人数 quantile 或动态预算池截断,无论分数怎么漂移,选出的都是当前最值得干预的那批。
2. 线上计算更高效
贪心退化为” 打分 + 排序 + 阈值对比”,可以离线 / 近线预计算,比在线解非线性方程快得多。
平滑 Treatment:从硬阈值到软强度
无论用拉格朗日还是贪心,前面得到的都是硬阈值决策:\(\text{ROI} > \lambda^\star\) 全干预,否则完全不干预。这种 0 / 1 决策在很多业务里是次优的,原因有两点:
1. 失去探索空间
如果 treatment 是” 不出某体裁” 这种强干预,对高 ROI 用户完全不出会让系统永远观察不到他们对该体裁的真实反馈,也就是永远丧失了对这部分用户的探索,这对业务提高渗透的目标来看是基本不太能接受的
2. 整数解会浪费预算
举个例子:预算 \(C = 2.5\),两个用户:
- 用户 A:\(\text{gain}=10\),\(\text{cost}=2\),\(\text{ROI}=5\)
- 用户 B:\(\text{gain}=8\),\(\text{cost}=2\),\(\text{ROI}=4\)
硬阈值(贪心或拉格朗日都一样):先选 A(cost = 2 ≤ 2.5),再考虑 B 时累计 cost 会变成 4 > 2.5,只能舍弃 B。最终 gain = 10,剩余 0.5 预算被浪费。
如果允许把 treatment 强度分摊(连续的 \(x_i \in [0,1]\),理解为概率或强度比例),把 1.5 的 cost 分给 A(强度 75%)、1 的 cost 分给 B(强度 50%),假设 gain 与 cost 等比例缩放,则总 gain = \(10 \times 0.75 + 8 \times 0.5 = 11.5 > 10\)。
LP 松弛的最优解形式
LP 松弛(Linear Programming Relaxation)是组合优化里最经典的近似求解套路之一 —— 把 \(x_i \in \{0,1\}\) 这种整数约束放松成 \(x_i \in [0,1]\),原问题变成线性规划,可以用 KKT / 单纯形法精确求解。
我们当前面临的问题是一个背包问题,而连续背包问题(fractional knapsack)的最优解就是按 ROI 排序的贪心解,这是个有严格证明的经典结论;0 / 1 背包的 LP 松弛最优解最多只有一个分数变量,和整数解的最优值差距有界
通过把整数约束 \(x_i \in \{0,1\}\) 放松为连续 \(x_i \in [0,1]\),对偶变量 \(\lambda \ge 0\) 对应预算约束。其 KKT 条件给出最优解如下:
\[ x_i^\star = \begin{cases} 1, & \text{ROI}_i > \lambda^\star \\ \in [0,1], & \text{ROI}_i = \lambda^\star \\ 0, & \text{ROI}_i < \lambda^\star \end{cases} \]
也就是 ROI 高于影子价格 \(\lambda^\star\) 的全开、低于的全关。这本身仍是阶跃函数,但提供了一个关键性质:最优 treatment 强度是 ROI 的单调不减函数。
LP 松弛在 uplift 这类预算约束问题里特别合适的几个原因:
- 解的结构清晰:上面的阶跃形式直接对应业务里” 按 ROI 排序后取 top-K” 的朴素直觉,模型分能直接转成可执行的策略
- 天然支持平滑:连续 \(x_i\) 本身可以解释成” 概率/强度”,工程上正好对应平滑 treatment(发券概率、推荐分加权、排序惩罚力度等),不像整数解那样需要额外做” 舍入到 0/1”
- 和贪心的等价关系:连续背包的 LP 解就是 ROI 排序贪心解,所以前一节的贪心策略本身就是 LP 松弛在背包结构下的精确解,不需要额外求解器
LP 最优解的固有性质:单调性
上面 KKT 形式已经隐含了”\(x_i^\star\) 关于 \(\text{ROI}_i\) 单调不减”,但这个性质并不依赖任何函数形式 —— 它是任何” 预算约束下连续分配” 问题最优解的固有性质,可以用 exchange argument(交换论证)严格证明。
考虑两个用户 \(i, j\)(\(\text{cost}_i, \text{cost}_j > 0\)),假设 \(\text{ROI}_i > \text{ROI}_j\),但反证地假定最优解里 \(x_i^\star < x_j^\star\)。我们做一个微小预算转移:从 \(j\) 收回 \(\varepsilon\) 单位 cost、转给 \(i\):
- \(x_j\) 减小 \(\dfrac{\varepsilon}{\text{cost}_j}\),释放出 \(\varepsilon\) 单位 cost
- \(x_i\) 增大 \(\dfrac{\varepsilon}{\text{cost}_i}\),消耗 \(\varepsilon\) 单位 cost
总 cost 不变,预算约束仍满足。目标函数的变化是:
\[ \Delta \text{Obj} = \frac{\varepsilon}{\text{cost}_i}\cdot\text{gain}_i - \frac{\varepsilon}{\text{cost}_j}\cdot\text{gain}_j = \varepsilon \cdot (\text{ROI}_i - \text{ROI}_j) > 0 \]
也就是说我们能严格提高目标值,与” 原方案最优” 矛盾。所以最优解必然有 \(x_i^\star \ge x_j^\star\)。
这个 exchange argument 不假设任何函数形式,得到的结论是个客观事实:只要预算可以连续分配、ROI 定义良好(cost > 0),最优分配就一定按 ROI 单调不减。连续背包、网络流分配、广告竞价都是同一个机制。
映射函数选择
KKT 的阶跃形式不能直接落地(不可导、无探索),工程上要找一个函数 \(f(\text{ROI})\) 来近似它,这个函数必须满足:
- 单调不减 —— 这是上面 exchange argument 强制要求的,否则就不是 LP 最优解的合法近似
- 平滑可导 —— 方便端到端训练、梯度优化
- 值域 \([0,1]\)—— 对应概率 / 强度的语义
- 在 \(\text{ROI} = \lambda^\star\) 附近过渡 —— 保留阶跃解的形态
满足这些条件的函数族很多:
| 函数族 | 形式 | 备注 |
|---|---|---|
| Sigmoid | \(\sigma\!\big(\alpha(\text{ROI} - \lambda^\star)\big)\) | 最常见;\(\alpha\) 控制陡峭度 |
| Hardsigmoid / 分段线性 | \(\text{clip}(\alpha(\text{ROI} - \lambda^\star) + 0.5,\,0,\,1)\) | 计算更便宜 |
| 任意单调分布 CDF | \(F(\text{ROI})\) | 概率解释更自然(如截断正态) |
| Softplus 复合 | \(1 - e^{-\text{softplus}(\alpha(\text{ROI}-\lambda^\star))}\) | 长尾控制更灵活 |
工程上选 sigmoid 主要是因为形式简单 + 处处可导 + 业务里好调参,并不是它在数学上” 更优”。换成其他单调平滑函数,结论同样成立。
最后我们可以看到,线上生效的往往是 “ROI 越高 → 惩罚越大” 的逻辑。
这在直觉上也讲得通:预算约束下” 边际收益高的人多分一点资源”——ROI 高意味着这个干预对该用户性价比高,自然该多分干预强度。这是约束优化下的资源分配定律,和拍卖里高出价者得到更多资源是同一回事。
因此,平滑映射在线上的优势往往是
1、保留探索空间,缓解反馈闭环
2、充分利用预算(避免整数约束的舍弃浪费)
3、不同用户分配不同强度,干预动作更精细
自适应分布
策略上线后,数据分布很可能发生变化。
常见问题包括:
1、Uplift ROI 分布漂移
解决思路是对分数再做归一化,把它映射到稳定区间 [a, b],从而让阈值与分位更可控。
2、业务指标长期右移或左移
比如客单价、转化价值、时长、广告出价等指标随着业务阶段变化持续右移或左移,这时模型分可能没问题,但决策阈值和预算映射会逐渐失真。
所以,uplift 策略上线之后,不能只看模型是否更新,还要持续看:
- 分数分布是否漂移
- 人群覆盖率是否异常
- gain / cost 比例是否变化
- 策略副作用是否扩大
反馈闭环陷阱
策略上线后,最容易踩的坑是直接用线上数据回训模型。这是 uplift 场景特有的、且比 CTR / CVR 严重得多的问题,值得单独说一下。
线上 uplift 策略上线后,干预分配不再随机:高分用户几乎都被干预,低分用户几乎都不干预。这直接破坏了 uplift 估计的两个关键前提:
- 重叠性:\(0 < P(T=1 \mid X=x) < 1\) → 高分人群几乎全是 \(T=1\),低分人群几乎全是 \(T=0\),重叠区域消失
- 无混淆性:\(T \perp (Y(1), Y(0)) \mid X\) → treatment 分配本身就是模型分的函数,混淆被引入
如果直接拿这批” 被策略选过的” 数据回训,模型会把策略本身的选择偏差当成” 因果效应” 学进去,下一轮分数更极端,干预更集中,偏差进一步放大 —— 经典的反馈闭环。
这个问题其实 CTR、CVR 也有,但是对 uplift 来说比 CTR / CVR 严重得多
| 维度 | CTR / CVR | Uplift |
|---|---|---|
| 学习目标 | \(P(Y \mid X)\),单一条件分布 | \(E[Y(1) - Y(0) \mid X]\),需要两个反事实分布 |
| 偏差类型 | 即使有曝光偏差,模型仍能学;表现为方差变大 | 重叠性破坏后直接不可识别,是 bias 不是 variance |
| 信号强度 | 标签密集、信号强 | uplift 是两个数相减,信号本身弱 1-2 个量级 |
| 误差累积 | 单向叠加在 \(P(Y \mid X)\) 上 | 双向叠加在 \(\hat{\mu}_1 - \hat{\mu}_0\) 上,且策略漂移会加速放大 |
直觉上:CTR 模型即使有选择偏差,至少还在学” 这群人会不会点”;uplift 模型一旦失去重叠性,学到的就根本不是因果效应了,而是策略选择规则本身。
工程上的常见修正手段有如下几种
| 方法 | 思路 | 代价 |
|---|---|---|
| 保留随机 holdout 桶 | 线上始终留 5%-10% 流量做随机分配,模型只用这部分回训或校准 | 牺牲一小部分线上收益,换持续可识别性。工业界最常用 |
| IPW(逆概率加权) | 用线上策略的实际分配概率 \(\hat{e}(x)\) 加权样本,纠正选择偏差 | 需要 \(\hat{e}(x)\) 远离 0 / 1,否则方差爆炸 |
| Doubly Robust | 同时用响应模型 + 倾向性得分,一方有偏另一方仍可补救 | 实现复杂,但鲁棒性最好 |
| 周期性全量 RCT | 定期暂停策略、做一次全量随机收集 | 短期业务波动较大,多用于早期或周期校准 |
实际工程里,holdout 随机桶是性价比最高的方案:它既维持了 RCT 的可识别性,又不用频繁暂停策略;同时 holdout 桶天然可以用来做模型 A / B 对比、Qini 曲线评估、阈值校准等多个用途。
最简单的只需要记住:uplift 模型的训练数据必须保持 treatment 分配的随机性,不能直接吃自己策略产出的数据,否则就是在自我强化偏差而不是学因果。
多 Treatment 与 连续 Treatment
前面讨论的内容主要围绕单一、二值的 treatment 展开。但实际业务中经常会遇到更复杂的形式:
- 多 Treatment:存在多种离散干预方式(如不同面额的优惠券、不同的广告创意)
- 连续 Treatment:干预存在强度 / 剂量差异(如折扣力度、补贴金额、曝光频次)
这两类场景在因果识别假设、建模方法和决策求解上都和二值场景有明显差异,下面分开讨论。
共同的因果识别假设
二值 treatment 的三个假设(无混淆性、重叠性、SUTVA)需要做对应扩展:
无混淆性:要求对所有 \(t\) 成立
\[\{Y(t)\}_{t \in \mathcal{T}} \;\perp\; T \;\big|\; X\]
也就是说,给定 \(X\) 之后,treatment 分配 \(T\) 与所有可能的潜在结果都独立。这通常要靠多臂 RCT(多 treatment)或剂量随机化(连续 treatment)来保证。
重叠性:扩展为对每个 \(t\) 都需要观测到样本
- 多 treatment:\(P(T=t \mid X=x) > 0, \quad \forall t \in \{0, 1, \dots, K\}\)
- 连续 treatment:条件密度 \(f_{T \mid X}(t \mid x) > 0, \quad \forall t \in \mathcal{T}\)
这一条在实际业务里最容易踩坑。比如某种 treatment 在线上策略里只发给特定人群,那么 \(P(T=t \mid X=x)\) 在其他人群里就是 0,模型在这部分人群上无法识别 \(\tau(x, t)\)。
广义倾向性得分(Generalized Propensity Score, GPS):是二值倾向性得分 \(P(T=1 \mid X)\) 的推广
- 多 treatment:\(e_t(x) = P(T=t \mid X=x)\),每个 \(t\) 一个
- 连续 treatment:\(e(t, x) = f_{T \mid X}(t \mid x)\),是条件密度
GPS 是后续 IPW、DR、加权回归等估计器的基础(Imbens 2000;Hirano & Imbens 2004)。
多 Treatment 场景
当存在多种干预选择时,问题从” 要不要干预” 变成了” 用哪种方式干预”。
问题定义
设有 \(K+1\) 种 treatment 取值 \(t \in \{0, 1, \dots, K\}\),其中 \(t=0\) 表示不干预。每种 treatment 对应一个潜在结果 \(Y_i(t)\),个体处理效应(相对不干预)为 \(\tau_i(t) = Y_i(t) - Y_i(0)\)。
由于 ITE \(\tau_i(t)\) 不可观测,实际建模目标是 CATE:
\[\tau(x, t) = E[Y(t) - Y(0) \mid X = x], \quad t \in \{1, \dots, K\}\]
最优 treatment 决策定义在 CATE 估计上:
\[\hat{t}^\star(x) = \arg\max_{t \in \{0, 1, \dots, K\}} \hat{\tau}(x, t)\]
其中 \(\hat{\tau}(x, 0) \equiv 0\)。
常见建模方法
1. One-vs-All (OVA)
把多 treatment 问题拆成 \(K\) 个二分类 uplift 子问题,每个子问题独立估计:
\[\hat{\tau}_k(x) = \hat{E}[Y(k) - Y(0) \mid X=x], \quad k=1,\dots,K\]
然后选择估计增量最大的 treatment:\(\hat{t}^\star(x) = \arg\max_k \hat{\tau}_k(x)\)。
优点是可以直接复用已有的二分类 uplift 模型。缺点比” 训练 \(K\) 个模型” 更深一层:
- 样本利用率低:训练 \(\hat{\tau}_k\) 时只用 treatment \(k\) 和 control 两组样本,其他 treatment 组的数据被丢弃
- 比较时偏差不可比(horse race bias):\(K\) 个独立模型各有不同方向、不同量级的偏差,做 argmax 时会被相对偏差污染 —— 某个 \(\hat{\tau}_k\) 系统性高估,就会被永远选中
- 不强制约束 \(\hat{\tau}(x, 0) = 0\)
2. Multivalued S-Learner
把 treatment 当作多值类别特征喂进单一模型:
\[\hat{\mu}(x, t) = \hat{E}[Y \mid X=x, T=t]\]
预测时枚举所有 \(t\),选 uplift 最大的:
\[\hat{t}^\star(x) = \arg\max_t \big(\hat{\mu}(x, t) - \hat{\mu}(x, 0)\big)\]
这是 S-Learner 的多值版本,需要 unconfoundedness 对所有 \(t\) 成立 + 重叠性扩展。优点是可以学到 treatment 间的共享结构,所有样本都参与训练;缺点继承自 S-Learner——treatment 信号可能被强正则” 抹平”。
3. Pairwise Comparison
对每对 \((j, k)\) 估计相对优势:
\[\hat{\tau}_{jk}(x) = \hat{E}[Y(j) - Y(k) \mid X=x]\]
需要 \(\binom{K+1}{2} = O(K^2)\) 个模型。综合 pairwise 结果可用 Borda count、Bradley-Terry 等。
主要风险是传递性破坏:可能出现 \(\hat{\tau}_{12} > 0\)、\(\hat{\tau}_{23} > 0\)、但 \(\hat{\tau}_{13} < 0\) 的环路(独立估计的不一致性)。所以 \(K \ge 4\) 时一般不直接用 pairwise。
4. DR-Learner / GPS 加权方法(更现代的做法)
直接对每个 treatment 构造 doubly robust 伪结果:
\[\tilde{Y}_i(t) = \hat{\mu}(X_i, t) + \frac{\mathbb{1}\{T_i=t\}}{\hat{e}_t(X_i)} \big(Y_i - \hat{\mu}(X_i, t)\big)\]
然后对 \(\tilde{Y}_i(t) - \tilde{Y}_i(0)\) 做回归得到 \(\hat{\tau}(x, t)\)。优势是只要 \(\hat{\mu}\) 和 \(\hat{e}_t\) 中有一个估准就能保证一致性,且样本利用率高于 OVA。Causal Forest、EconML 都提供了多 treatment 版本。
预算约束下的联合决策
更接近实际业务的问题是:在预算约束下,同时决定” 给谁干预” 和” 用哪种 treatment”。设决策变量 \(x_{it} \in \{0,1\}\) 表示是否对用户 \(i\) 施加 treatment \(t\)(\(t=0\) 表示不干预,\(\text{gain}_i(0) = \text{cost}_i(0) = 0\)):
\[ \begin{aligned} \max_{\{x_{it}\}} \quad & \sum_{i=1}^n \sum_{t=1}^K x_{it} \cdot \text{gain}_i(t) \\ \text{s.t.} \quad & \sum_{i=1}^n \sum_{t=1}^K x_{it} \cdot \text{cost}_i(t) \le C \\ & \sum_{t=0}^K x_{it} = 1, \quad \forall i \\ & x_{it} \in \{0, 1\} \end{aligned} \]
第二条约束限制每个用户最多选一种 treatment(包括” 不选”)。这是个多选择背包问题(Multiple Choice Knapsack Problem, MCKP),是 NP-hard 的。
实际中的近似贪心:
- 枚举所有 \((i, t)\) 对(\(t \ne 0\)),计算 \(\text{ROI}_{it} = \text{gain}_i(t) / \text{cost}_i(t)\)
- 按 ROI 全局降序排
- 依次选择,对每个用户只保留最先选中的那条(per-user dedup),直到累计 cost 达到 \(C\)
简单的” per-user argmax + global sort”(先给每个用户挑 ROI 最高的 treatment,再全局按用户排)在 MCKP 下不是最优 —— 它丢失了” 差一档 treatment 但 cost 更低” 的备选项。LP 松弛求 \(\lambda^\star\) 后,每个用户独立选 \(\arg\max_t (\text{gain}_i(t) - \lambda^\star \cdot \text{cost}_i(t))\),再二分搜 \(\lambda^\star\) 让总 cost 接近 \(C\),是更标准的解法。
连续 Treatment 场景
当 treatment 是” 做多少” 的连续变量时(折扣力度、出价、曝光频次),目标变成估计剂量 - 响应曲线(Dose-Response Curve, DRC)。
问题定义
Treatment \(t\) 取值在 \(\mathcal{T} \subseteq \mathbb{R}\)。在连续场景下 uplift 有两种合理定义:
绝对 uplift(相对不干预或基准剂量 \(t_0\))
\[\tau(x, t) = E[Y(t) - Y(t_0) \mid X = x]\]
适合” 开 / 不开” 或” 加 vs 不加” 型决策。
边际 uplift(剂量每增加一个单位带来的收益变化)
\[\partial_t \mu(x, t) = \frac{\partial}{\partial t} E[Y(t) \mid X = x]\]
适合做剂量优化、寻找最优拐点。
两者背后都是同一条 DRC \(\mu(x, t) = E[Y(t) \mid X=x]\),区别只是看积分还是导数。
常见建模方法
1. Dose-Response Network (DRNet, Schwab et al. 2020)
共享底层表示 + 多个 head 的神经网络结构:把剂量空间切成 \(M\) 个子区间 \([t_m, t_{m+1}]\),每个区间一个 head,所有 head 共享前几层 encoder:
\[\hat{\mu}(x, t) = \sum_{m=1}^M \mathbb{1}\{t \in [t_m, t_{m+1}]\} \cdot h_m(\phi(x), t)\]
共享 \(\phi(x)\) 让样本利用率比独立模型高得多;区间内 \(h_m(\cdot, t)\) 可以做线性 / 样条插值,避免边界跳跃。
2. 连续 Meta-Learners
把 Meta-Learner 框架扩展到连续 \(T\),常见做法包括:
- 把 \(t\) 作为输入特征的扩展 S-Learner \(\hat{\mu}(x, t) = f(x, t)\)
- 在每个剂量分位点上训练 T-Learner、再插值
- 连续 X-Learner(结合 GPS 加权)
预测时对 \(t\) 做网格搜索或梯度上升找最优剂量。
3. GPS 加权与 IPW 估计
用广义倾向性得分 \(\hat{e}(t, x) = \hat{f}_{T \mid X}(t \mid x)\) 做核加权 IPW 估计:
\[\hat{\mu}(x, t) = \frac{\sum_i K_h(t - T_i) \cdot \frac{1}{\hat{e}(T_i, X_i)} \cdot Y_i}{\sum_i K_h(t - T_i) \cdot \frac{1}{\hat{e}(T_i, X_i)}}\]
其中 \(K_h\) 是带宽 \(h\) 的核函数。直接 IPW 在密度估计偏小时方差爆炸,工程上常用:
- Stabilized weights:\(w_i = \hat{f}_T(T_i) / \hat{e}(T_i, X_i)\),分子是 \(T\) 的边际密度,能大幅控方差
- Weight clipping:把权重截在 \([0.01, 100]\) 之类的范围
- Doubly robust 版本(如 Kennedy et al. 2017 的 DR - DRC)
4. 现代神经网络方法
VCNet(Variational Counterfactual Networks)、SCIGAN 等专门为连续 treatment 设计的网络结构,进一步把表示学习和 GPS 调整结合起来,是近年研究的主流方向。
最优剂量选择
给定用户特征 \(x\),预算约束下的最优剂量是带 \(\lambda\) 的拉格朗日:
\[t^\star(x) = \arg\max_{t \in \mathcal{T}} \big(\text{gain}(x, t) - \lambda \cdot \text{cost}(x, t)\big)\]
在 \(t\) 连续可导时,一阶条件给出:
\[\partial_t \text{gain}(x, t) = \lambda \cdot \partial_t \text{cost}(x, t)\]
也就是边际收益等于影子价格乘以边际成本 —— 每多投一个单位剂量,带来的额外收益必须刚好抵得上付出的额外成本。\(\lambda\) 由全局预算约束 \(\int t^\star(x) \, dF(x) \le C\) 反解出来。
实操上常退化为网格搜索:
- 在 \(\mathcal{T}\) 上离散采样 \(\{t_1, \dots, t_M\}\)
- 对每个用户、每个 \(t_m\) 预测 \(\hat{\text{gain}}, \hat{\text{cost}}\)
- 取 \(\arg\max_m (\hat{\text{gain}}(x, t_m) - \lambda \cdot \hat{\text{cost}}(x, t_m))\)
- 二分搜 \(\lambda\) 让全局 cost 命中预算
注意这里不能简单用 ROI = gain / cost 排序:连续剂量下,最优解满足的是一阶条件(边际收益匹配边际成本),与 ROI 的最大化不等价。只有在 cost 是 \(t\) 的线性函数(即 \(\text{cost}(x,t) = c(x) \cdot t\))时,ROI 排序才与拉格朗日最优一致。
工程挑战
| 挑战 | 多 Treatment | 连续 Treatment |
|---|---|---|
| 因果识别 | 需要 unconfoundedness 对所有 \(t\) 成立;每个 \(t\) 都要满足重叠性 \(P(T=t\|X) > 0\) | 同上,且重叠性变成密度 \(f_{T\|X}(t\|x) > 0\),对密度估计要求高 |
| 实验设计 | 多臂 RCT 或分层 switchback;样本量随 \(K\) 线性增长 | 剂量随机化(如均匀采样剂量、或固定剂量集合 + 随机分配);密度需要足够覆盖 |
| 模型复杂度 | OVA 是 \(O(K)\),pairwise 是 \(O(K^2)\);联合建模可缓解 | 需要学连续函数;GPS 估计本身就是个非平凡的密度估计问题 |
| GPS 估计稳定性 | 离散 GPS 用多分类模型即可 | 条件密度估计(normalizing flow、kernel)容易在尾部不稳,需要 stabilized weights / clipping |
| 决策求解 | MCKP,NP-hard,靠 LP 松弛 + 二分 \(\lambda\) 近似 | 拉格朗日一阶条件 + 网格搜索;不能直接用 ROI 排序 |
| 反馈闭环 | 比二值更严重 —— 线上策略会让某些 \((X, t)\) 组合常年缺样本,重叠性持续退化 | 同上,且密度估计的偏差会被 IPW 放大 |
从工程角度看,这两类场景的落地难度明显高于二值 treatment。一个普遍做法是先用二值 RCT 验证 uplift 信号存在性、再扩展到多 / 连续 treatment,避免一上来就在最难的设定下踩多重坑。
总结与展望
Uplift Modeling 的核心,不是预测 “谁会转化”,而是估计 “干预会让谁发生净变化”。因此它解决的是一个更贴近业务决策的问题:在有限预算与副作用约束下,把干预资源留给最值得被影响的人。
围绕这个目标,本文依次讨论了以下几个问题:
第一,为什么传统预测只能回答相关性,无法回答反事实;
第二,潜在结果、CATE 以及无混淆性、重叠性、SUTVA 构成了 uplift 的因果基础;
第三,S/T/X-Learner、Uplift Tree、Causal Forest 分别对应不同的建模取舍;
第四,AUUC、Qini 与累计增益曲线用于评估排序是否有效;
第五,真正落地时还要把 gain-cost 建模、预算约束、平滑 treatment 与反馈闭环修正串成完整策略链路。
第六,多 Treatment 和连续 Treatment 的场景里,建模方法应该如何改进
也正因为如此,uplift 的难点往往不只在模型,而在实验设计是否干净、gain 与 cost 是否定义完整、线上策略是否保留探索,以及回训时能否避免选择偏差持续累积。模型只是中间环节,策略优化才是最终目标。
继续往后看,更值得深入的方向包括:网络效应下的因果识别、多 Treatment 与连续 Treatment 的联合决策,以及 uplift 与 contextual bandit、reinforcement learning 的结合。二值 uplift 往往只是起点,真实生产问题通常会更复杂。
如果后面继续展开,我更想单独写几块工程细节:AUUC / Qini 的实现坑点、Causal Forest / DR-Learner 的样本与特征设计,以及平滑 treatment 和随机 holdout 的线上用法。
参考文献
- Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies (Source). Journal of Educational Psychology, 66(5), 688–701.
- Künzel, S. R., Sekhon, J. S., Bickel, P. J., & Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning (PDF). Proceedings of the National Academy of Sciences, 116(10), 4156–4165.
- Wager, S., & Athey, S. (2018). Estimation and inference of heterogeneous treatment effects using random forests (PDF). Journal of the American Statistical Association, 113(523), 1228–1242.
- Athey, S., & Wager, S. (2019). Estimating treatment effects with causal forests: An application (PDF). Observational Studies, 5(2), 37–51.
- Athey, S., & Imbens, G. W. (2016). Recursive partitioning for heterogeneous causal effects (PDF). Proceedings of the National Academy of Sciences, 113(27), 7353–7360.
- Radcliffe, N. J., & Surry, P. D. (2011). Real-world uplift modelling with significance-based uplift trees (PDF). Stochastic Solutions White Paper TR-2011-1.
- Gutierrez, P., & Gérardy, J.-Y. (2017). Causal inference and uplift modelling: A review of the literature (PDF). In Proceedings of the 3rd International Conference on Predictive Applications and APIs (PMLR, Vol. 67, pp. 1–13).
- Hirano, K., & Imbens, G. W. (2004). The propensity score with continuous treatments (Source). In A. Gelman & X.-L. Meng (Eds.), Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives (pp. 73–84). Wiley.
- Kennedy, E. H., Ma, Z., McHugh, M. D., & Small, D. S. (2017). Non-parametric methods for doubly robust estimation of continuous treatment effects (PDF). Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(4), 1229–1245.
- Schwab, P., Linhardt, L., Bauer, S., Buhmann, J. M., & Karlen, W. (2020). Learning counterfactual representations for estimating individual dose-response curves (PDF). Proceedings of the AAAI Conference on Artificial Intelligence, 34(4), 5612–5619.